<-Go to AI Workflows Go to ToC Conversation with Personal Status->
| 1 Functions | 2 Reference Model | 3 I/O Data |
| 4 Functions of AI Modules | 5 I/O Data of AI Modules | 6 AIW, AIMs, and JSON Metadata |
| 7 Reference Software | 8 Conformance Testing | 9 Performance Assessment |
1 Functions
This Use Case addresses the case of a human holding a conversation with a Machine:
- The human converses with the Machine indicating the object in the Environment s/he wishes to talk to or ask questions about it using Speech, Face, and Gesture.
- The Machine
- Sees and hears an Environment containing a speaking human and some scattered objects.
- Recognises the human’s Speech and obtains the human’s Personal Status by capturing Speech, Face, and Gesture.
- Understands which object the human is referring to and generates an avatar that:
- Utters Speech conveying a synthetic Personal Status that is relevant to the human’s Personal Status as shown by his/her Speech, Face, and Gesture, and
- Displays a face conveying a Personal Status that is relevant to the human’s Personal Status and to the response the Machine intends to make.
- Renders the Scene that it perceives from a human-selected Point of View. The objects in the scene are labelled with the Machine’s understanding of their semantics so that the human can understand how the Machine sees the Environment.
2 Reference Model
Figure 1 gives the Conversation About a Scene Reference Model including the input/output data, the AIMs, and the data exchanged between and among the AIMs.
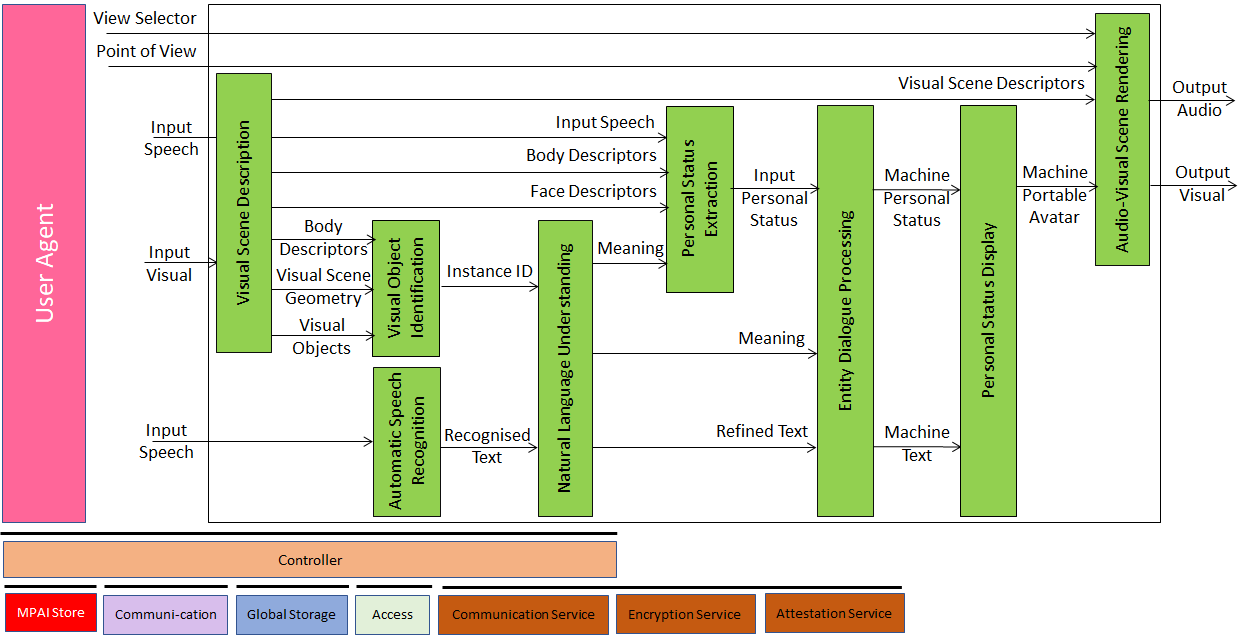
Figure 1 – Reference Model of Conversation About a Scene (MMC-CAS) AIM
The Machine operates according to the following workflow:
- Visual Scene Description produces Body Descriptors, Visual Scene Geometry and Visual Objects from Input Visual.
- Automatic Speech Recognition produces Recognised Text from Input Speech.
- Visual Object Identification produces Visual Object Instance ID from Visual Objects, Body Descriptors, and Visual Scene Geometry.
- Natural Language Understanding produces Meaning and Refined Text from Recognised Text and Visual Object ID.
- Personal Status Extraction produces Input Personal Status from Meaning, Input Speech, Face Descriptors, and Body Descriptors.
- Entity Dialogue Processing produces Machine Text and Machine Personal Status from Input Personal Status, Meaning, and Refined Text.
- Personal Status Display produces Machine Portable Avatar from Machine Text, and Machine Personal Status.
- Audio-Visual Scene Rendering renders the Audio-Visual Scene
- Described by the Visual Scene Descriptors.
- Integrated by the Machine’s Portable Avatar information depending on View Selector.
- As seen from the human-selected Point of View.
3 I/O Data
Table 1 gives the input/output data of Conversation About a Scene.
Table 1 – I/O data of Conversation About a Scene
| Input data | From | Description |
| View Selector | Human | Selects whether Machine is rendered in the scene |
| Input Visual | Camera | Points to human and scene. |
| Input Speech | Microphone | Speech of human. |
| Point of View | Human | The point of view of the Audio-Visual Scene displayed by Audio-Visual Scene Rendering. |
| Output data | To | Descriptions |
| Output Visual | Human | Rendering of the Visual Scene containing labelled objects, human, and Machine depending on View Selector as perceived by Machine and seen from the Point of View. |
| Output Speech | Human | Speech of Portable Avatar produced by Machine. |
4 Functions of AI Modules
Table 2 provides the functions of the Conversation About a Scene Use Case.
Table 2 – Functions of AI Modules of Conversation About a Scene
| AIM | Functions |
| Visual Scene Description | 1. Receives Input Visual 2. Provides Visual Objects and Visual Scene Geometry. |
| Visual Object Identification | 1. Receives Body Descriptors and non-human Visual Objects 2. Provides the Instance ID of the Visual Object indicated by the human. |
| Automatic Speech Recognition | 1. Receives Input Speech 2. Provides Recognised Text. |
| Natural Language Understanding | 1. Receives Instance ID and Recognised Text 2. Refines Text and extracts Meaning. |
| Personal Status Extraction | 1. Receives Input Speech, Body Descriptors, Face Descriptors, and Meaning. 2. Provides Personal Status. |
| Entity Dialogue Processing | 1. Receives Refined Text and Personal Status. 2. Produces Machine’s Text and Personal Status. |
| Personal Status Display | 1. Receives Machine’s Personal Status and Text. 2. Provides Machine Portable Avatar. |
| Audio-Visual Scene Rendering | 1. Receives the Descriptors of the Visual Scene perceived by Machine including the Portable Avatar of the Personal Status Display. 2. Renders the Audio-Visual Scene from the Point of View selected by human. |
5 I/O Data of AI Modules
Table 3 gives the list of AIMs with their I/O Data.
Table 3 – AI Modules of Conversation About a Scene
| AIM | Receives | Produces |
| Visual Scene Description | Input Visual | 1. Visual Scene Descriptors 2. Body Descriptors 3. Face Descriptors 4. Visual Scene Geometry 5. Visual Objects |
| Visual Object Identification | 1. Body Object 2. Visual Objects 3. Visual Scene Geometry |
1. Visual Object Instance Identifier |
| Automatic Speech Recognition | 1. Input Speech | 1. Recognised Text |
| Natural Language Understanding | 1. Recognised Text 2. Visual Object Instance Identifier |
1. Meaning 2.Refined Text |
| Personal Status Extraction | 1. Body Object 2. Face Object 3. Input Speech 4. Meaning |
1. Personal Status |
| Entity Dialogue Processing | 1. Personal Status 2. Meaning 3. Visual Object ID 4. Refined Text |
1. Machine Personal Status |
| Personal Status Display | 1. Machine Text 2. Machine Personal Status |
1. Machine Portable Avatar |
| Audio-Visual Scene Rendering | 1. Visual Scene Descriptors 2. Point of View |
1. Output Speech 2. Output Visual |
6 AIW, AIMs, and JSON Metadata and AIMs
Table 4 provides the links to the AIW and AIM specifications and to the JSON syntaxes. AIMs/1 indicates that the column contains Composite AIMs and AIMs/2 indicates that the column contains their Basic AIMs.
Table 4 – AIW, AIMs, and JSON Metadata
| AIW | AIMs/1 | AIMs/2 | Name | JSON |
| MMC-CAS | Conversation About a Scene | X | ||
| OSD-VSD | Visual Scene Description | X | ||
| OSD-VOI | Visual Object Identification | X | ||
| OSD-VDI | Visual Direction Identification | X | ||
| OSD-VOE | Visual Object Extraction | X | ||
| OSD-VII | Visual Instance Identification | X | ||
| MMC-ASR | Automatic Speech Recognition | X | ||
| MMC-NLU | Natural Language Understanding | X | ||
| MMC-PSE | Personal Status Extraction | X | ||
| MMC-ETD | Entity Text Description | X | ||
| MMC-ESD | Entity Speech Description | X | ||
| PAF-EFD | Entity Face Description | X | ||
| PAF-EBD | Entity Body Description | X | ||
| MMC-PTI | PS-Text Interpretation | X | ||
| MMC-PSI | PS-Speech Interpretation | X | ||
| PAF-PFI | PS-Face Interpretation | X | ||
| PAF-PGI | PS-Gesture Interpretation | X | ||
| MMC-PMX | Personal Status Multiplexing | X | ||
| MMC-EDP | Entity Dialogue Processing | X | ||
| OSD-PSD | Personal Status Display | X | ||
| MMC-TTS | Text-to-Speech | X | ||
| PAF-EFD | Entity Face Description | X | ||
| PAF-EBD | Entity Body Description | X | ||
| PAF-PMX | Portable Avatar Multiplexing | X | ||
| PAF-AVR | Audio-Visual Scene Rendering | X |
7 Reference Software
8 Conformance Testing
9 Performance Assessment
<-Go to AI Workflow Go to ToC Conversation with Personal Status->