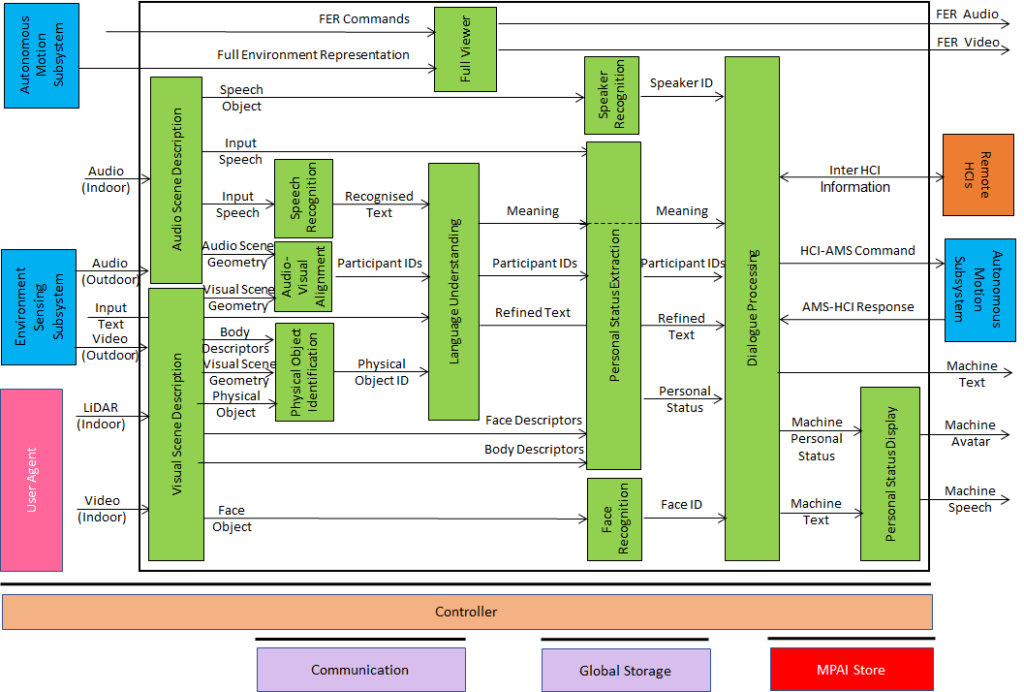
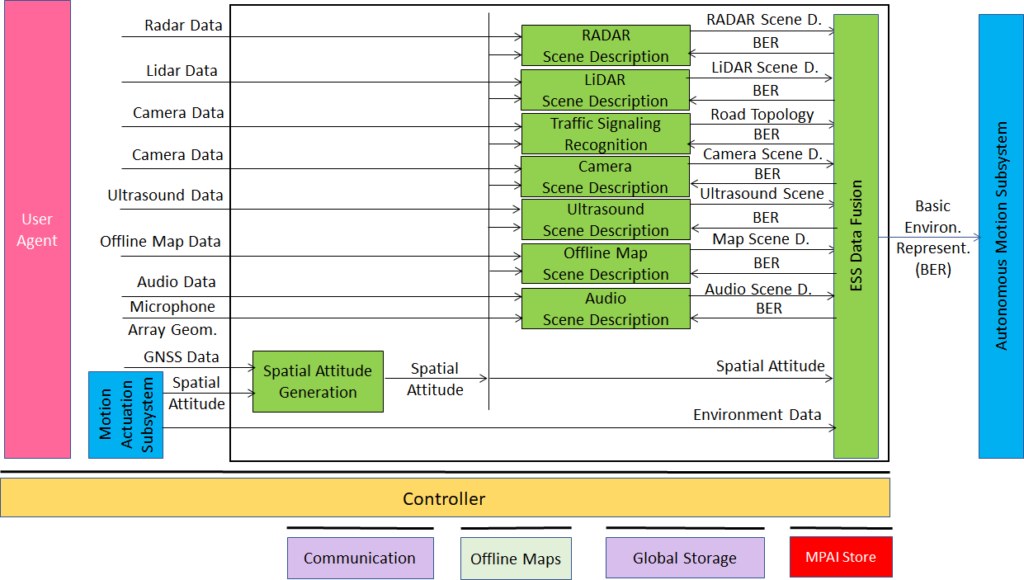
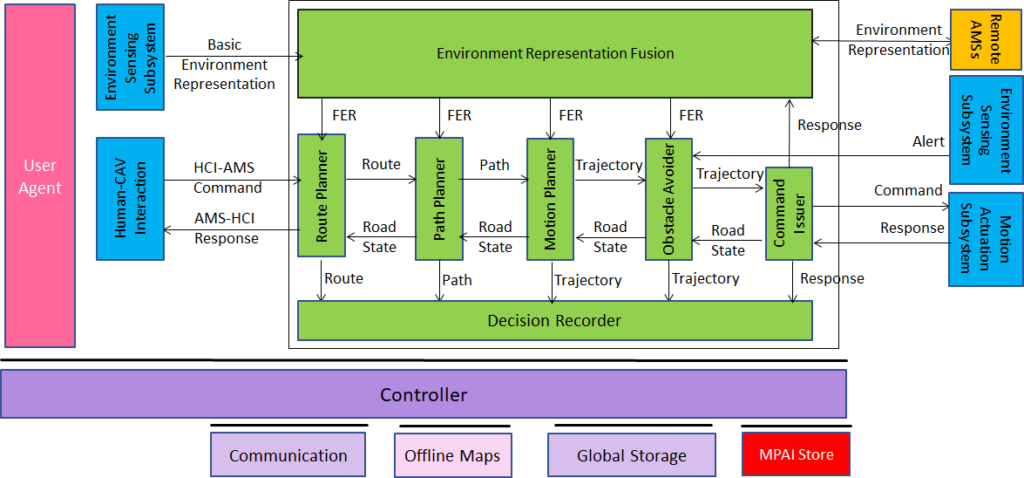
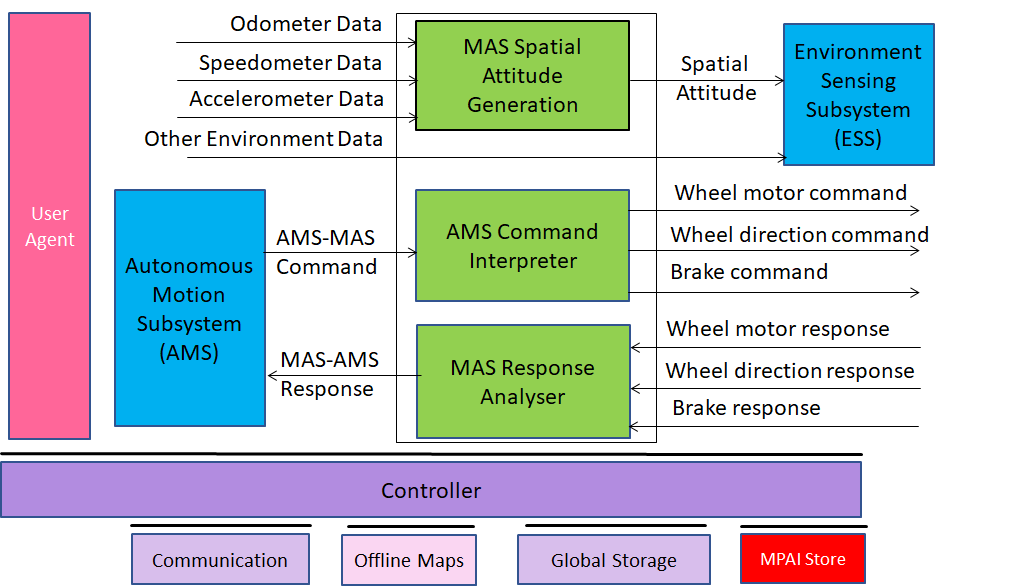
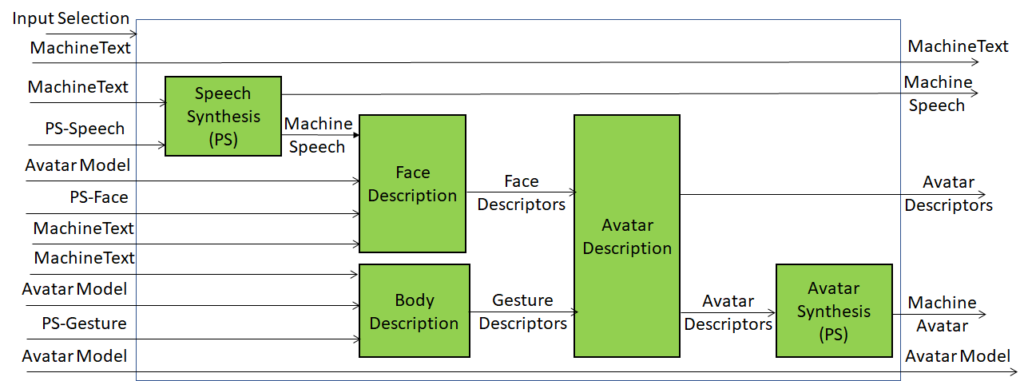
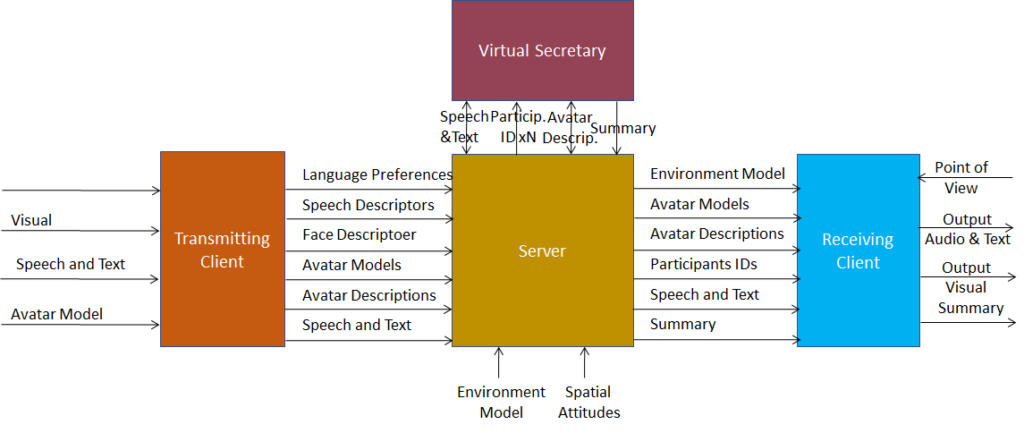
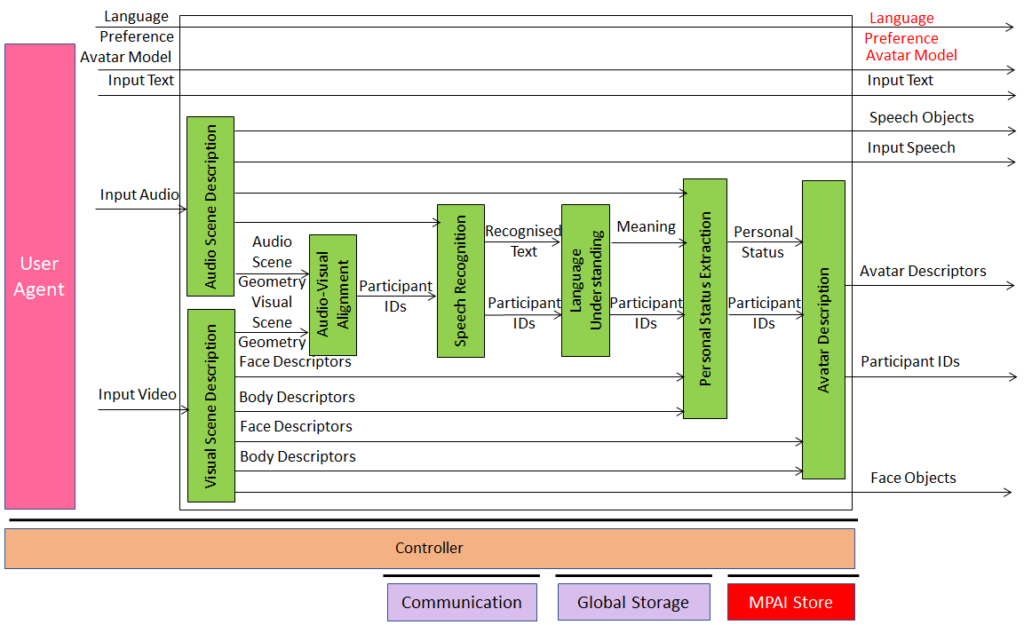
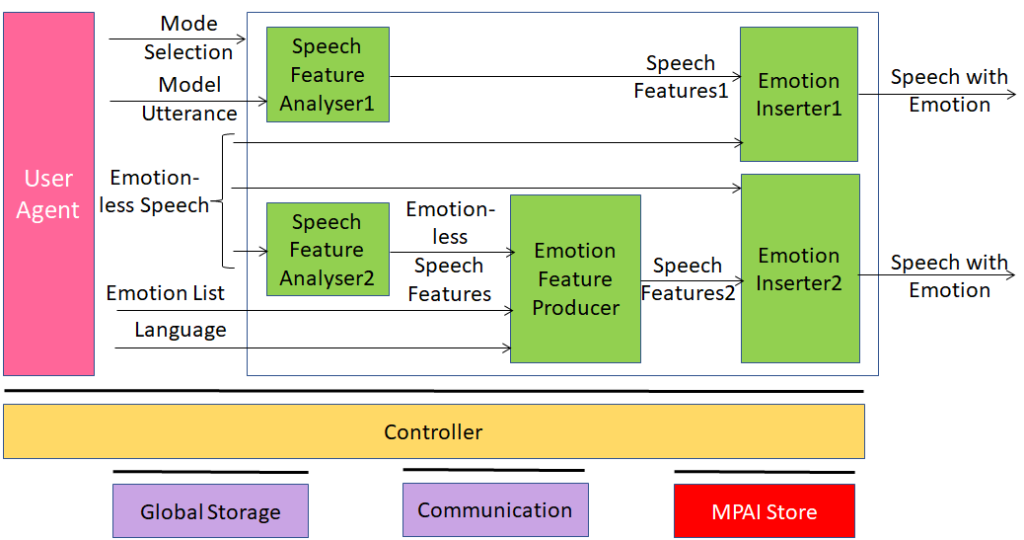
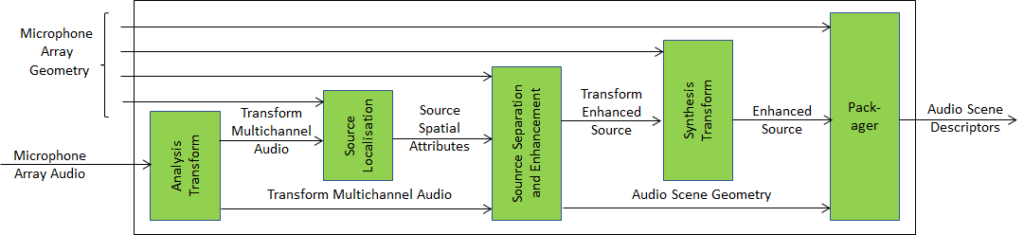
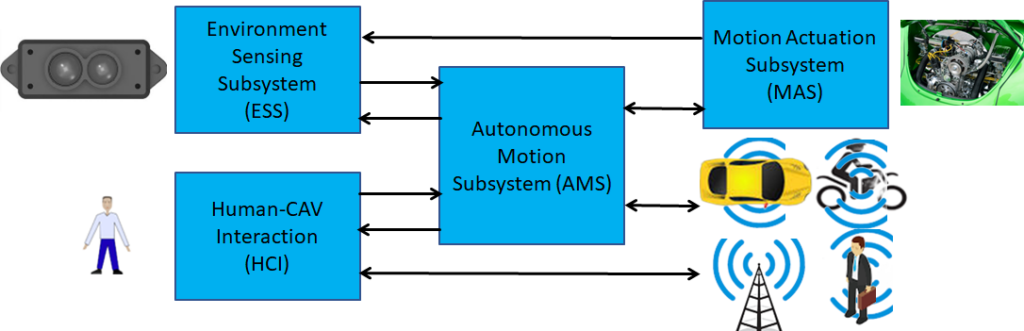
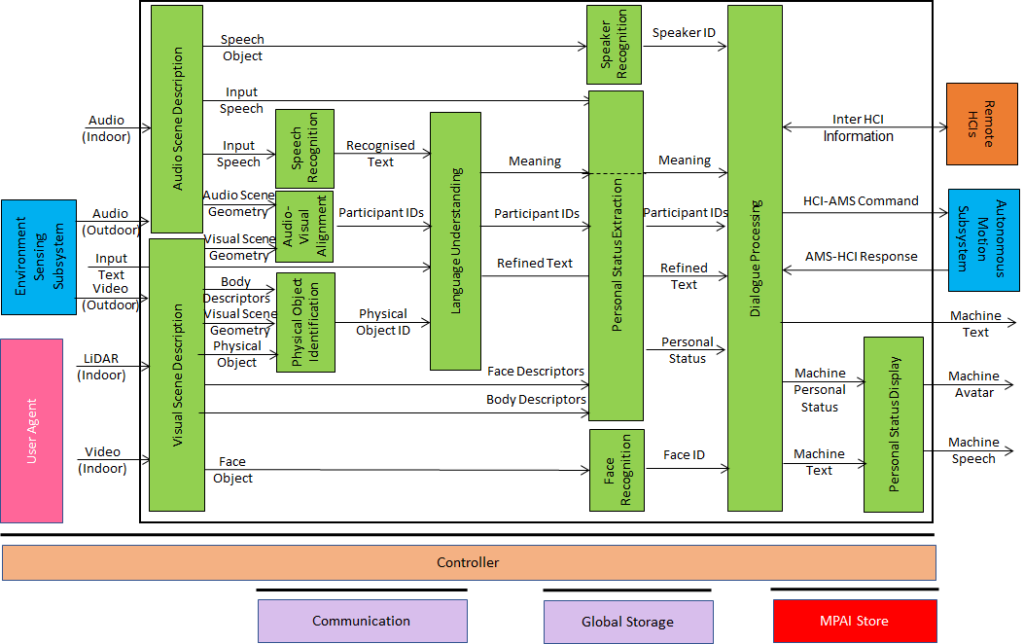
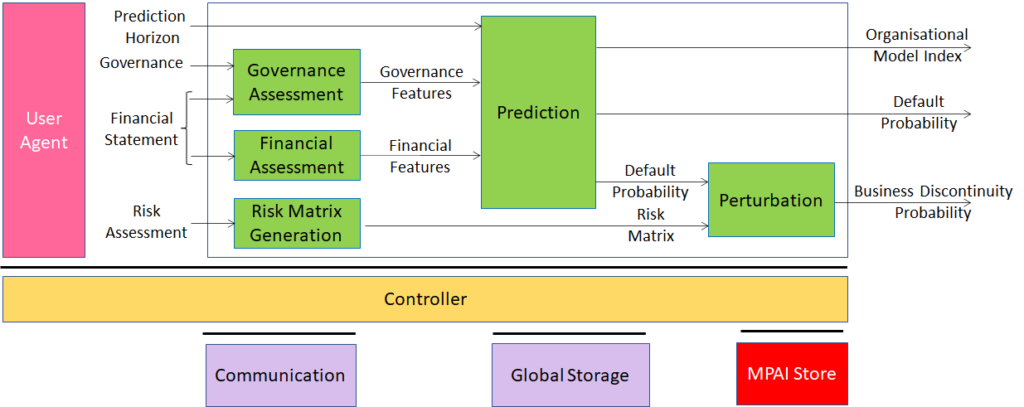
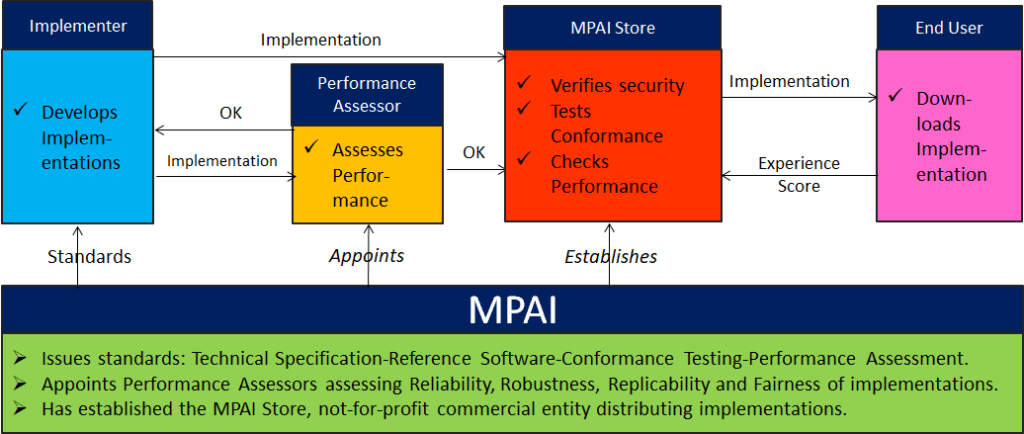
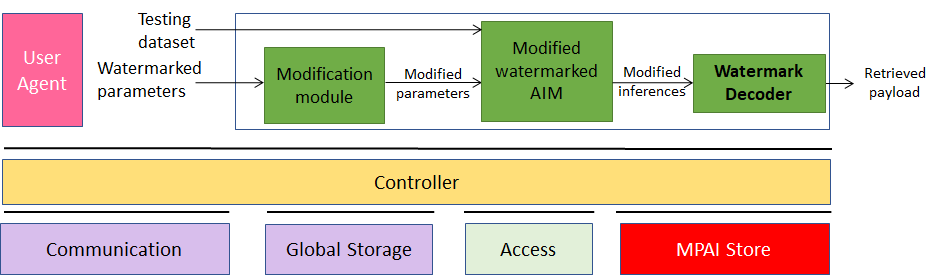
An overview of AI Framework (MPAI-AIF)
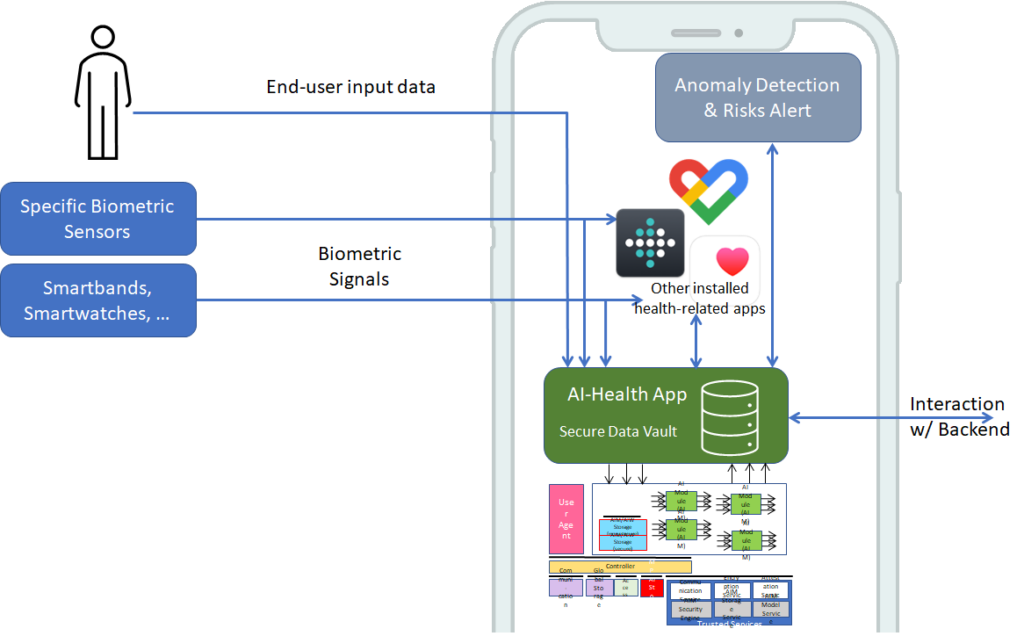
From its early days, MPAI realised that AI-based data coding standards could facilitate AI explainability if monolithic AI applications could be broken down to individual components with identified functionality processing and producing data with semantics known as far as possible. An important side effect of this approach was identified in the possibility for developers to provide components with standard interfaces and potentially better performance than that provided by other developers. Version 1 of AI Framework (MPAI-AIF) published in September 2021 was the first standard supporting the original vision. Most MPAI application standards are built on top of MPAI-AIF.
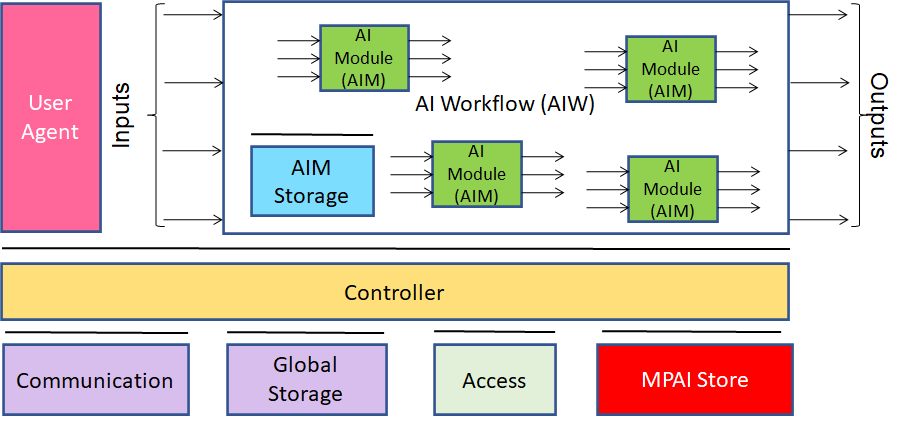
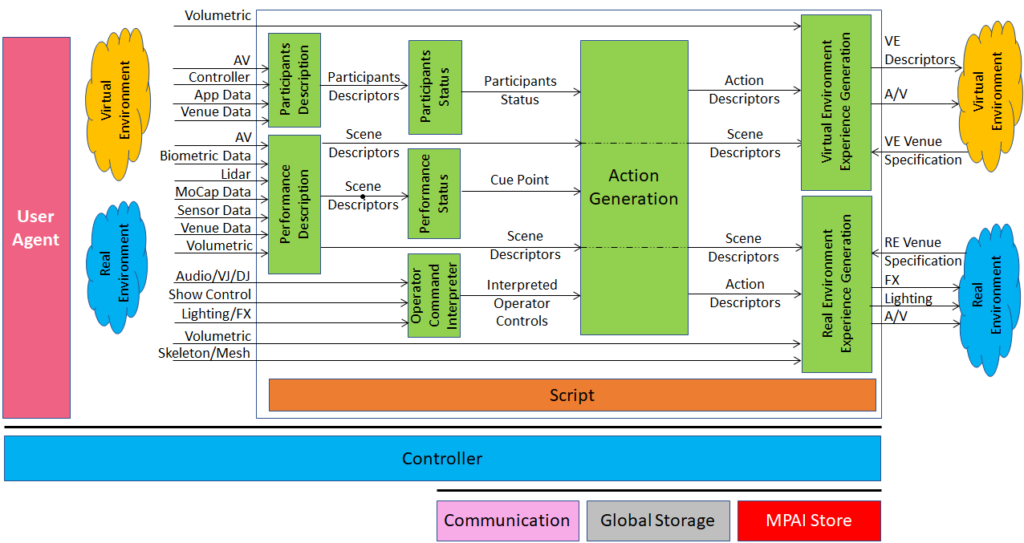
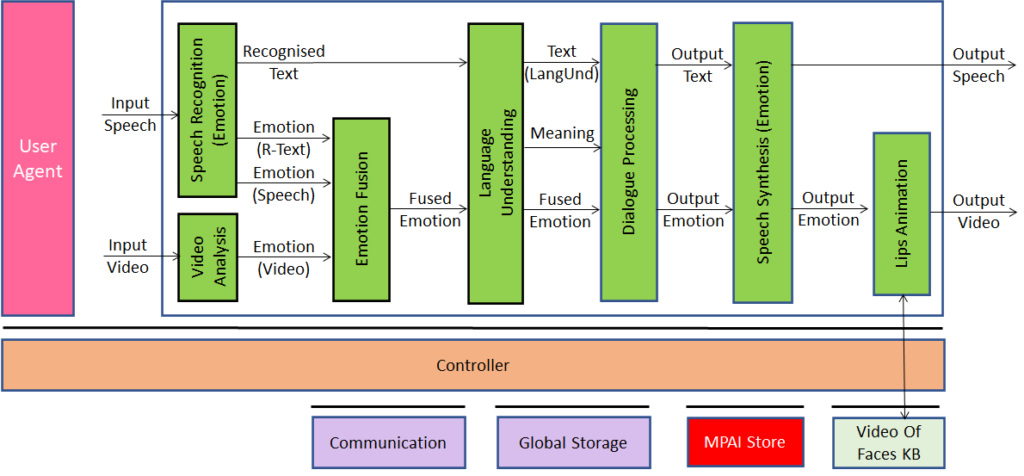
Figure 1 – Reference Model of AI Framework (MPAI-AIF) V1
The main features of MPAI-AIF V1 were:
- Independence of the Operating System.
- Components have specified interfaces encapsulating Components to abstract them from the development environment.
- Interface with the MPAI Store enabling access to validated Components.
- Components implementable as software only, hardware only, and Hybrid hardware-software.
- Execution in local and distributed Zero-Trust architectures.
- Possibility to interact with other AIF implementations operating in proximity.
The Components have the following functionalities:
- Access: to access to static or slowly changing data such as domain knowledge data, data models.
- AI Module (AIM): a data processing element receiving Inputs and producing Outputs according to its Function. An AIM may be an aggregation of AIMs.
- AI Workflow (AIW): an organised aggregation of AIMs implementing a Use Case.
- Communication: connects the Components of an AIF.
- Controller: can run May run one or more AIWs and exposes three APIs:
- AIM API modules can register, communicate and access the AIF environment; can start, stop, and suspend AIMs.
- User API User or other Controllers can perform high-level tasks (e.g., switch the Controller on and off, give inputs to the AIW through the Controller).
- MPAI Store API communication between the AIF and the Store.
- Global Storage: stores data shared by AIMs.
- AIM/AIW Storage: stores data of the individual AIMs (securely/non-securely).
- MPAI Store: stores Implementations for users to download.
- User Agent: The Component interfacing the user with an AIF through the Controller
Table 1 gives the APIs exposed by MPAI-AIF V1 are:
Table 1 – APIs of MPAI-AIF V1
| # | API |
| 8.1 | Store API called by Controller |
| 8.1.1 | Get and parse archive |
| 8.2 | Controller API called by User Agent |
| 8.2.1 | General |
| 8.2.2 | Start/Pause/Resume/Stop Messages to other AIWs |
| 8.2.3 | Inquire about state of AIWs and AIMs |
| 8.2.4 | Management of Shared and AIM Storage for AIWs |
| 8.2.5 | Communication management |
| 8.2.6 | Resource allocation management |
| 8.3 | Controller API called by AIMs |
| 8.3.1 | General |
| 8.3.2 | Resource allocation management |
| 8.3.3 | Register/deregister AIMs with the Controller |
| 8.3.4 | Send Start/Pause/Resume/Stop Messages to other AIMs |
| 8.3.5 | Register Connections between AIMs |
| 8.3.6 | Using Ports |
| 8.3.7 | Operations on messages |
| 8.3.8 | Functions specific to machine learning |
| 8.3.9 | Controller API called by Controller |
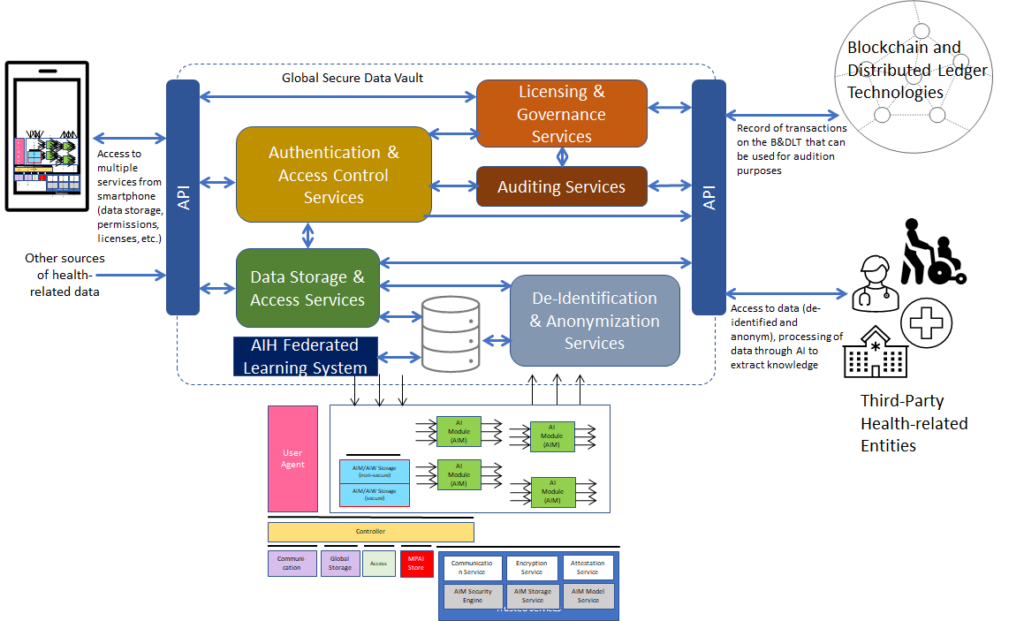
Version 1 assumed that the environment was Zero-Trust but its implementation was left to the developer. Version 2 extends Version 1 by making V1 as the Basic Profile of MPAI-AIF. The Basic Profile utilises:
- Non-Secure Controller.
- Non-Secure Storage.
- Secure Communication enabled by secure communication libraries.
- Basic API.
The Secure Profile utilises all the technologies in this Technical Specification.
V2 adds the necessary technology for a new Secure Profile offering the following functionalities:
- The Framework provides access to the following Trusted Services:
- A selected range of cyphering algorithms.
- A basic attestation function.
- Secure storage.
- Certificate-based secure communication.
- The AIF can execute only one AIW containing only one AIM. The sole AIM has the following features:
- The AIM may be a Composite AIM.
- The AIMs of the Composite AIM cannot access the Secure API.
- The AIF Trusted Services may rely on hardware and OS security features already existing in the hardware and software of the environment in which the AIF is implemented.
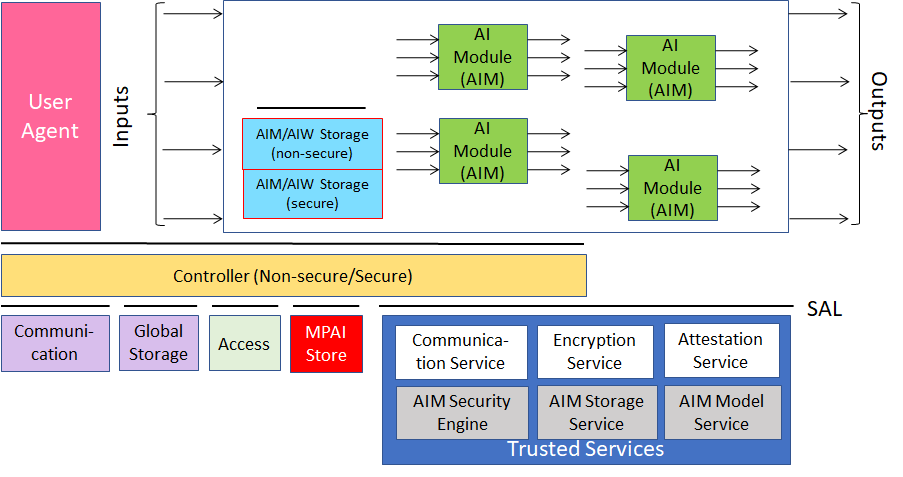
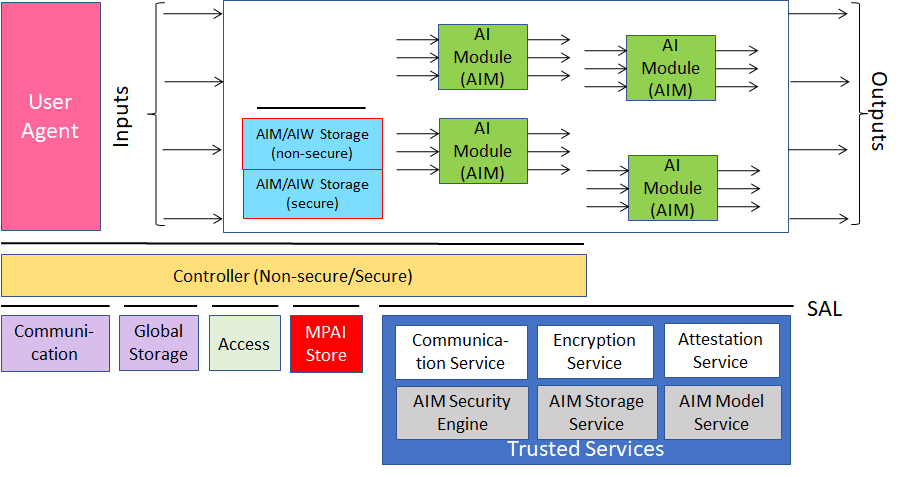
Figure 2 – Reference Model of AI Framework (MPAI-AIF) V2
By virtue of incorporating the Secure Abstraction Layer, MPAI-AIF V2 adds the following features to V1:
- The AIMs of a Composite AIM must run on the same computing platform.
- The AIW
- The AIMs in the AIW trust each other and communicate without special security concerns.
- Communication among AIMs in the Composite AIM is non-secure.
- The AIW/AIMs call the Secure Abstraction Layer via API.
- The Controller
- Communicates securely with the MPAI-Store and the User Agent (Authentication, Attestation, and Encryption).
- Accesses Communication, Global Storage, Access and MPAI Store via Trusted Services API.
- Is split in two parts:
- Secure Controller accesses Secure Communication and Secure Storage.
- Non-Secure Controller can access the non-secure parts of the AIF.
- Interfaces with the User Agent in the area where non-secure code is executed.
- Interface with the Composite AIM in the area where secure code is executed,
- The AIM/AIW Storage
- Secure Storage functionality is provided through key exchange.
- Non-secure functionality is provided without reference to secure API calls.
The capabilities of the AIF, AIW, and AIM are described by a standard JSON metadata format that enables an AIF to download suitable AIW and AIMs from the MPAI Store.
Table 2 gives the APIs exposed by MPAI-AIF V2:
Table 1 – APIs of MPAI-AIF V2
| # | API |
| 9.1 | Data characterization structure. |
| 9.2 | API called by User Agent |
| 9.3 | API to access Secure Storage |
| 9.3.1 | User Agent initialises Secure Storage API |
| 9.3.2 | User Agent writes Secure Storage API |
| 9.3.3 | User Agent reads Secure Storage API |
| 9.3.4 | User Agent gets info from Secure Storage API |
| 9.3.5 | User Agent deletes a p_data in Secure Storage API |
| 9.4 | API to access Attestation |
| 9.5 | API to access cryptographic functions |
| 9.5.1 | Hashing |
| 9.5.2 | Key management |
| 9.5.3 | Key exchange |
| 9.5.4 | Message Authentication Code |
| 9.5.5 | Cyphers |
| 9.5.6 | Authenticated encryption with associated data (AEAD) |
| 9.5.7 | Signature |
| 9.5.8 | Asymmetric Encryption |
| 9.6 | API to enable secure communication |
MPAI has published a Working Draft of Version 2 (html, pdf) requesting Community Comments. Version 2 extends the capabilities of Version 1 making it easier to AI application developers to support security in their applications. Comments should be sent to the MPAI Secretariat by 2023/09/24T23:59 UTC. An online presentation of the AI Framework V2 WD will be held on September 11 at 08 and 15 UTC. Register here for the 08 UTC and here for the 15 UTC presentations.
For the future, MPAI plans on:
- Publishing MPAI-AIF as a Technical Specification at the 36th General Assembly (29 September 2023).
- Continuing the implementation of AIF V1 for more OSs and programming languages than currently available.
- Implementing the Reference Software of MPAI-AIF V2.