Four weeks to go to the Calls for Technologies deadline
In July 2022 MPAI issued 3 Calls for Technologies on AI Framework security, Multimodal Conversation and Neural Network Watermarking. The MPAI Secretariat should receive responses by 2022/10/24 T23:59 UTC.
This newsletter reviews the content of the calls thus helping those who might wish to exploit this opportunity to strengthen the technical basis of the MPAI-AIF and MPAI-MMC standards being extended and of the new MPAI-NNW standard being developed.
Security in the AI Framework
A foundational element of the MPAI architecture is the fact that monolithic AI applications have some characteristics that make them undesirable. For instance, they are single use, i.e., it is hard to reuse technologies used by the application in another application and they are obscure, i.e., it is hard to understand why a machine has produced a certain output when subjected to a certain input. The first characteristic means that it is hard to make complex applications because an implementer must possess know-how of all features of the applications and the second is that they often are “unexplainable”.
MPAI launched AI Framework (AIF), its first official standardisation activity in December 2020, less than 3 months after its establishment. AIF is a standard environment where it is possible to execute AI Workflows (AIW) composed of AI Modules (AIM). Both AIWs and AIMs are defined by their function and their interfaces. AIF is unconcerned by the technology used by an AIM but needs to know the topology of an AIW.
Ten months later (October 2021) the MPAI-AIF standard was approved. Its structure is represented by Figure 1.
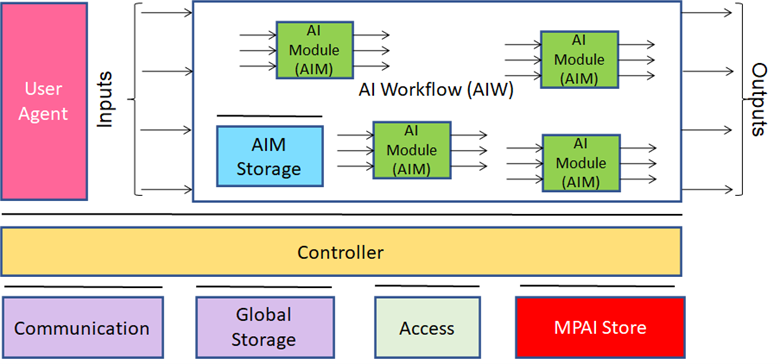
Figure 1 – The MPAI-AIF Reference Model
MPAI’s AI Framework (MPAI-AIF) specifies the architecture, interfaces, protocols, and Application Programming Interfaces (API) of the AI Framework (AIF), an environment specially designed for execution of AI-based implementations, but also suitable for mixed AI and traditional data processing workflows.
The AIF, the AIW and the AIMs are represented by JSON Metadata. The User Agent and the AIMs call the Controller through a set of standard APIs. Likewise, the Controller calls standard APIs to interact with Communication (a service for inter-AIM communication), Global Storage (a service for AIMs to store data for access by other AIMs) and the MPAI Store (a service for downloading AIMs required by an AIW). Access represents access to application-specific data.
Through the JSON Metadata, an AIF with appropriate resources (specified in the AIF JSON Metadata) can execute an AIW requiring AIMs (specified in the AIF JSON Metadata) that can be downloaded from the MPAI Store.
The MPAI-AIF standard has the following main features:
- Independence of the Operating System.
- Modular component-based architecture with specified interfaces.
- Encapsulation of component interfaces to abstract them from the development environment.
- Interface with the MPAI Store enabling access to validated components.
- Component can be implemented as software, hardware or mixed hardware-software.
- Components: execute in local and distributed Zero-Trust architectures, can interact with other implementations operating in proximity and support Machine Learning functionalities.
The MPAI-AIF standard achieves much of the original MPAI vision because AI applications:
- Need not be monolithic but can be composed of independently developed modules with standard interfaces
- Are more explainable
- Can be found in an open market.
Feature #6 above is a requirement, but the standard does not provide practical means for an application developer to ensure that the execution of the AIW takes place in a secure environment. Version 2 of MPAI-AIF intends to provide exactly that. As MPAI-AIF V1 does not specify any trusted service that an implementer can rely on, MPAI-AIF V2 identifies specific trusted services supporting the implementation of a Trusted Zone meeting a set of functional requirements that enable AIF Components to access trusted services via APIs, such as:
- AIM Security Engine.
- Trusted AIM Model Services
- Attestation Service.
- Trusted Communication Service.
- Trusted AIM Storage Service
- Encryption Service.
Figure 2 represents the Reference Models of MPAI-AIF V2.
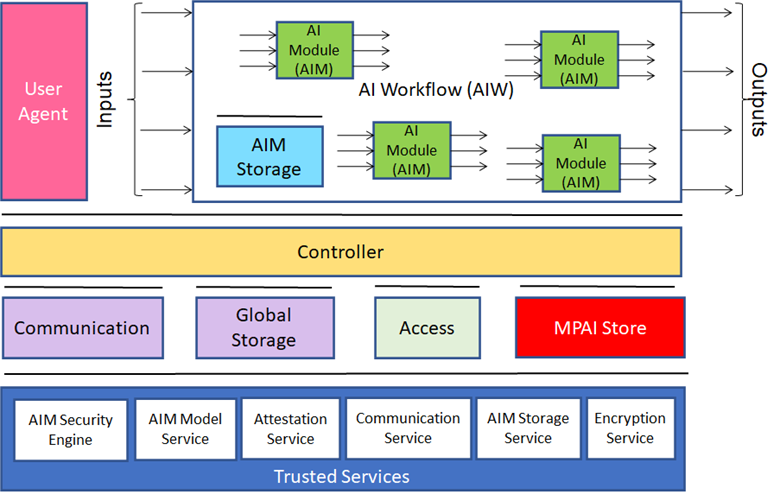
Figure 2 – Reference Models of MPAI-AIF V2
The AIF Components shall be able to call Trusted Services APIs after establishing the developer-specified security regime based on the following requirements:
- The AIF Components shall access high-level implementation-independent Trusted Services API to handle:
- Encryption Service.
- Attestation Service.
- Trusted Communication Service.
- Trusted AIM Storage Service including the following functionalities:
- AIM Storage Initialisation (secure and non-secure flash and RAM)
- AIM Storage Read/Write.
- AIM Storage release.
- Trusted AIM Model Services including the following functionalities:
- Secure and non-secure Machine Learning Model Storage.
- Machine Learning Model Update (i.e., full, or partial update of the weights of the Model).
- Machine Learning Model Validation (i.e., verification that the model is the one that is expected to be used and that the appropriate rights have been acquired).
- AIM Security Engine including the following functionalities:
- Machine Learning Model Encryption.
- Machine Learning Model Signature.
- Machine Learning Model Watermarking.
- The AIF Components shall be easily integrated with the above Services.
- The AIF Trusted Services shall be able to use hardware and OS security features already existing in the hardware and software of the environment in which the AIF is implemented.
- Application developers shall be able to select the application’s security either or both by:
- Level of security that includes a defined set of security features for each level, i.e., APIs are available to either select individual security services or to select one of the standard security levels available in the implementation.
- Developer-defined security, i.e., a combination of a developer-defined set of security features.
- The specification of the AIF V2 Metadata shall be an extension of the AIF V1 Metadata supporting security with either or both standardised levels and a developer-defined combination of security features.
- MPAI welcomes the submission of use cases and their respective threat models.
MPAI has rigorously followed its standard development process in producing the Use Cases and Functional Requirements summarised in this post. MPAI has additionally produced The Commercial Requirements (Framework Licence) and the text of the Call for Technologies.
Below are a few useful links for those wishing to know more about the MPAI-AIF V2 Call for Technologies and how to respond to it:
- The “About MPAI-AIF” web page provides some general information about MPAI-AIF.
- The MPAI-AIF V1 standard can be downloaded from here.
- The 1 min 20 sec video (YouTube and (non-YouTube) concisely illustrates the MPAI-AIFV2 Call for Technologies.
- The slides and the video recording of the online presentation (YouTube, non-YouTube) made at the 11 July online presentation give a complete overview of MPAI-AIF V2.
Enhancing human-machine conversation
Processing and generation of natural language is an area where artificial Intelligence is expected to make a difference compared to traditional technologies. Version 1 of the MPAI Multimodal Conversation standard (MPAI-MMC V1), specifically the Conversation with Emotion use case, has addressed this and related challenges: processing and generation not only of speech but also of the corresponding human face when both convey emotion.
The audio and video produced by a human conversing with the machine represented by the blue box in Figure 1 is perceived by the machine which then generates a human-like speech and video in response.
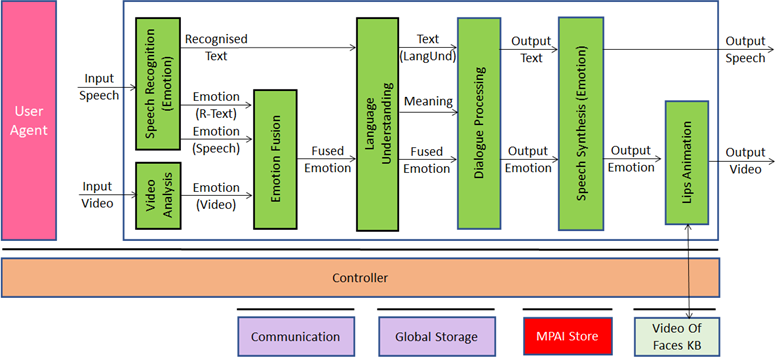
Figure 1 – Multimodal conversation in MPAI-MMC V1
The system depicted in Figure 1 operates as follows (bold indicates module, underline indicates output, italic indicates input):
- Speech Recognition (Emotion) produces Recognised Text from Input Speech and the Emotion embedded in Recognised Text and in Input Speech.
- Video Analysis extracts the Emotion expressed in Input Video (human’s face).
- Emotion Fusion fuses the three Emotions into one (Fused Emotion).
- Language Understanding produces Text (Language Understanding) from Recognised Text and Fused Emotion.
- Dialogue Processing generates pertinent Output Text and Output Emotion using Text, Meaning, and Fused Emotion.
- Speech Synthesis (Emotion) synthesises Output Speech from Output Text.
- Lips Animation generates Output Video displaying the Output Emotion with lips animated by Output Speech using Output Speech, Output Emotion and a Video drawn from the Video of Faces Knowledge Base.
The MPAI-MMC V2 Call for Technologies issued in July 2022, seeks four major classes of technologies enabling a significant extension of the scope of its use cases:
- The internal status of a human from Emotion, defined as the typically non-rational internal status of a human resulting from their interaction with the Environment, such as “Angry”, “Sad”, “Determined” to two more internal statuses: Cognitive State, defined as the typically rational internal status of a human reflecting the way they understand the Environment, such as “Confused”, “Dubious”, “Convinced”, and Attitude, defined as the internal status of a human or avatar related to the way they intend to position themselves vis-à-vis the Environment, e.g., “Respectful”, “Confrontational”, “Soothing”. Personal Status is the combination of Emotion, Cognitive State and Attitude. These can be extracted not only from speech and face but from text and gesture (intended as the combination of the head, arms, hands and fingers) as well.
- The direction suggested by the Conversation with Emotion use case where the machine generates an Emotion pertinent to what it has heard (Input Speech) and seen (human face of Input Video) but also to what the machine is going to say (Output Text). Therefore, Personal Status is not just extracted from a human but can also be generated by a machine.
- Enabling solutions no longer targeted to a controlled environment but facing the challenges of the real world: to enable a machine to create the digital representation of an audio-visual scene composed of speaking humans in a real environment.
- Enabling one party to animate an avatar model using standard descriptors and model generated by another party.
More information about Personal Status and its applications in Personal Status Extraction and Personal Status Display can be found in Personal Status in human-machine conversation.
With these technologies MPAI-MMC V2 will support three new use cases:
- Conversation about a scene. A human has a conversation with a machine about the objects in a room. The human uses gestures to indicate the objects of their interest. The machine uses a personal status extraction module to better understand the internal status of the human and produces responses that include text and personal status. The machine manifests itself via a personal status display module (see more here).
- Human-Connected Autonomous Vehicle (CAV) Interaction. A group of humans interact with a CAV to get on board, request to be taken to a particular venue and have a conversation with the CAV while travelling. The CAV uses a personal status extraction module to better understand the personal status of the humans and produces responses that include Text and Personal Status. The CAV manifests itself via a personal status display module (again, see more here).
- Avatar-Based Videoconference. (Groups of) humans from different geographical locations participate in a virtual conference represented by avatars animated by descriptors produced by their clients using face and gesture descriptors supported by speech analysis and personal status extraction. The server performs speech translation and distributes avatar models and descriptors. Each participant places the individual avatars animated by their descriptors around a virtual table with their speech. A virtual secretary creates an editable summary recognising the speech and extracting the personal status of each avatar.
Figure 2 represents the reference diagram of Conversation about a Scene.
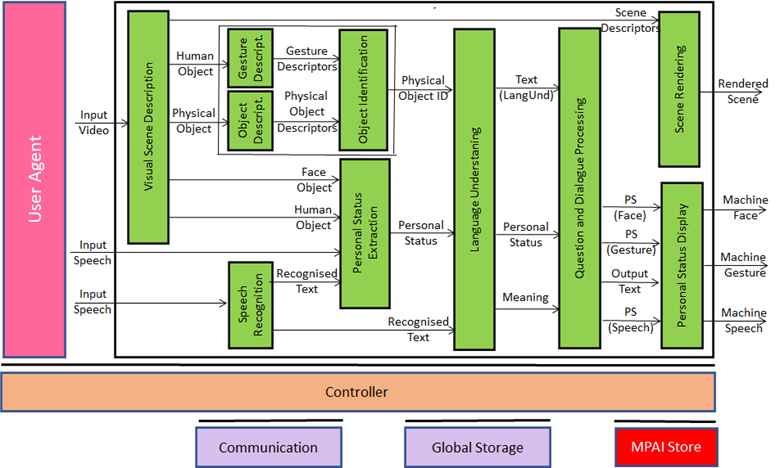
Figure 2 – Conversation about a Scene in MPAI-MMC V2
The system depicted in Figure 2 operates as follows:
- Visual Scene Description creates a digital representation of the visual scene.
- Speech Recognition recognises the text uttered by the human.
- Object Description, Gesture Description and Object Identification provide the ObjectID.
- Personal Status Extraction provides the human’s current Personal Status.
- Language Understanding provides Text (Language Understanding) and Meaning.
- Question and Dialogue Processing generates Output Text and the Personal State of each of Speech, Face and Gesture.
- Personal Status Display produces a speaking avatar animated by Output Text and the Personal State of each of Speech, Face and Gesture.
The internal architecture of the Personal Status Display module is depicted in Figure 3.
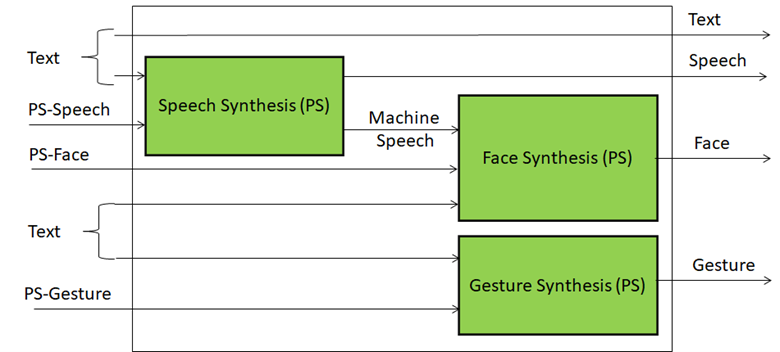
Figure 3 – Architecture of the Personal Status Display Module
Those wishing to know more about the MPAI-MMC V2 Call for Technologies should review:
- The 2 min video (YouTube, non-YouTube) illustrating MPAI-MMC V2.
- The slides presented at the online meeting on 2022/07/12.
- The video recording of the online presentation (YouTube, non-YouTube) made at that 12 July presentation.
- The Call for Technologies, Use Cases and Functional Requirements, Clarifications about MPAI-MMC V2 Call for Technologies data formats, Framework Licence, and Template for responses.
Neural Networks, a new type of asset
Research, personnel, training and processing can bring the development costs of a neural network anywhere from a few thousand to a few hundreds of thousand dollars. Therefore, the AI industry needs a technology to ensure traceability and integrity not only of a neural network, but also of the content generated by it (so-called inference). The content industry facing a similar problem, has used watermarking to imperceptibly and persistently insert a payload carrying, e.g., owner ID, timestamp, etc. to signal the ownership of a content item. Watermarking can also be used by the AI industry.
The general requirements for using watermarking in neural networks are:
- The techniques shall not affect the performance of the neural network.
- The payload shall be recoverable even if the content was modified.
MPAI has classified the cases of watermarking use as follows:
- Identification of actors (i.e., neural network owner, customer, and end-user).
- Identification of the neural network model.
- Detecting the modification of a neural network.
This classification is depicted in Figure 1 and concerns the use of watermarking technologies in neural networks and is independent of the intended use.
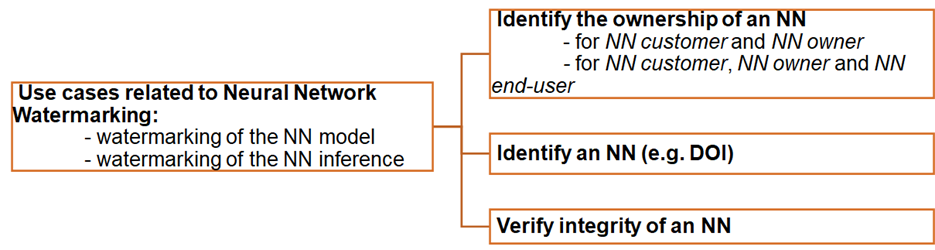
Figure 1 – Classification of neural network watermarking uses
MPAI has identified the need for a standard – code name MPAI-NNW – enabling users to measure the performance of the following component of a watermarking technology:
- The ability of a watermark inserter to inject a payload without deteriorating the performance of the Neural Network.
- The ability of a watermark detector to ascertain the presence and of a watermark decoder to retrieve the payload of the inserted watermark when applied to:
- A modified watermarked network (e.g., by transfer learning or pruning).
- An inference of the modified model.
- The computational cost (e.g., execution time) of a watermark inserter to inject a payload, a watermark detector/decoder to detect/decode a payload from a watermarked model or from any of its inferences.
Figure 2 depicts the three watermarking components covered by MPAI-NNW.
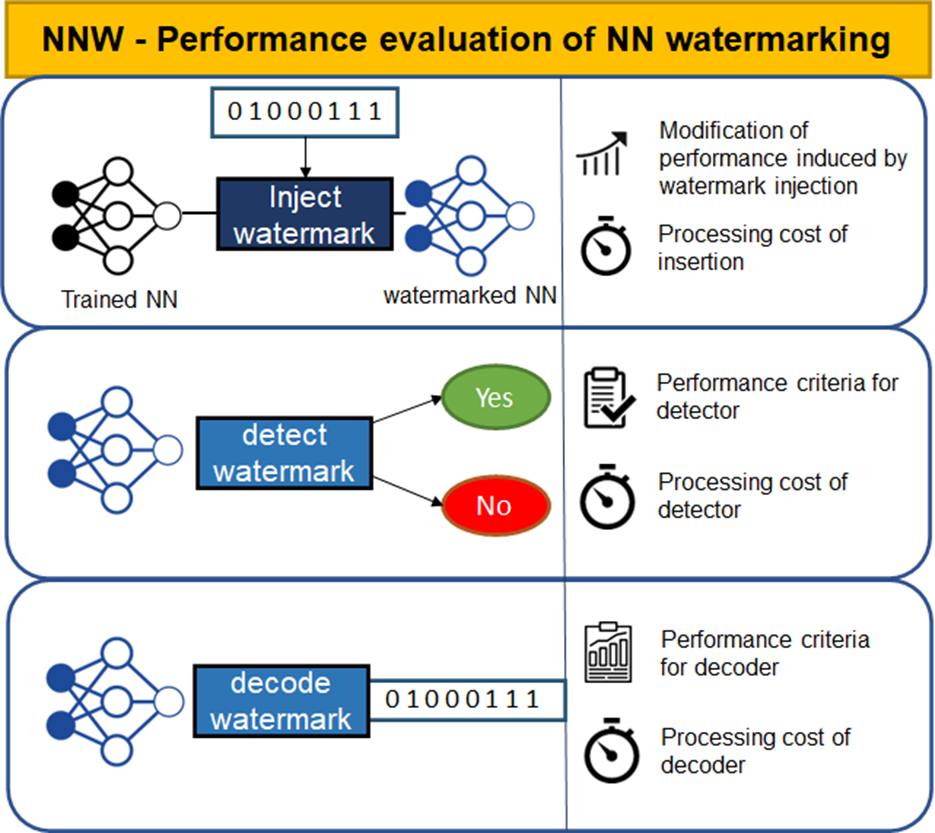
Figure 2 – The three areas to be covered by MPAI-NNW
MPAI has issued a Call to acquire the technologies for use in the standard. The list below is a subset of the requests contained in the call:
- Use cases
- Comments on use cases.
- Impact of the watermark on the performance
- List of Tasks to be performed by the Neural Network (g. classification task, speech generation, video encoding, …).
- Methods to measure the quality of the inference produced (g. precision, recall, subjective quality evaluation, PSNR, …).
- Detection/Decoding capability
- List of potential modifications that a watermark shall be robust against (g. pruning, fine-tuning, …).
- Parameters and ranges of proposed modifications.
- Methods to evaluate the differences between the original and retrieved watermarks (g., Symbol Error Rate).
- Processing cost
- Specification of the testing environments.
- Specification of the values characterizing the processing of Neural Networks.
Below are a few useful links for those wishing to know more about the MPAI-NNW Call for Technologies and how to respond to it:
- 1 min 30 sec video (YouTube and non YouTube) illustrating functional requirements of MPAI-NNW V1.
- slides presented at the online meeting on 2022/07/12.
- video recording of the online presentation (Youtube, non-YouTube) made at that 12 July presentation
- Call for Technologies, Use Cases and Functional Requirements, Framework Licence and MPAI-NNW Template for responses.
Meetings in the coming October meeting cycle
Non-MPAI members may join the meetings in italics. If interested, please contact the MPAI secretariat.
| Group name | 3-7 Oct |
10-14 Oct |
17-21 Oct |
24-28 Oct |
Time (UTC) |
| AI Framework | 3 | 10 | 17 | 24 | 15 |
| Governance of MPAI Ecosystem | 3 | 10 | 17 | 24 | 16 |
| Multimodal Conversation | 4 | 11 | 18 | 25 | 14 |
| Neural Network Watermaking | 4 | 11 | 18 | 25 | 15 |
| Context-based Audio enhancement | 4 | 11 | 25 | 16 | |
| XR Venues | 4 | 11 | 18 | 25 | 17 |
| Connected Autonomous Vehicles | 5 | 12 | 19 | 26 | 12 |
| AI-Enhanced Video Coding | 5 | 19 | 14 | ||
| AI-based End-to-End Video Coding | 12 | 26 | 14 | ||
| Avatar Representation and Animation | 6 | 13 | 20 | 13:30 | |
| Server-based Predictive Multiplayer Gaming | 6 | 13 | 20 | 14:30 | |
| Communication | 6 | 20 | 15 | ||
| Artificial Intelligence for Health Data | 21 | 14 | |||
| MPAI Metaverse Model | 7 | 14 | 21 | 28 | 15 |
| Industry and Standards | 7 | 21 | 16 | ||
| General Assembly (MPAI-25) | 26 | 15 |