| 1. Function | 2. Reference Model | 3. Input/Output Data |
| 4. SubAIMs | 5. JSON Metadata | 6. Profiles |
| 7. Reference Software | 8. Conformance Testing | 9.Performance Assessment |
1. Function
| Receives | Damaged Segment | A Damaged Segment. |
| Damaged List | The list of Damaged Segments. | |
| Synthesised Speech | To be used as replacement of Damaged Segment. | |
| Produces | Restored Segment | The Restored Segment to be used used in lieu of Damaged Segments. |
2. Reference Model
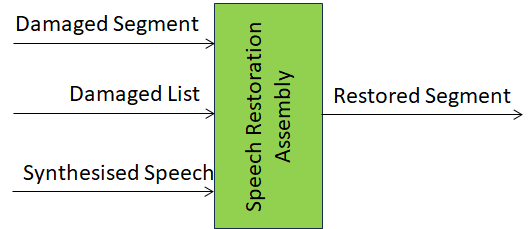
Figure 1 – Speech Restoration Assembly
3. Input/Output Data
| Input data | Semantics |
| Damaged Segment | An Audio Segment containing only speech (and not containing music or other sounds) which is either damaged in its entirety or contains one or more Damaged Sections specified in the Damaged List. |
| Damaged List | List of Damaged Segments. |
| Synthesised Speech | Speech synthesised by Neural Network Speech Model. |
| Output data | Semantics |
| Restored Speech Segment | Speech synthesised by Speech Restoration Assembly |
4. SubAIMs
No SubAIMs.
5. JSON Metadata
https://schemas.mpai.community/CAE1/V2.4/AIMs/SpeechRestorationAssembly.json
6. Profiles
No Profiles.
7. Reference Software
8. Conformance Testing
| Receives | Damaged Segment | Shall validate against the Audio Object schema. The Qualifier shall validate against the Audio Qualifier schema. The values of any Sub-Type, Format, and Attribute of the Damaged Segment Qualifiers shall correspond with the Sub-Type, Format, and Attributes of the Audio Object Qualifier schema. |
| Damaged List | Shall validate against the Damaged List schema. The Time shall validate against the Time schema. |
|
| Synthesised Speech | Shall validate against the Audio or Speech Object schema. The Qualifier shall validate against the Audio or Speech Qualifier schema. The values of any Sub-Type, Format, and Attribute of the Synthesised Speech Qualifier shall correspond with the Sub-Type, Format, and Attributes of the Audio or Speech Object Qualifier schema. |
|
| Produces | Restored Speech Segment | Shall validate against the Audio or Speech Object schema. The Qualifier shall validate against the Audio or Speech Qualifier schema. The values of any Sub-Type, Format, and Attribute of the Restored Speech Segment Qualifier shall correspond with the Sub-Type, Format, and Attributes of the Audio or Speech Object Qualifier schema. |
9. Performance Assessment
Table 45 gives the Speech Restoration System (CAE-SRS) Speech Restoration Assembly Means and how they are used.
Table 45 – AIM Means and use of Speech Restoration System (CAE-SRS) Speech Restoration Assembly
| Means | Actions |
| Performance Assessment Dataset | DS1: a canonical set of n Damaged Segments
DS2: a canonical set of n Damaged Lists DS3: a canonical set of n Synthesised Speeches. |
| Procedure | 1. Pass DS1, DS2 and DS3 to Assembler, according to its declared standard Procedure.
2. Perform all specified assembly operations: Synthesised Speech results shall replace all bad sections of Damaged Segment as specified by Damaged List. |
| Evaluation | 1. Restored Segment shall be evaluated for quality using Perception Evaluation of Speech Quality (PESQ). Restoration shall be seamless, so that listeners are unable to reliably identify locations of repaired sections.
2. If the scores exceed a declared threshold, Assembler is judged adequate. 3. Else, Assembler doesn’t pass the Performance Assessment. |
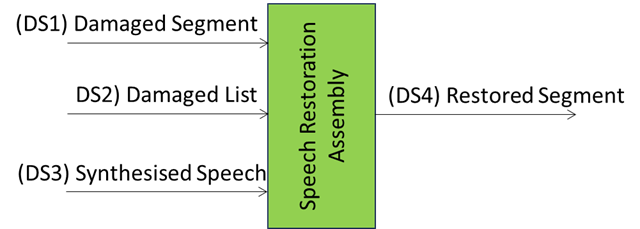
Figure 18 – Speech Restoration Assembly.
After the Assessment, Performance Assessor shall fill out Table 46.
Table 46 – Performance Assessment form of Speech Restoration System (SRS) Speech Restoration Assembly.
| Performance Assessor ID | Unique Performance Assessor Identifier assigned by MPAI | ||||||||||||
| Standard, Use Case ID and Version | Standard ID and Use Case ID, Version and Profile of the standard in the form “CAE:SRS:V:P”. | ||||||||||||
| Name of AIM | Assembler | ||||||||||||
| Implementer ID | Unique Implementer Identifier assigned by MPAI Store. | ||||||||||||
| AIM Implementation Version | Unique Implementation Identifier assigned by Implementer. | ||||||||||||
| Neural Network Version* | Unique Neural Network Identifier assigned by Implementer. | ||||||||||||
| Identifier of Performance Assessment Dataset | Unique Dataset Identifier assigned by MPAI Store. | ||||||||||||
| AssessmentID | Unique Assessment Identifier assigned by Performance Assessor. | ||||||||||||
| Actual output | Actual output provided as a matrix of n rows containing output assertions.
For example:
Final evaluation: T/F Legend: – #: Assembler input dataset tuple number. – DS1: Damaged Segment (within which damaged sub-segments may be listed) – DS2: Damaged List (of damaged sub-segments within current Damaged Segment) – DS3: Synthesised Speech (list of synthesised sub-segments corresponding to damaged sub-segments of DL) – Final assertion: T if Restored Segment is well-formed (single audio file without audible interruptions or gaps, produced without error messages or breaks), else F – Final evaluation: T if all Final assertions are T, else F |
||||||||||||
| Execution time* | Duration of Assessment execution. | ||||||||||||
| Assessment comment* | Comments on Assessment results and possible needed actions. | ||||||||||||
| Assessment Date | yyyy/mm/dd. |
* Optional field