| CAE | CAV | HMC | MMC | OSD | PAF |
| AI Workflows | AI Modules |
1 AI Workflows
1.1 Television Media Analysis
OSD-TMA is a PAAI including a variety of collaborating PAAIs:
| TV Splitting | Separates the audio and visual (video) components of a multiplexed audio-visual (television) stream also using Text related to the contents of the audio-visual file. |
| Visual Change Detection | Separates the audio-visual file in files that represents different scenes. |
| Audio Segmentation | Separates the audio file in files where the Speaker IDs are different. |
| Face ID Recognition | Extracts human participants in a scene in bounding boxes using the input Auxiliary Text. |
| Speaker ID Recognition | Provides the ID of a Speaker. |
| Automatic Speech Recognition | Converts speech into text facilitated by Auxiliary Text. |
| Audio-Visual Alignment | Combines a face with a speaker. |
| Audio-Visual Scene Description | Combines all elements generated upstream into AV Scene Descriptors. |
| Audio-Visual Event Description | Stacks all the Scene Descriptors for the duration of the analysis. |
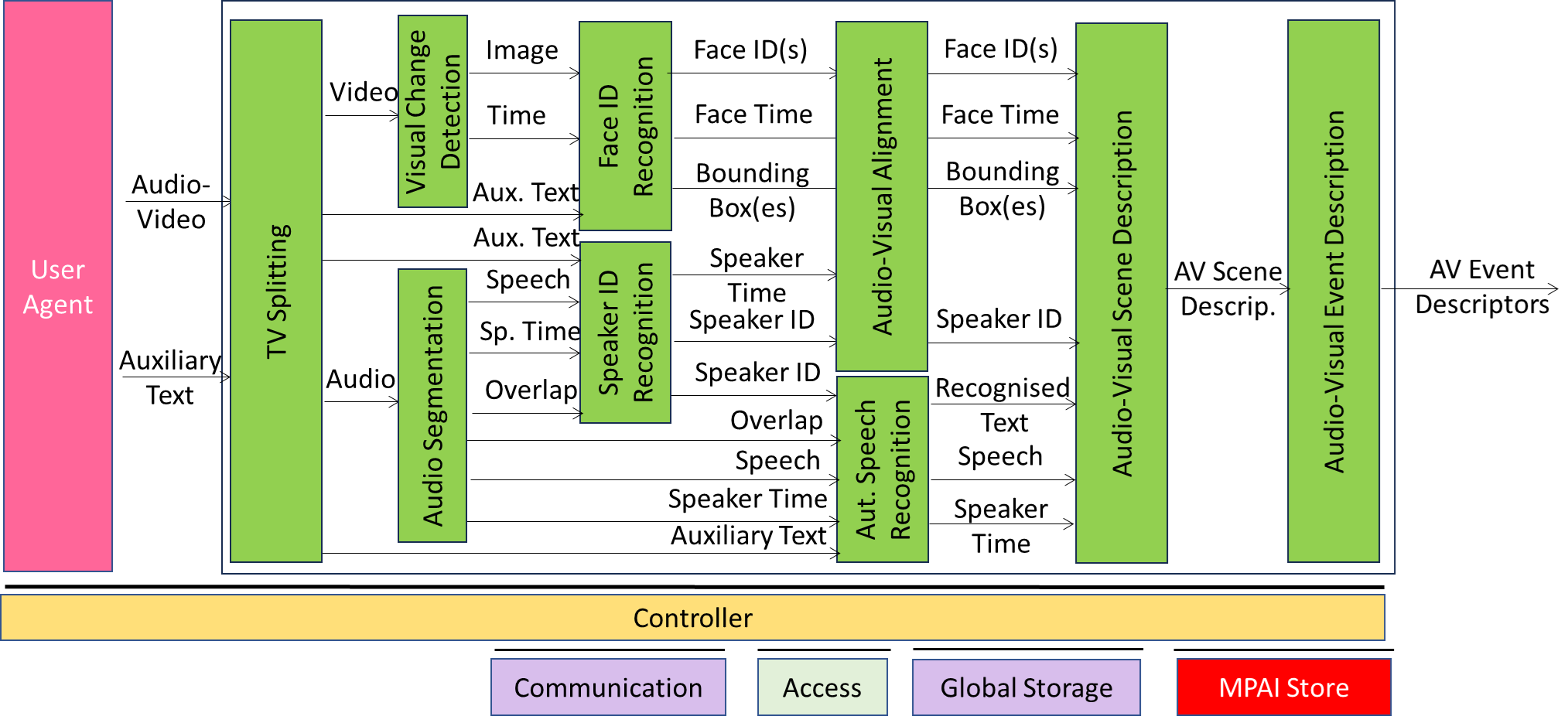
Figure 1 – Reference Model of OSD-TMA
The following links analyse the AI Modules:
- Audio Segmentation
- Audio-Visual Alignment
- Audio-Visual Event Description
- Audio-Visual Scene Description
- Automatic Speech Recognition
- Face Identity Recognition
- Speaker Identity Recognition
- Television Splitting
- Visual Change Detection
- Visual Object Identification
- Visual Scene Description
OSD-TMA performs Descriptors-Interpretation Level Operations.
2 AI Modules
2.1 Audio-Visual Alignment
OSD-AVA
| Receives | Speech Scene Descriptors | of a present Speech Scene. |
| Audio Scene Descriptors | of a present Audio Scene. | |
| Visual Scene Descriptors | of a present Visual Scene. | |
| Identifies | Speech-Audio-Visual Objects | that share the same Position. |
| Produces | Audio-Visual Scene Descriptors | whose Speech, Audio, and Visual Objects at the same Position have compatible Identifiers. |
OSD-AVA performs Descriptors Level Operations. More complex situations may require Reasoning Level Operations.
2.2 Visual Object Identification
OSD-VOI
| Receives | Visual Scene Geometry | The arrangement of the Visual Objects in the Scene. |
| Visual Objects | The Visual Objects in the Scene. | |
| Body Descriptors | The Descriptors of the Body indicating the object. | |
| Produces | Visual Instance ID | The ID of the Visual Object in the Scene crossed by he line of the Point of View of the Body. |
OSD-VOI is a PAAI including three collaborating PAAIs:
- OSD-VDI
- Analyses the Body.
- Finds the index fingers that points to an object.
- Assigns the direction of the finger to the Point of View.
- OSD-VOE follows the line until it crosses a Visual Object.
- OSD-VII recognises the identity of the Visual Object.
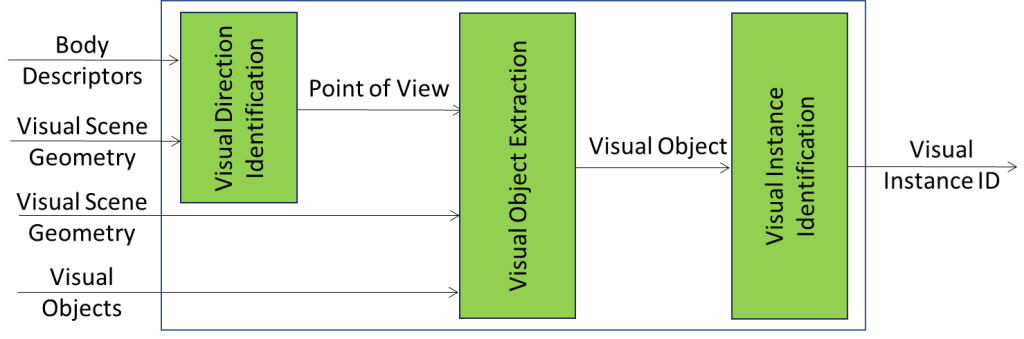
Figure 2 – The Visual Object Identification (OSD-VOI) Composite AIM
OSD-VOI performs Descriptors (OSD-VDI and OSD-VOE) and Interpretation Operations.
2.3 Visual Scene Description
Visual Scene Description (OSD-VSD) is a PAAI produces the Descriptors of a Scene composed by Visual Objects and Visual Scenes:
| Receives | Space-Time | of the input Visual Objects having the same time base. |
| Visual Objects | The Visual Object(s) to be converted to Scene Descriptors | |
| Scene Descriptors | Scene Descriptors possibly of different media co-located with the Visual Objects | |
| Merges | Visual Scene Descriptors | Into a single set of Visual Scene Descriptors. |
| Produces | Visual Scene Descriptors | Output#1 of AIM |
| Alert | Output#2 of AIM signalling potential anomalies in Object. |
OSD-VSD
- Receives the Visual Objects with their Space-Time information. As exemplified by CAV-ESS, the OSD-VSD may rely on a collaborative process with other AIMs producing Scene Descriptors provided by other EST-specific Scene Descriptions (not necessarily visual). In turn, they are assisted by OSD-VSD-produced Visual Scene Descriptions.
- Analyses the individual Visual Objects and may
- Discover sudden changes in the Visual Scene (e.g., the sudden appearance of a previously occluded Traffic Signal or traffic agent).
- Extract portions and add Annotations to it, such as the text of a Traffic Sign, the paddle of a traffic agent, etc.
OSD-VSD performs Descriptors Level Operations.