A-User Formation: Building the A-User
If Personality Alignment gives the A-User its style, A-User Formation AIM gives the A-User its body and its voice, the avatar and the speech for the A-User Control to embed in the metaverse. The A-User stops being an abstract brain controlling various types of processing and becomes a visible, interactive entity. It’s not just about projecting a face on a bot; it’s about creating a coherent representation that matches the personality, the context, and the expressive cues.
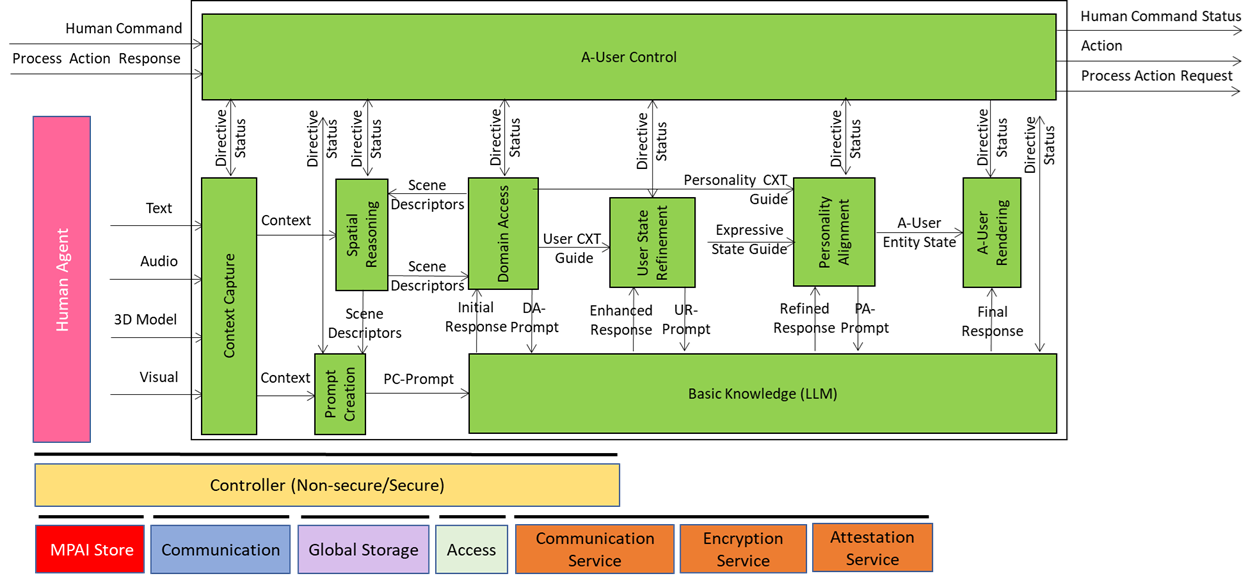
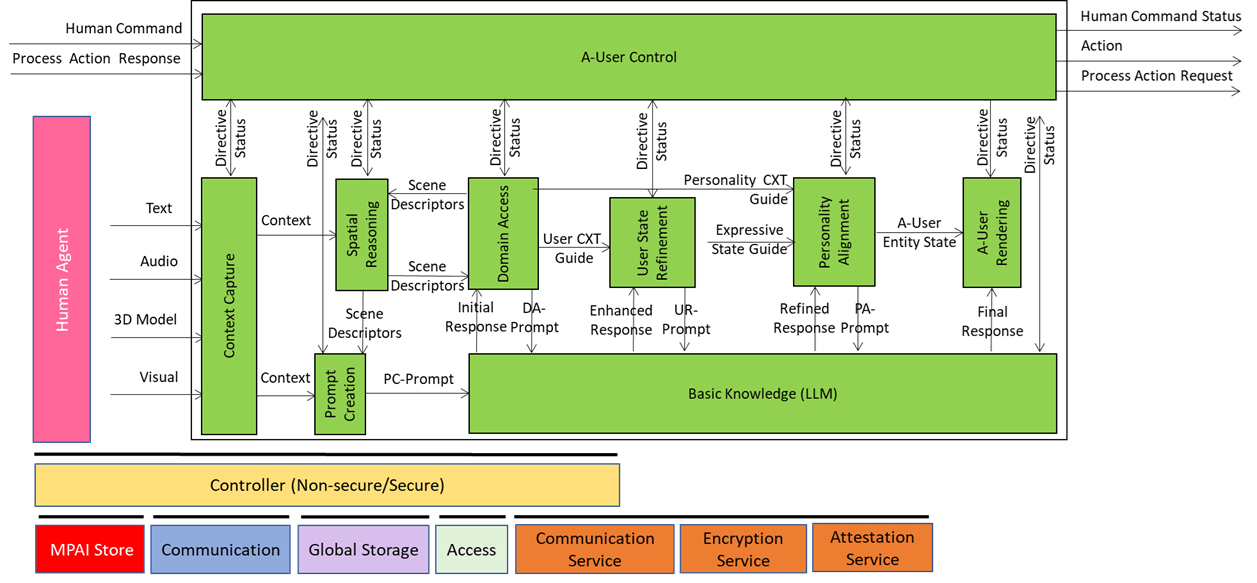
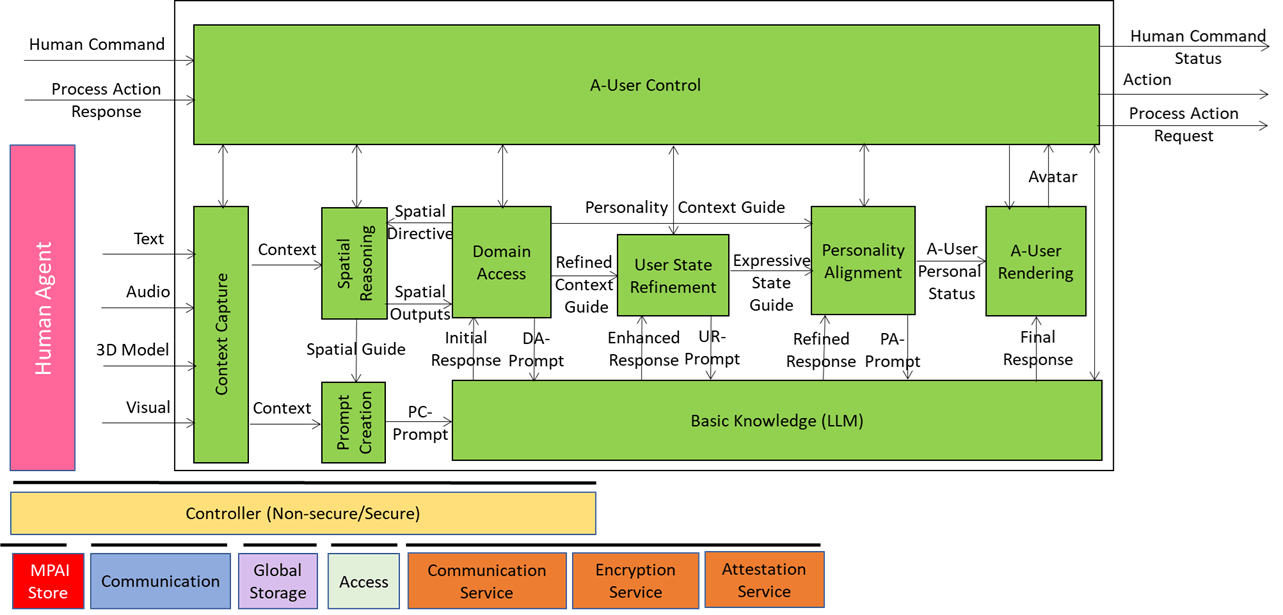
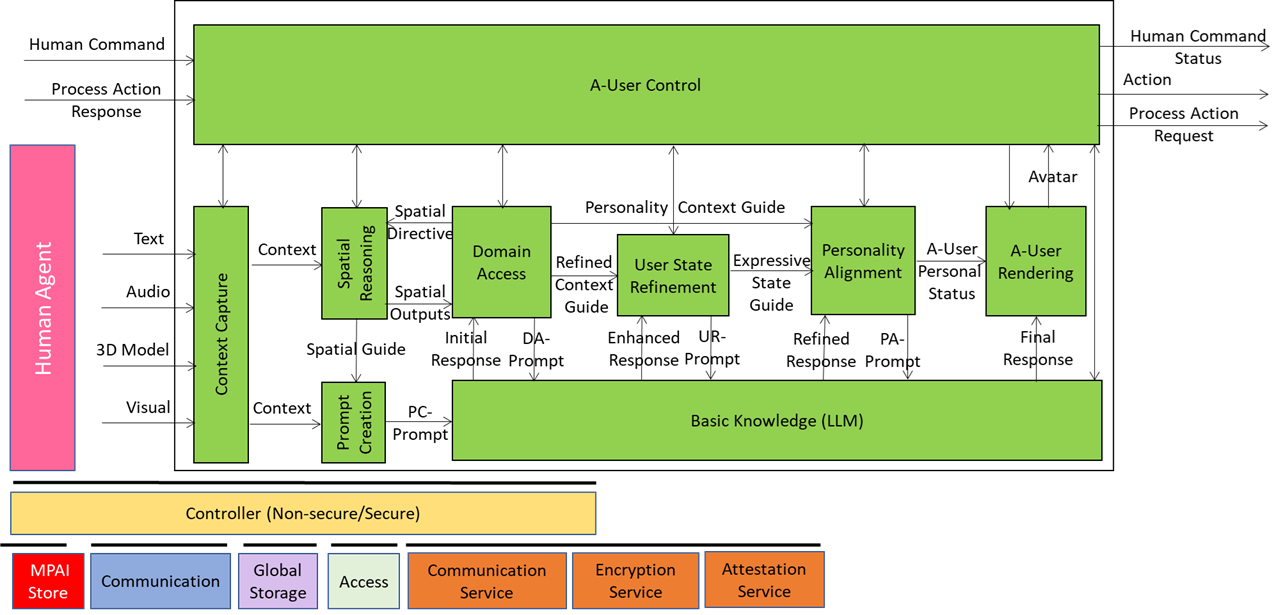
We have already presented the system diagram of the Autonomous User (A-User), an autonomous agent able to move and interact (walk, converse, do things, etc.) with another User in a metaverse. The latter User may be an A-User or be under the direct control of a human and is thus called a Human-User (H-User). The A-User acts as a “conversation partner in a metaverse interaction” with the User.
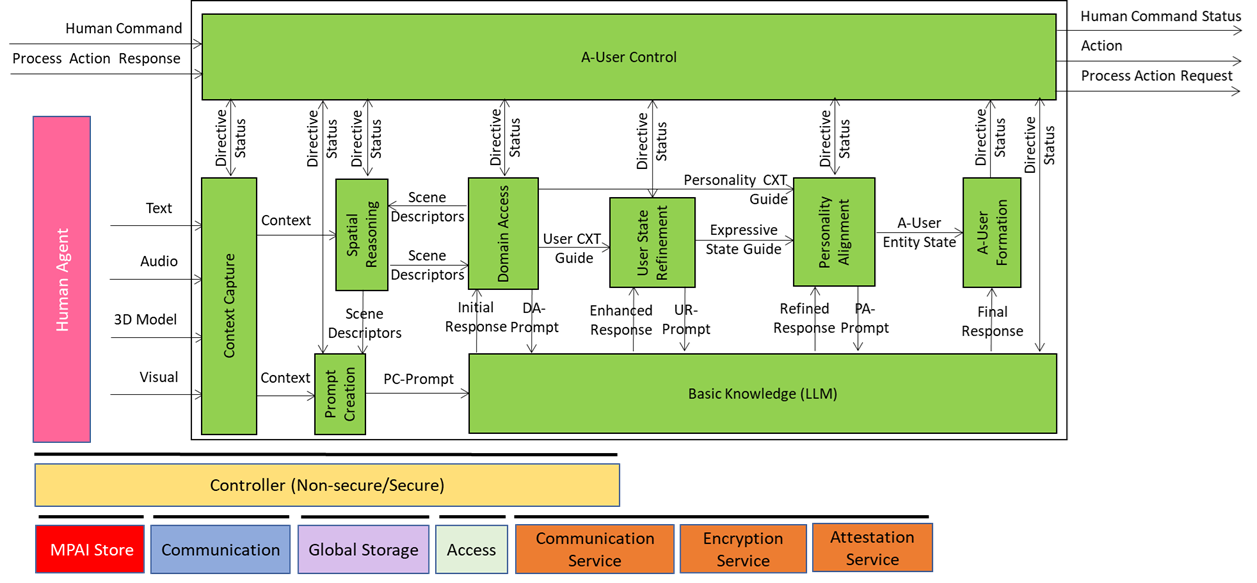
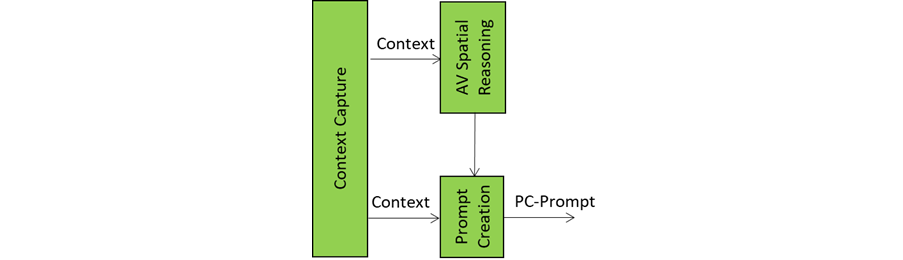
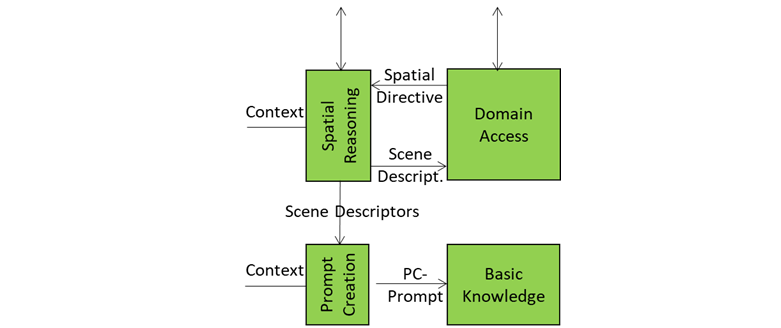
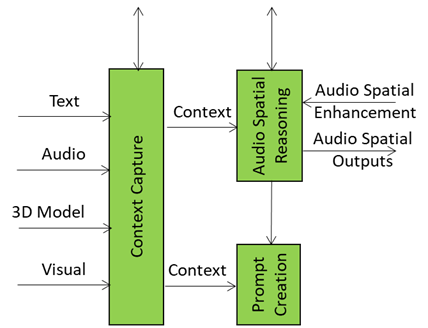
This is the tenth and last of a sequence of posts aiming to illustrate more in depth the architecture of an A-User and provide an easy entry point for those who wish to respond to the MPAI Call for Technology on Autonomous User Architecture. The first six dealt with 1) the Control performed by the A-User Control AI Module on the other components of the A-User; 2) how the A-User captures the external metaverse environment using the Context Capture AI Module; 3) listens, localises, and interprets sound not just as data, but as data having a spatially anchored meaning; 4) makes sense of what the Autonomous User sees by understanding objects’ geometry; relationships, and salience; 5) takes raw sensory input and the User State and turns them into a well‑formed prompt that Basic Knowledge can actually understand and respond to; 6) taps into domain-specific intelligence for deeper understanding of user utterances and operational context; 7) the core language model of the Autonomous User – the “knows-a-bit-of-everything” brain, the first responder to a prompt of a sequence of four; 8) converting a “blurry photo” of the User in the environment taken at the onset of the process into a focused picture; and 9) providing not only a generic bot but a character with intent, tone, and flair – not only a matter of what the avatar utters but how its words land, how the avatar moves, and how the whole interaction feels.
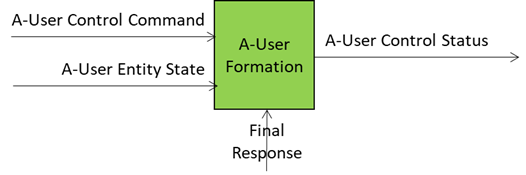
A-User Formation AIM gives the A-User a body and a voice, the results of a chain or AI Modules composing the A-User pipeline enabling a perceptible and coherent representation that matches the personality, the context, and the expressive cues.
The inputs driving A-User Formation are
- A-User Entity Status: The personality blueprint from Personality Alignment (tone, gestures, behavioural traits).
- Final Response: personality-tuned content from Basic Knowledge – what the avatar will utter.
- A-User Control Command: Directives for rendering and positioning in the metaverse (e.g., MM-Add, MM-Move).
- Rendering Parameters: Synchronisation cues for speech, facial expressions, and gestures.
What comes out of the box: Formation Status
- A multimodal representation of the A-User (Speaking Avatar) that talks, moves, and reacts in sync with the A-User’s intent – the best expression the A-User can give of itself in the circumstances.
- Structured report on the processing that led to the result.
What Makes A-User Formation Special?
It’s the last mile of the pipeline – the point where all upstream intelligence (context, reasoning, User’s Entity Status estimation, personality) becomes visible and interactive. A-User Formation ensures:
- Expressive Coherence: Speech, gestures, and facial cues match the chosen personality.
- Contextual Fit: Avatar appearance and behaviour align with domain norms (e.g., formal in a medical setting, casual in a social lounge).
- Technical Precision: Synchronisation across Personal Status modalities for natural and consistent interaction.
Key Points to Take Away about A-User Formation
- Purpose: Turns the A-User’s personality and reasoning into a visible and audible interactive avatar.
- Inputs: Personality-aligned final response, control commands, and rendering parameters.
- Outputs: Speaking avatar, formation status.
- Goal: Deliver a coherent, expressive, and context-aware representation that feels natural and engaging in response to how the User was perceived at the beginning and processed during the pipeline.