MPAI has approved Technical Specification: AI-Enhanced Video Coding (MPAI-EVC) – Up-sampling Filter for Video applications (EVC-UFV).
The standard includes a general procedure to design video up-sampling filters based on super resolution techniques and a method to reduce the complexity of the designed filters without significant performance loss. The standard also provides the parameters of specific filters for standard definition to high definition and high definition to ultra-high definition, for the complexity-reduced and original cases.
The standard will be presented online on 23 July at 13 UTC. Register here to attend the presentation.
The standard is not in final form. It is published with a request for Community Comments according to MPAI procedures. Comments should be sent the MPAI Secretariat by 2025/08/18 T23:59 UTC.
A method typically used in video coding is to down-sample to half the input video frame before encoding. This reduces the computational cost but requires an up-sampling filter to recover the original video resolution in the decoded video to reduce as much as possible the loss in visual quality. Currently used filters are bicubic and Lanczos,
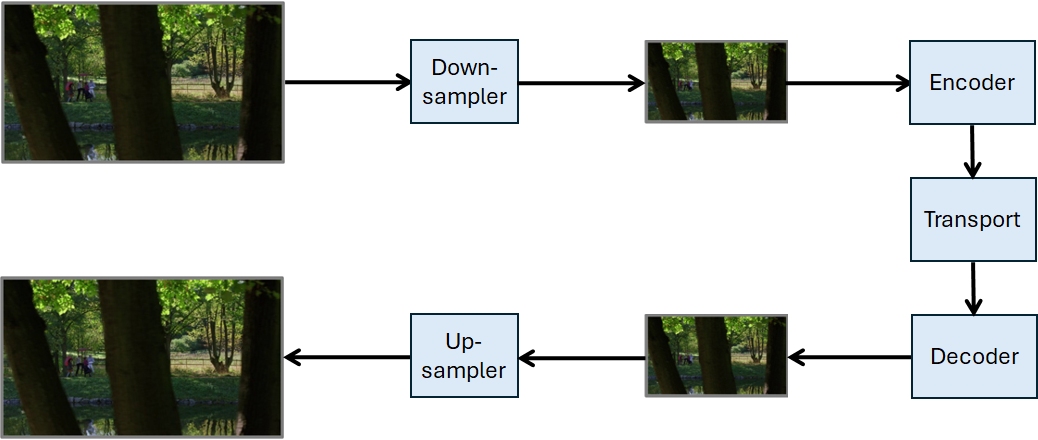
Figure 1 – Up-sampling Filters for Video application (EVC-UFV)
In the last few years, Artificial Intelligence (AI), Machine Learning (ML), and especially Deep Learning (DL) techniques, have demonstrated their capability to enhance the performance of various image and video processing tasks. MPAI has performed an investigation to assess how video coding performance could be improved by replacing traditional coding blocks with deep-learning ones. The outcome of this study has shown that deep-learning based up-sampling filters significantly improve the performance of existing video codecs.
MPAI issued a Call for Technologies for up-sampling filters for video applications in October 2024. This was followed by an intense phase of development that enabled MPAI to approve Technical Specification: AI-Enhanced Video Coding (MPAI-EVC) – Up-sampling Filter for Video application (EVC-UFV) V1.0 with a request for Community Comments at its 58th General Assembly (MPAI-58).
EVC-UFV standard enables efficient and low complexity up-sampling filters applied to video with different bit-depth of 8 and 10 bit per pixels per component, in standard YCbCr colour space with 4:2:0 sub-sampling, encoded with a variety of encoding technologies using different encoding features such as random access and low delay.
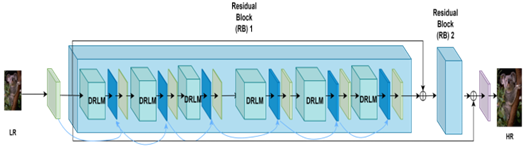
As depicted in Figure 2, the filter is a Densely Residual Laplacian Super-Resolution network (DRLN), offering a novel deep-learning approach.
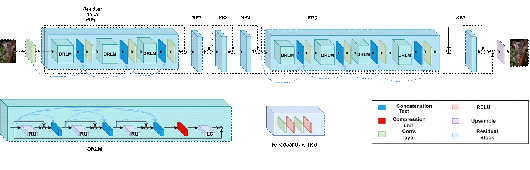
Figure 2 – Densely Residual Laplacian Super-Resolution network (DRLN).
The complexity of the filter is reduced in two steps. First, a drastic simplification of the deep-learning structure that reduces the numbers of blocks provides a much lighter network while keeping similar performances of the baseline DRLN. This is achieved by identifying the DRLN’s principal components and understanding the impact of each component on the output video frame quality, memory size, and computational costs.
As shown in Figure 2, the main component of the DRLN architecture is a Residual Block which is composed of the Densely Residual Laplacian Modules (DRLM) and a convolutional layer. Each DRLM contains three Residual Units, as well as one compression unit and one Laplacian attention unit (a set of Convolutional Layers with a square filter size and Dilation that is greater than or equal the filter size). Each Residual Unit consists of two convolutional layers and two ReLU Layers. All DRLM modules in each Residual Block and all Residual Units in each DRLM are densely connected. The Laplacian attention unit consists of three convolutional layers with filter size 3×3 and dilation (a technique for expanding a convolutional kernel by inserting holes or gaps between its elements) equal to 3, 5, 7. All convolutional layers in the network, except the Laplacian one, have filter size 3×3 with dilation equal to 1. Throughout the network, the number of feature maps (the outputs of convolutional layers) is 64.
Based on this structural analysis, reducing the number of the main Residual Blocks, adding more DRLMs, and reducing the complexity of the Residual Unit and the number of hidden convolutional layers and features map drastically accelerates execution speed and reduces memory management but does not substantially affect the network’s visual quality performance.
Figure 3 depicts the resulting EVC-UFV Up-sampling Filter,
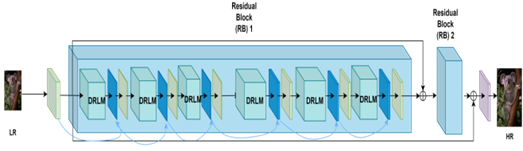
Figure 3 – Structure of the EVC-UFV Up-sampling Filter
The parameters of the original and complexity-reduced network are given in Table 1.
Table 1 – Parameters of the original and the complexity-reduced network
| Original | Final | |
| Residual Blocks | 6 | 2 |
| DRLMs per Residual Block | 3 | 6 |
| Residual Block per DRLM | 3 | 3 |
| Hidden Convolutional Layers per Residual Unit | 2 | 1 |
| Input Feature Maps | 64 | 32 |
Further, by pruning the parameters and weights of the network, the network complexity is reduced by 40%. The loss in performance is less than 1% in BD-rate. This is achieved, by first using the well-known DeepGraph technique, modified to work with deep-learning based up-sampling filter, understanding the dependency of the different components’ layers of the simplified deep-learning network. This facilitates grouping components sharing a common pruning approach that can be applied without introducing dimensional inconsistencies among the inputs and outputs of the layers.
Verification Tests of the technology has been performed on:
| Standard sequences | CatRobot, FoodMarket4, ParkRunning3. |
| Bits/sample | 8 and 10 bit-depth per component. |
| Colour space | YCbCr with 4:2:0 sub sampling. |
| Encoding technologies | AVC, HEVC, and VVC. |
| Encoding settings | Random Access and Low Delay at QPs 22, 27, 32, 37, 42, 47. |
| Up-sampling | SD to HD and HD to UHD. |
| Metrics | BD-Rate, BD-PSNR and BD-VMAF |
| Deep-learning structure | Same for all QPs |
Results show an impressive improvement for all coding technologies, and encoding options for all three objective metrics when compared with the currently used traditional bicubic interpolation. The results of Table 2 have been obtained foe the low-delay coding mode.
Table 2 – Performance of the EVC-UFV Up-sampling Filter
| AVC | HEVC | VVC | |
| SD to HD (using own trained filter) | 14.4% | 12.2% | 13.8% |
| HD to UHD (using own trained filter) | 5.6% | 6% | 6.5% |
| SD to HD (using HD to UHD filter) | 14% | 11.6% | 11.4% |
All results are obtained with the 40% pruned network.