1 Functions of Conversation with Personal Status
2 Reference Architecture of Conversation with Personal Status
3 I/O Data of Conversation with Personal Status
4 Functions of AI Modules of Conversation with Personal Status
5 I/O Data of AI Modules of Conversation with Personal Status
6 JSON Metadata of Conversation with Personal Status
1 Functions of Conversation with Personal Status
When humans have a conversation with other humans, they use speech and, in constrained cases, text. Their interlocutors perceive speech and/or text supplemented by visual information related to the speaker’s face and gesture of a conversing human. Text, speech, face, and gesture may convey information about the internal state of the speaker that MPAI calls Personal Status. Therefore, handling of Personal Status information in a human-machine conversation and, in the future, even machine-machine conversation, is a key feature of a machine trying to understand what the speakers’ utterances mean because Personal Status recognition can improve understanding of the speaker’s utterance and help a machine produce better replies.
Conversation with Personal Status (MMC-CPS) is a general Use Case of an entity – a real or digital human – conversing and question answering with a machine. The machine captures and understands Speech, extracts Personal Status from the Text, Speech, Face, and Gesture Factors, fuses the Factors into an estimated Personal Status of the entity to achieve a better understanding of the context in which the entity utters Speech.
2 Reference Architecture of Conversation with Personal Status
Figure 1 gives the Conversation with Personal Status Reference Model including the input/output data, the AIMs, and the data exchanged between and among the AIMs.
The operation of the Conversation with Personal Status Use Case develops as follows:
- Input Selector is used to inform the machine whether the human employs Text or Speech in conversation with the machine.
- Visual Scene Description extracts the Scene Geometry, the Visual Objects and the Face and Body Descriptors of humans in the Scene.
- Audio Scene Description extracts the Scene Geometry, and the Speech Objects in the Scene.
- Visual Object Identification assigns an Identifier to each Visual Object indicated by a human.
- Audio-Visual Alignment uses the Audio Scene Description and Visual Scene Description to assign unique Identifiers to Audio, Visual, and Audio-Visual Objects.
- Automatic Speech Recognition recognises Speech utterances.
- Natural Language Understanding refines Text and extracts Meaning.
- Personal Status Extraction extracts a human’s Personal Status.
- Entity Dialogue Processing produces the machine’s response and its Personal Status.
- Personal Status Display produces a speaking Avatar expressing Personal Status.
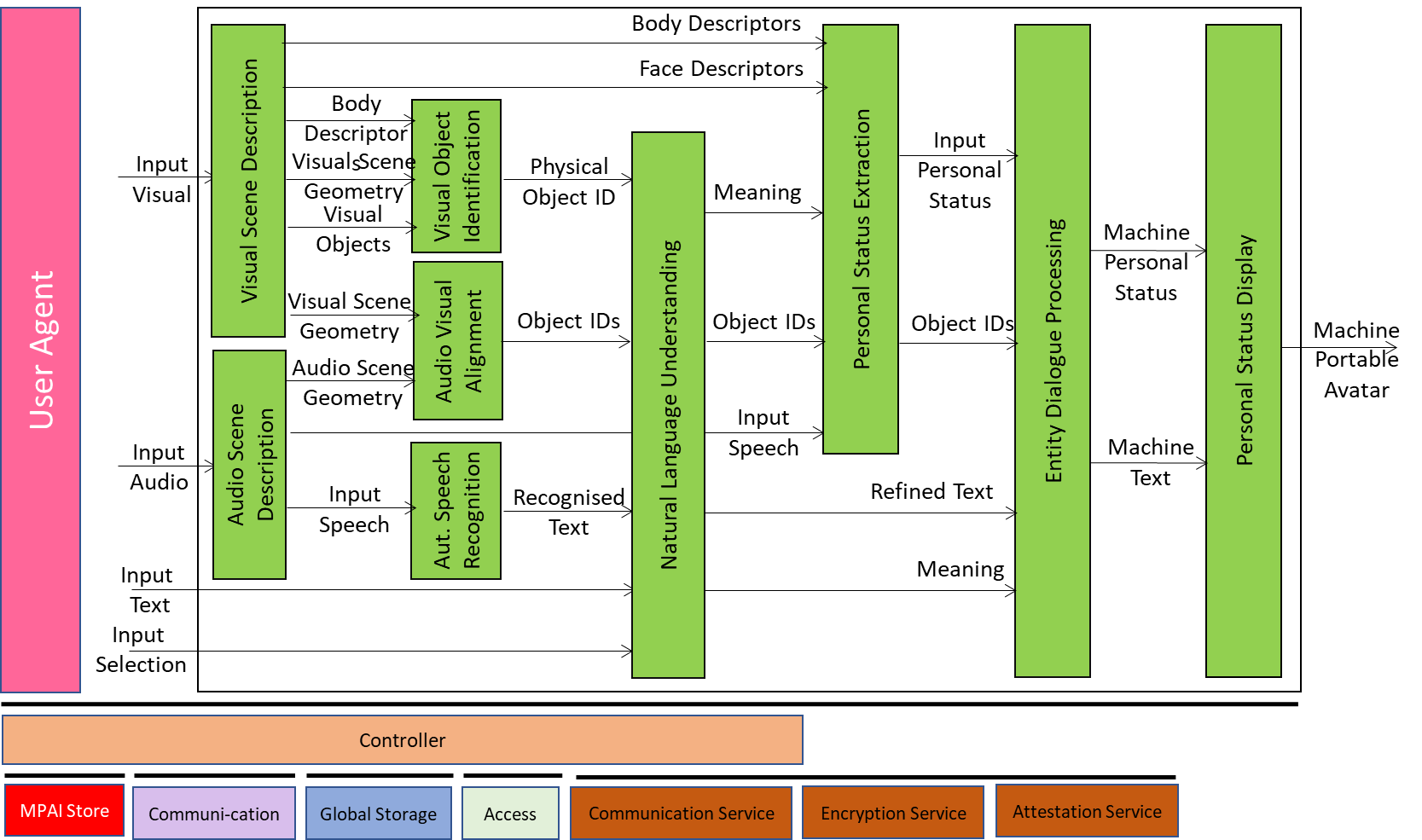
Figure 1 – Reference Model of Conversation with Personal Status
The operation of the Conversation with Personal Status Use Case develops as follows:
- Input Selector is used to inform the machine whether the human employs Text or Speech in conversation with the machine.
- Visual Scene Description extracts the Scene Geometry, the Visual Objects and the Face and Body Descriptors of humans in the Scene.
- Audio Scene Description extracts the Scene Geometry, and the Speech Objects in the Scene.
- Visual Object Identification assigns an Identifier to each Visual Object indicated by a human.
- Audio-Visual Alignment uses the Audio Scene Description and Visual Scene Description to assign unique Identifiers to Audio, Visual, and Audio-Visual Objects.
- Automatic Speech Recognition recognises Speech utterances.
- Natural Language Understanding refines Text and extracts Meaning.
- Personal Status Extraction extracts a human’s Personal Status.
- Entity Dialogue Processing produces the machine’s response and its Personal Status.
- Personal Status Display produces a speaking Avatar expressing Personal Status.
3 I/O Data of Conversation with Personal Status
Table 1 gives the input and output data of the Conversation with Personal Status Use Case:
Table 1 – I/O Data of Conversation with Personal Status
| Input | Descriptions |
| Input Text | Text typed by the human as additional information stream or as a replacement of the Speech. |
| Input Speech | Speech of the human having a conversation with the machine. |
| Input Visual | Visual information of the Face and Body of the human having a conversation with the machine. |
| Input Selector | Data determining the use of Speech vs Text. |
| Output | Descriptions |
| Machine Portable Avatar | The representation of the Machine response. |
4 Functions of AI Modules of Conversation with Personal Status
Table 2 provides the functions of the Conversation with Personal Status Use Case.
Table 2 – Functions of AI Modules of Conversation with Personal Status
| AIM | Function |
| Visual Scene Description | 1. Receives Input Visual. 2. Provides Visual Objects and Visual Scene Geometry. |
| Audio Scene Description | 1. Receives Input Audio. 2. Provides Speech Objects and Audio Scene Geometry. |
| Visual Object Identification | 1. Receives Visual Scene Geometry, Body Descriptors, and Visual Objects. 2. Provides Visual Object Instance IDs. |
| Automatic Speech Recognition | 1. Receives Input Speech. 2. Extracts Recognised Text. |
| Natural Language Understanding | 1. Receives Recognised Text. 2. Refines Text and extracts Meaning. |
| Personal Status Extraction | 1. Receives Meaning, Refined Text, Body Descriptors, and Face Descriptors. 2. Extracts Personal Status. |
| Entity Dialogue Processing | 1. Receives Refined Text and Personal Status. 2. Produces machine’s Text and Personal Status. |
| Personal Status Displays | 1. Receives Machine Text and Personal Status. 2. Synthesises Machine Portable Avatar. |
5 I/O Data of AI Modules of Conversation with Personal Status
Table 3 provides the I/O Data of the AI Modules of the Conversation with Personal Status Use Case.
Table 3 – I/O Data of AI Modules of Conversation with Personal Status
| AIM | Receives | Produces |
| Visual Scene Description |
1. Input Visual |
1. Face Descriptors 2. Body Descriptors 3. Visual Scene Geometry 4. Visual Objects |
| Audio Scene Description | 1. Input Audio | 1. Speech 2. Audio Scene Geometry |
| Visual Object Identification | 1. Body Descriptors 2. Visual Scene Geometry 3. Visual Objects |
1. Visual Object ID |
| Automatic Speech Recognition | 1. Input Speech | 1. Recognised Text |
| Natural Language Understanding | 1. Visual Object ID 2. Input Speech 3. Recognised Speech 4. Input Selector |
1. Meaning 2. Refined Speech |
| Personal Status Extraction | 1. Body Descriptors 2. Face Descriptors 3. Meaning4. Speech |
1. Input Personal Status |
| Entity Dialogue Processing | 1. Input Speech 2. Refined Speech 3. Input Personal Status 4. Input Selector |
1. Machine Personal Status 2. Machine Speech |
| Personal Status Displays | 1. Machine Speech 2. Machine Personal Status |
1. Machine Portable Avatar |
6 JSON Metadata of Conversation with Personal Status
Table 4 – Acronyms and URLs of JSON Metadata
| MMC-CPS | Conversation With Personal Status | X | ||
| MMC-SSD | Speech Scene Description | X | ||
| OSD-VSD | Visual Scene Description | X | ||
| OSD-VOI | Visual Object Identification | X | ||
| OSD-VDI | Visual Direction Identification | X | ||
| OSD-VOE | Visual Object Extraction | X | ||
| OSD-VII | Visual Instance Identification | X | ||
| MMC-ASR | Automatic Speech Recognition | X | ||
| MMC-NLU | Natural Language Understanding | X | ||
| MMC-PSE | Personal Status Extraction | X | ||
| MMC-ITD | Entity Text Description | X | ||
| MMC-ISD | Entity Speech Description | X | ||
| PAF-IFD | Entity Face Description | X | ||
| PAF-IBD | Entity Body Description | X | ||
| MMC-PTI | PS-Text Interpretation | X | ||
| MMC-PSI | PS-Speech Interpretation | X | ||
| PAF-PFI | PS-Face Interpretation | X | ||
| PAF-PGI | PS-Gesture Interpretation | X | ||
| MMC-PMX | Personal Status Multiplexing | X | ||
| MMC-EDP | Entity Dialogue Processing | X | ||
| PAF-PSD | Personal Status Display | X | ||
| MMC-TTS | Text-to-Speech | X | ||
| PAF-IFD | Entity Face Description | X | ||
| PAF-IBD | Entity Body Description | X | ||
| PAF-PMX | Portable Avatar Multiplexing | X | ||
| OSD-AVA | Audio-Visual Alignment | X |