| 1 Function | 2 Reference Model | 3 Input/Output Data |
| 4 SubAIMs | 5 JSON Metadata | 6 Profiles |
| 7 Reference Software | 8 Conformance Testing | 9 Performance Assessment |
1 Functions
- Receives the Spherical Harmonic Decomposition coefficients of the sound field
- Detects and directions of active sound sources (either be a speech or a non-speech signal) and to separate them.
- Produces the Transformed Speech and Audio Scene Geometry..
2 Reference Model

3 Input/Output Data
| Input data | Semantics |
| Spherical Harmonics Decomposition Coefficients | Result of the transformation of Transform Multichannel Audio into the spherical frequency domain. |
| Source Model KB info | Discrete-time and discrete-valued simple acoustic source models used in source separation. |
| Output data | Semantics |
| Transform Audio | Audio in the Transform domain. |
| Audio Scene Geometry | Geometry of the Audio Scene. |
4 SubAIMs
No SubAIMs.
5 JSON Metadata
https://schemas.mpai.community/CAE1/V2.4/AIMs/SpeechDetectionAndSeparation.json
6 Profiles
No Profiles
7 Reference Software
The Speech Detection and Separation Reference Software can be downloaded from the MPAI Git.
8 Conformance Testing
| Receives | Spherical Harmonics Decomposition Coefficients | Shall validate against the Audio Object schema. The Qualifier shall validate against the Audio Qualifier schema. The values of any Sub-Type, Format, and Attribute of the Qualifier shall correspond with the Sub-Type, Format, and Attributes of the Audio Object Qualifier schema. |
| Source Model KB info | ||
| Produces | Transform Audio | Shall validate against the Audio Object schema. The Qualifier shall validate against the Audio Qualifier schema. The values of any Sub-Type, Format, and Attribute of the Qualifier shall correspond with the Sub-Type, Format, and Attributes of the Audio Object Qualifier schema. |
9 Performance Assessment
Table 55 gives the Enhanced Audioconference Experience (CAE-EAE) Speech Detection and Separation Means and how they are used.
Table 55 – AIM Means and use of Enhanced Audioconference Experience (CAE-EAE) Speech Detection and Separation
| Means | Actions |
| Performance Testing Dataset | The Performance Assessment Dataset is composed b:
DS1: n Test files containing SHD. DS2: n Expected Transform Speech Files. DS3: n Expected Audio Scene Geometry. |
| Procedure | 1. Feed the AIM under test with the Test files.
2. Analyse the Audio Scene Geometry. 3. Analyse Transform Speech Files. |
| Evaluation | 1. Control the Audio Scene Geometry with the Expected Audio Scene Geometry:
a. Count the number of objects in the Audio Scene Geometry. b. Calculate the angle difference (AD) in degrees between the objects ( ) in the Audio Scene Geometry and the objects ( ) in the Expected Audio Scene Geometry. 2. Compare the number of Audio Blocks in the Expected Transform Speech with the number of Audio Blocks in the Transform Speech Files. 3. Calculate Signal to Interference Ratio (SIR), Signal to Distortion Ratio (SDR), and Signal to Artefacts Ratio (SAR) between the Expected and Output Transform Speech Files [12]. 4. Accept the AIM under test if these four conditions are satisfied: a. The number of speech objects in the Audio Scene Geometry is equal to the number of speech objects in the Expected Audio Scene Geometry. b. The number of Audio Blocks in the Transform Speech is equal to the number of Audio Blocks in the Expected Transform Speech. c. Compare each Speech Object in the Audio Scene Geometry with the Speech Object in the Expected Audio Scene Geometry. i. Each object’s AD between the Expected and Output is less than 5 degrees. d. Compare each Speech Object in the Transform Speech with the Speech Object in the Expected Transform Speech. i. If the room reverb time (T60) is greater than 0.5 seconds. 1. Each object’s SIR between the Expected and Output is greater than or equal to 10 dB. 2. Each object’s SDR between the Expected and Output is greater than or equal to 3 dB. 3. Each object’s SAR between the Expected and Output is greater than or equal to 3 dB. ii. If the room reverb time (T60) is less than 0.5 seconds. 1. Each object’s SIR between the Expected and Output is greater than or equal to 15 dB. 2. Each object’s SDR between the Expected and Output is greater than or equal to 6 dB. 3. Each object’s SAR between the Expected and Output is greater than or equal to 6 dB. |
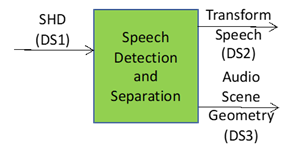
Figure 22 – Speech Detection and Separation Testing Flow
After the Tests, Performance Assessor shall fill out Table 56.Table 56
Table 56 – Performance Assessment form of Enhanced Audioconference Experience (CAE-EAE) Speech Detection and Separation
| Performance Assessor ID | Unique Performance Assessor Identifier assigned by MPAI | ||||||||||||||||||||||||||||||||||||||
| Standard, Use Case ID and Version | Standard ID and Use Case ID, Version and Profile of the standard in the form “CAE:EAE:1:0”. | ||||||||||||||||||||||||||||||||||||||
| Name of AIM | Speech Detection and Separation | ||||||||||||||||||||||||||||||||||||||
| Implementer ID | Unique Implementer Identifier assigned by MPAI Store. | ||||||||||||||||||||||||||||||||||||||
| AIM Implementation Version | Unique Implementation Identifier assigned by Implementer. | ||||||||||||||||||||||||||||||||||||||
| Neural Network Version* | Unique Neural Network Identifier assigned by Implementer. | ||||||||||||||||||||||||||||||||||||||
| Identifier of Performance Assessment Dataset | Unique Dataset Identifier assigned by MPAI Store. | ||||||||||||||||||||||||||||||||||||||
| Test ID | Unique Test Identifier assigned by Performance Assessor. | ||||||||||||||||||||||||||||||||||||||
| Actual output | The Performance Assessor will provide the following matrix containing a limited number of input records (n) with the corresponding outputs. If an input record fails, the tester would specify the reason why the test case fails.
Final evaluation : T/F Denoting with i, the record number in DS1, DS2, and DS3, the matrices reflect the results obtained with input records i with the corresponding outputs i.
|
||||||||||||||||||||||||||||||||||||||
| Execution time* | Duration of test execution. | ||||||||||||||||||||||||||||||||||||||
| Test comment* | Comments on test results and possible needed actions. | ||||||||||||||||||||||||||||||||||||||
| Test Date | yyyy/mm/dd. |
* Optional field