| 1 Function | 2 Reference Model | 3 Input/Output Data |
| 4 SubAIMs | 5 JSON Metadata | 6 Profiles |
| 7 Reference Software | 8 Conformance Texting | 9 Performance Assessment |
1 Functions
Audio Segmentation (MMC-AUS):
| Receives | Audio Object |
| Identifies | Speech Time |
| Extracts | Target Speech Object |
| Detects | Speech Overlap |
| Produces | Speech Time |
| Speech Overlap | |
| Speech Objects each including a Speaker’s Turn, i.e., one or more adjacent utterances from the same Speaker. |
2 Reference Model
Figure 1 depicts the Reference Model of the Audio Segmentation AIM.
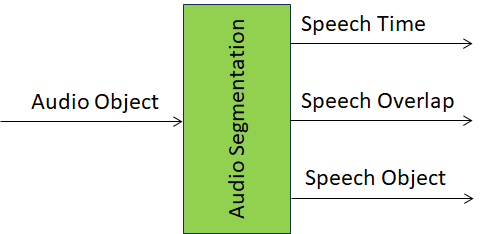
Figure 1 – Reference Model of Audio Segmentation AIM
3 Input/Output Data
Table 1 specifies the Input and Output Data of the Audio Segmentation AIM.
Table 1 – I/O Data of the Audio Segmentation AIM
| Input | Description |
| Speech File | Input Speech file. |
| Output | Description |
| Speaker Time | Time one or more Speakers start speaking. |
| Speech Overlap | Number of overlapping speakers. |
| Speech Object | Speech Object containing the utterance(s) of the Speaker(s). |
4 SubAIMs
No SubAIMs
5 JSON Metadata
https://schemas.mpai.community/MMC/V2.2/AIMs/AudioSegmentation.json
6 Profiles
No Profiles.
7 Reference Software
7.1 Disclaimers
- This MMC-AUS Reference Software Implementation is released with the BSD-3-Clause licence.
- The purpose of this MMC-AUS Reference Software is to show a working Implementation of OSD-AUS, not to provide a ready-to-use product.
- MPAI disclaims the suitability of the Software for any other purposes and does not guarantee that it is secure.
- Use of this Reference Software may require acceptance of licences from the respective repositories. Users shall verify that they have the right to use any third-party software required by this Reference Software.
7.2 Guide to the code
MMC-AUS splits the input WAV file into speech segments – called speakers’ turns – a belonging to one – still unidentified speaker. See see “start and end times of each speaker’s turn, as well as the speaker labels” at https://www.aimodels.fyi/models/huggingFace/speaker-diarization-pyannote. A turn is defined as a sequence of one or more speech segments belonging to the same speaker. See https://dokumen.pub/speech-recognition-technology-and-applications-9798886971798.html.
Use of this Reference Software for MMC-AUS AI Module is for developers who are familiar with Python, Docker, RabbitMQ, and downloading models from HuggingFace.
The MMC-AUS Reference Software is found at the MPAI gitlab site. It contains:
- src: a folder with the Python code implementing the AIM
- Dockerfile: a Docker file containing only the libraries required to build the Docker image and run the container
- requirements.txt: dependencies installed in the Docker image
- README.md: commands for cloning https://huggingface.co/speechbrain/spkrec-ecapa-voxceleb and https://huggingface.co/pyannote/segmentation
- diar_conf.yaml: YML setting up a diarization pipeline. Copy it to $AI_FW_DIR/confs/mmc_aus
Library: https://github.com/pyannote/pyannote-audio
7.3 Acknowledgements
This version of the OSD-AUS Reference Software has been developed by the MPAI AI Framework Development Committee (AIF-DC).