MPAI presents online its End-to-End video codec with better compression than traditional codecs
Fifteen months ago, MPAI started an investigation on AI-based End-to-End Video Coding, a new approach to video coding not based on traditional architectures. Recently published results show that Version 0.3 of the MPAI-EEV Reference Model (EEV-0.3) has generally higher performance than the MPEG-HEVC video coding standard when applied to the MPAI set of high-quality drone video sequences.
This is now supersed by the news that the soon-to-be-released EEV-0.4 subjectively outperforms the MPEG-VVC codec using low-delay P configuration. Join the online presentation of MPAI EEV-0.4
Time: 15 UTC on the 1st of March 2023, Place
You will learn about the model, its performance, and its planned public release both for training and test, and how you can participate in the EEV meetings and contribute to achieving the amazing promises of end-to-end video coding.
The main features of EEV-0.4 are:
- A new model that decomposes motion into intrinsic and compensatory motion: the former, originating from the implicit spatiotemporal context hidden in the reference pictures, does not add to the bit budget while the latter, playing a structural refinement and texture enhancement role, requires bits.
- Inter prediction is performed in the deep feature space in the form of progressive temporal transition, conditioned on the decomposed motion.
- The framework is end-to-end optimized together with the residual coding and restoration modules.
Extensive experimental results on diverse datasets (MPEG test and non-standard sequences) demonstrate that this model outperforms the VTM-15.2 Reference Model in terms of MS-SSIM.
You are invited to attend the MPAI EEV-0.4 presentation. You will learn about the model, its performance, and its planned public release both for training and test, and how you can participate in the EEV meetings and contribute to achieve the amazing promises of end-to-end video coding.
|
MPAI is now offering its Unmanned Aerial Vehicle (UAV) sequence dataset for use by the video community in testing compression algorithms. The dataset contains various drone videos captured under different conditions, including environments, flight altitudes, and camera views. These video clips are selected from several categories of real-life objects in different scene object densities and lighting conditions, representing diverse scenarios in our daily life.
Compared to natural videos, UAV-captured videos are generally recorded by drone-mounted cameras in motion and at different viewpoints and altitudes. These features bring several new challenges, such as motion blur, scale changes and complex background. Heavy occlusion, non-rigid deformation and tiny scales of objects might be of great challenge to drone video compression.
Please get an invitation from the MPAI Secretariat and come to one of the biweekly meetings of the MPAI-EEV group (starting from 1st of February 2023). The MPAI-EEV group is going to showcase its superior performance fully neural network-based video codec model for drone videos. The group is inclusive and planning for the future of video coding using end-to-end learning. Please feel free to participate, leaving your comments or suggestions to the MPAI-EEV. We will discuss your contribution and our state of the art with the goal of progressing this exciting area of coding of video sequences from drones.
See https://eev.mpai.community/
Join MPAI – Share the fun – Build the future!
|
MPAI responds to industry needs with a rigorous process that includes 8 phases starting from Interest Collection up to Technical Specification. The initial phase of the process:
- Starts with the submission of a proposal triggering the Interest Collection stage where the interest of people other than the proposers is sought.
- Continues with the Use Cases stage where applications of the proposal are studied.
- Concludes with the Functional Requirements stage where the AI Workflows implementing the developed use cases and their composing AI Modules are identified with their functions and data formats.
An AI Workflow is executed in the standard MPAI AI Framework (MPAI-AIF) designed to support the execution of AI Workflows composed of multi-sourced AI Modules.
Let’s see how things are developing in the XR Venues project (MPAI-XRV) now at the Functional Requirements stage. The project addresses use cases enabled by Extended Reality (XR) technologies – the combination of Augmented Reality (AR), Virtual Reality (VR) and Mixed Reality (MR) – and enhanced by Artificial Intelligence (AI) technologies. The word “venue” is used as a synonym for “real and virtual environments”.
The XRV group has identified some 10 use cases and made a detailed analysis of three of them: eSports Tournament, Live theatrical stage performance, and Experiential retail/shopping.
The eSports Tournament use case consists of two teams of 3 to 6 players arranged on either side of a real world (RW) stage, each using a computer to compete within a real-time Massively Multiplayer Online game space.

Figure 1 – An eSports Tournament
The game space occurs in a virtual world (VW) populated by:
- Players represented by avatars each driven by role (e.g., magicians, warriors, soldier, etc.), properties (e.g., costumes, physical form, physical features), and actions (e.g., casting spells, shooting, flying, jumping).
- Avatars representing other players, autonomous characters (e.g., dragon, monsters, various creatures), and environmental structures (e.g., terrain, mountains, bodies of water).
The game action is captured by multiple VW cameras and projected onto a RW immersive screen surrounding spectators and live streamed to remote spectators as a 2D video with all related sounds of the VW game space.
A shoutcaster calls the action as the game proceeds. The RW venue (XR Theatre) includes one or more immersive screens where the image of RW players, player stats or other information or imagery may also be displayed. The same may also be live streamed. The RW venue is augmented with lighting and special effects, music, and costumed performers.
Live stream viewers interact with one another and with commentators through live chats, Q&A sessions, etc. while RW spectators interact through shouting, waving and interactive devices (e.g., LED wands, smartphones). RW spectators’ features are extracted from data captured by camera and microphone or wireless data interface and interpreted.
Actions are generated from RW or remote audience behaviour and VW action data (e.g., spell casting, characters dying, bombs exploding).
At the end of the tournament, an award ceremony featuring the winning players on the RW stage is held with great fanfare.
The eSports Tournament use case is a representative example of the XRV project where human participants are exposed to real and virtual environments that interact with one another. Figure 1 depicts the general model representing how data from a real or virtual environment are captured, processed, and interpreted to generate actions transformed into experiences that are delivered to another real or virtual environment.
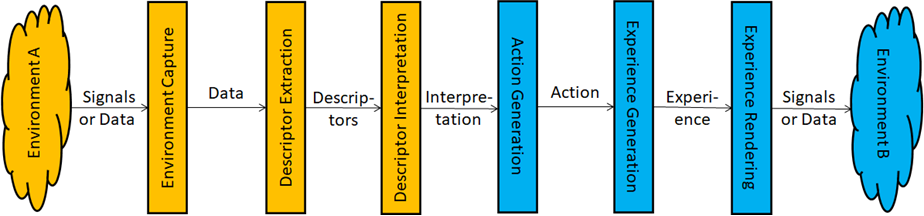
Figure 2 – Environment A (yellow) to Environment B (blue) Interactions
Irrespective of whether Environment A is real or virtual, Environment Capture captures signals and/or data from the environment, Feature Extraction extracts descriptors from data, and Feature Interpretation yields interpretations by analysing those descriptors. Action Generation generates actions by analysing interpretations, Experience Generation translates action into an experience, and Environment Rendering delivers the signals and/or data corresponding to the experience into Environment B whether real or virtual. Of course, the same sequence of steps can occur in the right-to-left direction starting from Environment B.
A thorough analysis of the eSports Tournament use case has led the XRV group to develop the reference model depicted in Figure 3.
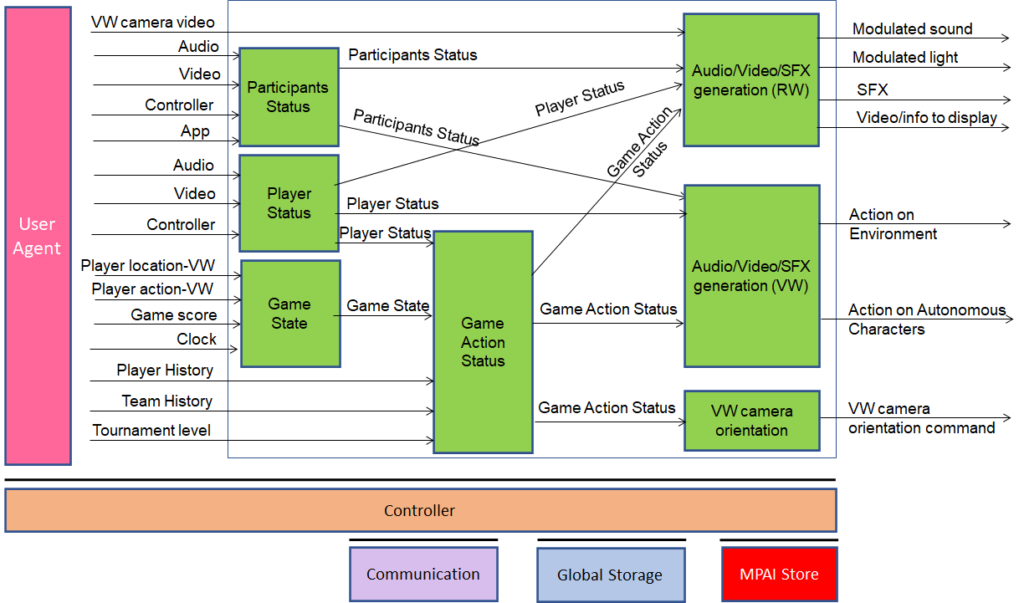
Figure 3 – Reference Model of eSports Tournament
The AI Modules on the left-hand side and in the middle of the reference model perform the Description Extraction and Descriptor Interpretation identified in Figure 2. The data generated by them are:
- Player Status is the ensemble of information internal to the player, expressed by Emotion, Cognitive State, and Attitude estimated from Audio-Video-Controller-App of the individual players.
- Participants Status is the ensemble of information, expressed by Emotion, Cognitive State and Attitude of participants, estimated from the collective behaviour of Real World and on-line spectators in response to actions of a team, a player, or the game through audio, video, interactive controllers, and smartphone apps. Both data types are similar to the Personal Status developed in the context of Multimodal Conversation Version 2.
- Game State is estimated from Player location and Player Action (both in the VW), Game Score and Clock.
- Game Action Status is estimated from Game State, Player History, Team History, and Tournament Level.
The four data streams are variously combined by the three AI Modules on the right-hand side to generate effects in the RW and VW, and to orientate the cameras in the VW. These correspond to the Action Generation, Experience Generation and Experience Rendering of Figure 2.
The definition of interfaces between the AI Modules of 3 will enable the independent development of those AI Modules with standard interfaces. An XR Theatre will be able to host a pre-existing game and produce an eSports Tournament supporting RW and VW audience interactivity. To the extent that the game possesses the required interfaces, the XR Theatre also can drive actions within the VW.
eSports has grown substantially in the last decade. Arena-sized eSport Tournaments with increasing complexity are now routine. An XRV Venue dedicated to eSports enabled by AI can greatly enhanced the participants’ experience with powerful multi-sensory, interactive and highly immersive media, lowering the complexity of the system and the required human resources. Standardised AI Modules for an eSports XRV Venue enhance interoperability across different games and simplify experience design and operation.
|
MPAI has published MPAI Metaverse Model (MPAI-NNW) as a Technical Report: The MMM is a proposal for a method to develop Metaverse standards based on the experience honed during decades of digital media standardisation. MPAI-MMM seeks to accommodate the extreme heterogeneity of industries all needing a common technology complemented by industry specificities.
MPAI-MMM, however, is not just a proposal of a method. It also includes a roadmap and implements the first steps of it. The table below indicates the steps. Steps 1 to 4 are ongoing and included in the MMM. Step 5 has just started.
| # | Step | Content |
| 1 | Terms and Definitions | A set of interconnected and consistent set of terms and definitions. |
| 2 | Assumptions | A set of assumptions guiding the development of metaverse standards. |
| 3 | Use Cases | A set of 18 use cases with workflows used to develop metaverse functionalities. |
| 4 | External Services | Services potentially used by a metaverse instance to offer metaverse functionalities. |
| 5 | Functional Profiles | Profiles referencing functionalities included in the MMM, not technologies. |
| 6 | Metaverse Architecture | A metaverse architecture with functional blocks and data exchanged between blocks. |
| 7 | Functional Requirements of Data Format | F unctional requirements of the data formats exchanged between blocks. |
| 8 | CMS Table of Contents | The names and features of the technologies supporting the MMM functionalities. |
| 9 | MPAI standards | Inclusion of MPAI standards relevant to the metaverse into the CMS Table of Contents. |
MPAI is currently engaged in the development of Step #5.
|
MPAI has published Neural Network Watermarking (MPAI-NNW) as a Technical Specification. MPAI-NNW specifies methodologies to evaluate the following aspects of a neural network watermarking technology:
- The impact of the technology on the performance of a watermarked neural network and its inference.
- The ability of a neural network watermarking detector/decoder to detect/decode a payload when the watermarked neural network has been modified.
- The computational cost of injecting, detecting or decoding a payload in the watermarked neural network.
MPAI is currently developing the MPAI-NNW Reference Software.
|
Non-MPAI members may join the meetings given in italics in the table below. If interested, please contact the MPAI secretariat.
| Group name | 2-6 Jan | 9-13 Jan | 16-21 Jan | 24-28 Jan | Time (UTC) |
|
| AI Framework | 9 | 16 | 24 | 16 | ||
| AI-based End-to-End Video Coding | 4 | 18 | 14 | |||
| AI-Enhanced Video Coding | 11 | 26 | 14 | |||
| Artificial Intelligence for Health Data | 13 | 14 | ||||
| Avatar Representation and Animation | 5 | 12 | 20 | 13:30 | ||
| Communication | 5 | 20 | 15 | |||
| Connected Autonomous Vehicles | 4 | 11 | 18 | 26 | 15 | |
| Context-based Audio enhancement | 3 | 10 | 17 | 25 | 17 | |
| Governance of MPAI Ecosystem | 3 | 17 | 16 | |||
| Industry and Standards | 6 | 21 | 16 | |||
| MPAI Metaverse Model | 6 | 13 | 21 | 15 | ||
| Multimodal Conversation | 3 | 10 | 17 | 25 | 14 | |
| Neural Network Watermarking | 3 | 10 | 17 | 25 | 15 | |
| Server-based Predictive Multiplayer Gaming | 5 | 12 | 20 | 14:30 | ||
| XR Venues | 3 | 17 | 24 | 18 | ||
| General Assembly (MPAI-28) | 25 | 15 |