MPAI releases the MPAI Metaverse Model as Open-Source Software
Geneva, Switzerland – 19th February 2025. MPAI – Moving Picture, Audio and Data Coding by Artificial Intelligence – the international, non-profit, unaffiliated organisation developing AI-based data coding standards – has concluded its 53rd General Assembly (MPAI-53) releasing the first version of the MPAI Metaverse Model Open-Source Reference Software and kicking off the new project Compression and Understanding of Industrial Data (MPAI-CUI) – Company Performance Prediction (CUI-CPP) V2.0.
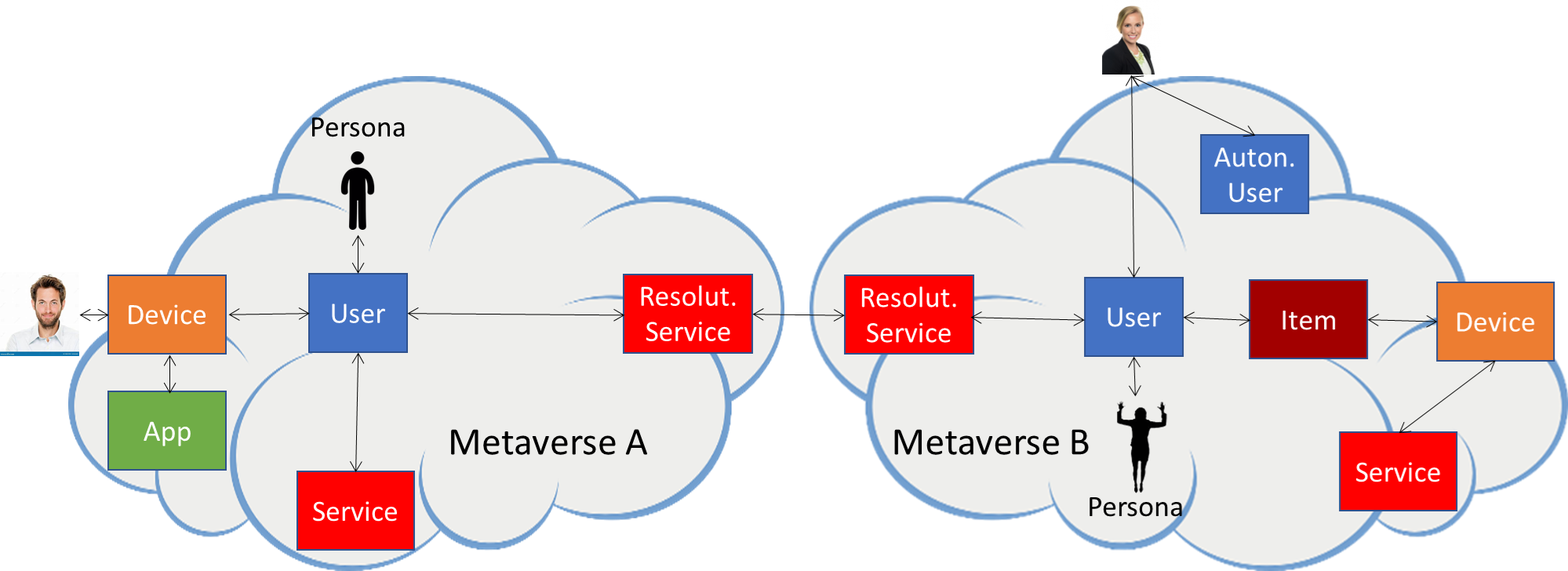
MPAI has been working on MPAI Metaverse Model (MPAI-MMM) standards since January 2022 and published Two technical Reports and two Technical Specifications on Architecture and Technologies. The Reference Software released today implements a significant number of the MMM functionalities and uses a set of Unity instances to realise the different environments of the metaverse instance. You can find the MMM software at http://bit.ly/41J0wsj (REST API web server) and https://bit.ly/4ituw0R (Unity web server).
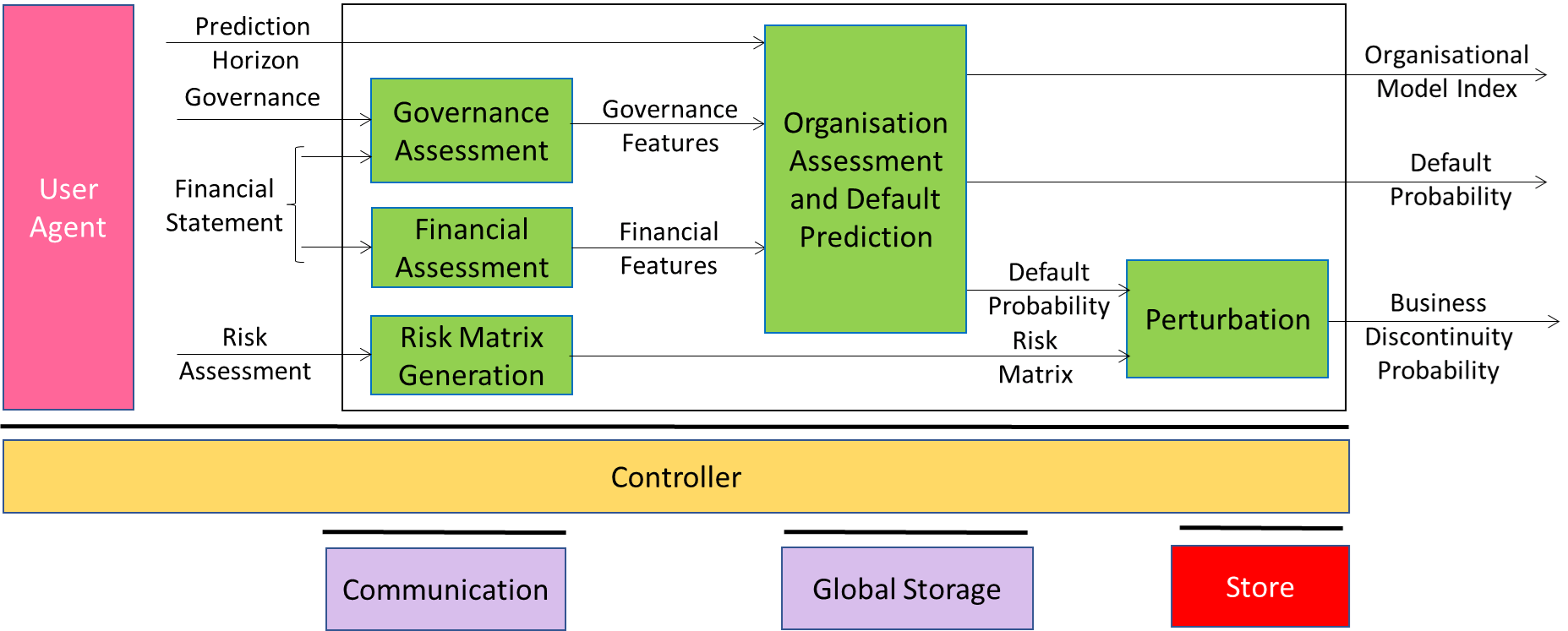
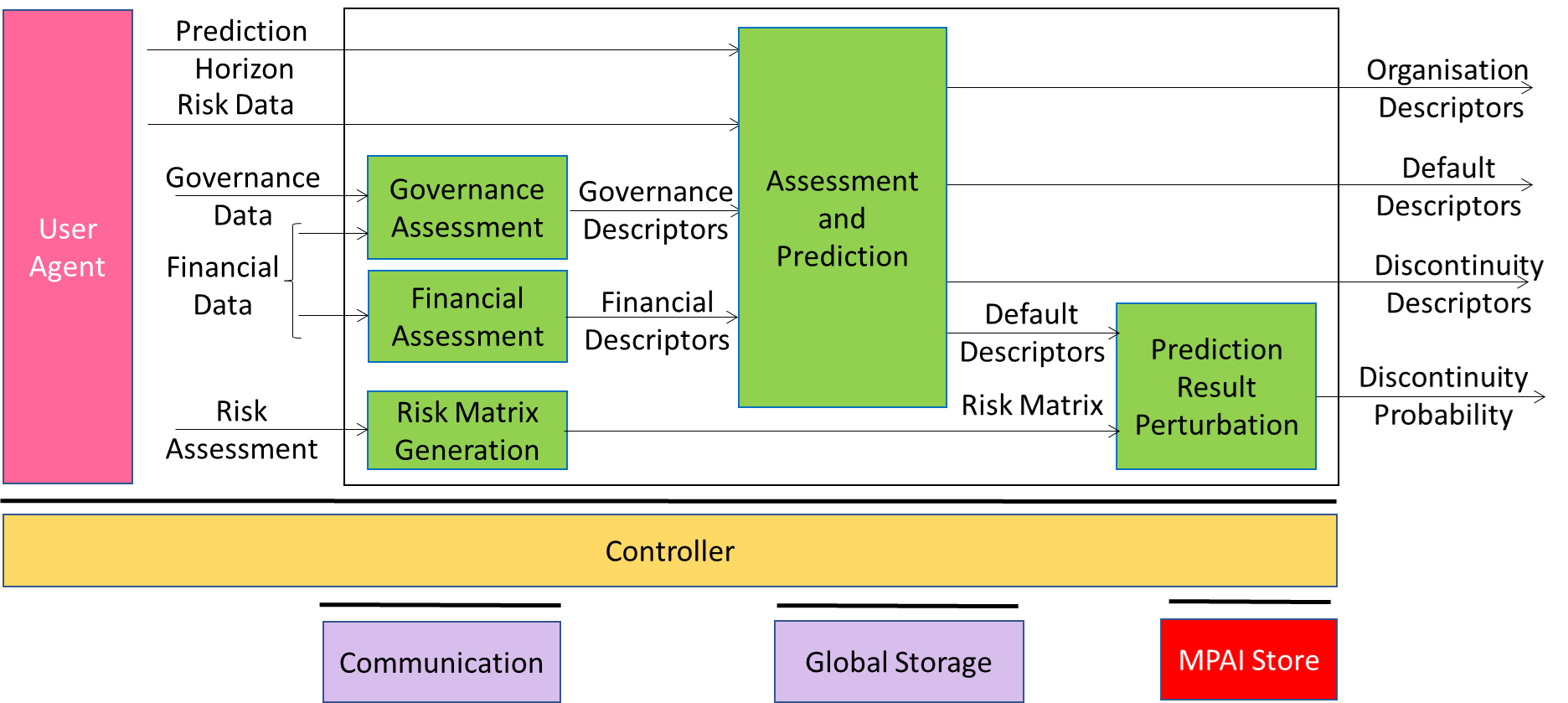
The Company Performance Prediction (CUI-CPP) project intends to provide a solution to a problem afflicting all companies: given the governance structure and the financial situation of a company and various types of risks that may affect it, what is the impact of the components of the governance structure on the governance, finance, and risk on the probability of default? MPAI has developed a set of functional requirements and a framework licence. A Call for Technologies was published and the standard will be collaboratively developed based on the responses to the Call.
MPAI is continuing its work plan that involves the following activities:
- AI Framework (MPAI-AIF): building a community of MPAI-AIF-based implementers.
- AI for Health (MPAI-AIH): developing the specification of a system enabling clients to improve models processing health data and federated learning to share the training.
- Context-based Audio Enhancement (CAE-DC): developing the Audio Six Degrees of Freedom (CAE-6DF) standard.
- Connected Aonomous Vehicle (MPAI-CAV): updating the MPAI-CAV Architecture part and developing the new MPAI-CAV Technologies (CAV-TEC) part of the standard.
- Compression and Understanding of Industrial Data (MPAI-CUI): developing Company Performance Prediction standard V2.0.
- End-to-End Video Coding (MPAI-EEV): exploring the potential of video coding using AI-based End-to-End Video coding.
- AI-Enhanced Video Coding (MPAI-EVC): waiting for responses to the Call for Technologies for video up-sampling filter on 11 February.
- Governance of the MPAI Ecosystem (MPAI-GME): working on version 2.0 of the Specification.
- Human and Machine Communication (MPAI-HMC): developing reference software and performance assessment.
- Multimodal Conversation (MPAI-MMC): Developing technologies for more Natural-Language-based user interfaces capable of handling more complex questions.
- MPAI Metaverse Model (MPAI-MMM): extending the MPAI-MMM specs to support more applications.
- Neural Network Watermarking (MPAI-NNW): studying the use of fingerprinting as a technology for neural network traceability.
- Object and Scene Description (MPAI-PAF): studying applications requiring more space-time handling applications.
- Portable Avatar Format (MPAI-PAF): studying more applications using digital humans needing new technologies.
- AI Module Profiles (MPAI-PRF): specifying which features AI Workflow or more AI Modules need to support.
- Server-based Predictive Multiplayer Gaming (MPAI-SPG): exploring new standard opportunities in the domain.
- Data Types, Formats, and Attribes (MPAI-TFA) extending the standard to data types used by MPAI standards (e.g., aomotive and health).
- XR Venues (MPAI-XRV): developing the standard for improved development and execion of Live Theatrical Performances and studying the prospects of Collaborative Immersive Laboratories.
Legal entities and representatives of academic departments supporting the MPAI mission and able to contribute to the development of standards for the efficient use of data can become MPAI members.
Please visit the MPAI website, contact the MPAI secretariat for specific information, subscribe to the MPAI Newsletter and follow MPAI on social media: LinkedIn, Twitter, Facebook, Instagram, and YouTube.
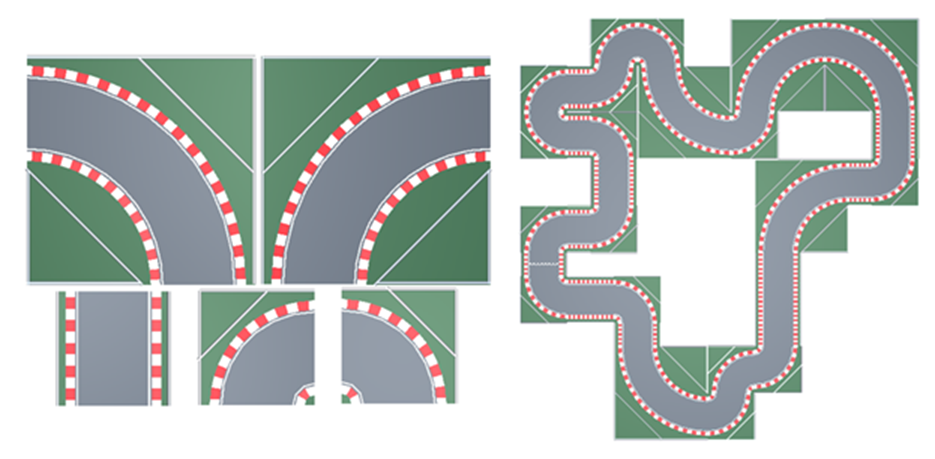
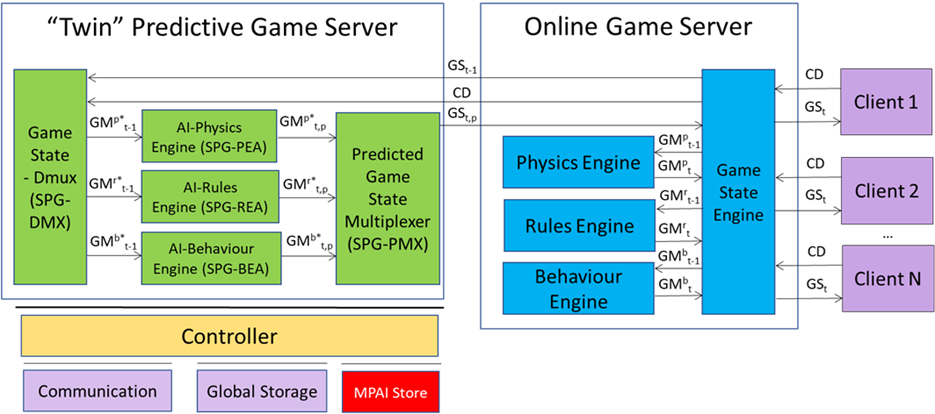
 Figure 2 – Modular tiles and an example of a racetrack
Figure 2 – Modular tiles and an example of a racetrack