| 1. Function | 2. Reference Model | 3. Input/Output Data |
| 4. SubAIMs | 5. JSON Metadata | 6. Profiles |
| 7. Reference Software | 8. Conformance Testing | 9.Performance Assessment |
1. Function
- Receives Audio Segments for Modeling.
- Produces Natural Language Speech Model.
2. Reference Model
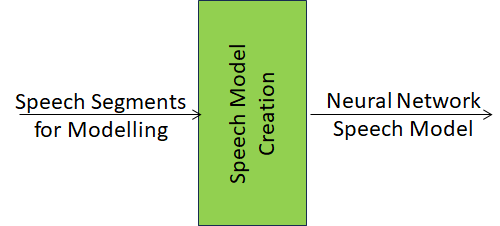
Figure 1 – Speech Model Creation (CAE-SMC) AIM
3. Input/Output Data
| Input data | Semantics |
| Audio Segments for Modelling | A set of Audio Files containing speech segments used to train the Neural Network Speech Model. |
| Output data | Semantics |
| Neural Network Speech Model | A Neural Network Model trained on Speech Segments for Modelling and used to synthesise replacements for the entire Damaged Segment or Damaged Sections within it. |
4. SubAIMs
No SubAIMs.
5. JSON Metadata
https://schemas.mpai.community/CAE1/V2.4/AIMs/SpeechModelCreation.json
6. Profiles
No Profiles
7. Reference Software
Not available.
8. Conformance Assessment
| Receives | Audio Segments for Modelling | Shall validate against the Audio Object schema. The Audio Segments for Modelling Qualifier shall validate against the Audio Qualifier schema. The values of any Sub-Type, Format, and Attribute of the Audio Segments for Modelling Qualifiers shall correspond with the Sub-Type, Format, and Attributes of the Audio Object Qualifier schema. |
| Produces | Neural Network Speech Model | Shall validate against ML Model schema. The Neural Network Speech Model Qualifier shall validate against the ML Model Qualifier Schema. The values of any Sub-Type, Format, and Attribute of the Neural Network Speech Model Qualifier shall correspond with the Sub-Type, Format, and Attributes of the ML Qualifier schema. |
9. Performance Assessment
Table 39 gives the Speech Restoration System (CAE-SRS) Speech Model Creation Means and how they are used.
Table 39 – AIM Means and use of Speech Restoration System (CAE-SRS) Speech Model Creation
| Means | Actions |
| Performance Assessment Dataset | DS1: a set of n Audio Segments, suitable input for creation of a Neural Network Speech Model for a specific speaker. |
| Procedure | 1. Pass Audio Segments for Modelling to Speech Module Creation AIM as input, according to its declared standard procedure.
2. Provide resulting Neural Network Speech Model as input to the reference Speech Synthesiser AIM (ID: ss). 3. Synthesise all texts in canonical Text List. |
| Evaluation | 1. Evaluate synthesis quality using Perception Evaluation of Speech Quality (PESQ).
2. If the score is above a threshold of 2.0, the Speech Model Creation AIM is judged adequate. 3. If the quality is below threshold, the submitter of Speech Model Creation is given the opportunity to submit an implementation of Speech Synthesiser. 4. The MPAI Store will test the combination of the two submitted AIMs. 5. If the quality of the output of the submitted combination is above threshold, Speech Model Creation passes the Performance Test as long as the corresponding Speech Synthesiser are made available to the MPAI Store. 6. Else, Speech Model Creation doesn’t pass the Performance Test. |
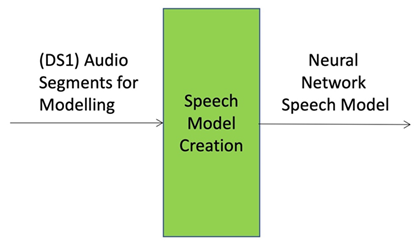
Figure 16 – Speech Model Creation.
After the Tests, Performance Assessor shall fill out Table 40.
Table 40 – Performance Assessment form of Speech Restoration System (SRS) Speech Model Creation.
| Performance Assessor ID | Unique Performance Assessor Identifier assigned by MPAI | ||||||||||||
| Standard, Use Case ID and Version | Standard ID and Use Case ID, Version and Profile of the standard in the form “CAE:SRS:1:0”. | ||||||||||||
| Name of AIM | Speech Model Creation | ||||||||||||
| Implementer ID | Unique Implementer Identifier assigned by MPAI Store. | ||||||||||||
| AIM Implementation Version | Unique Implementation Identifier assigned by Implementer. | ||||||||||||
| Neural Network Version* | Unique Neural Network Identifier assigned by Implementer. | ||||||||||||
| Identifier of Performance Assessment Dataset | Unique Dataset Identifier assigned by MPAI Store. | ||||||||||||
| Test ID | Unique Test Identifier assigned by Performance Assessor. | ||||||||||||
| Actual output | Actual output provided as a matrix of n rows containing output assertions.
For example:
Final evaluation: T/F Legend: – #: Speech Model Creation input dataset tuple number. – DS1: Audio Segments for Modelling – Final assertion: T if Neural Network Speech Model is well-formed, else F – Final evaluation: T if all Final assertions are T, else F |
||||||||||||
| Execution time* | Duration of test execution. | ||||||||||||
| Test comment* | Comments on test results and possible needed actions. | ||||||||||||
| Test Date | yyyy/mm/dd. |
* Optional field