This is the web page of the AI-based End-to-End Video Coding (MPAI-EEV) project. See the MPAI-EEV homepage for official information.
Unlike AI-Enhanced Video Coding (MPAI-EVC), that seeks to improve video compression by adding or replacing traditional data processing coding tools with AI-based tools, MPAI-EEV exploits AI-based data coding technologies in an end-to-end fashion.
MPAI-EEV is at the level of Functional Requirements (Stage 3 in the standard development process).
EEV-05 – EEV-0.4 – Drone sequences – Current Status – Initial Status – Participation
The encouraging results achieved with EEV-0.4 have motivated the group to extend the EEV-0.4 model by introducing picture interpolation. The current version of EEV-0.5 significantly exceeds EEV-.0.4.
The latest EEV reference model, EEV-0.4 offers very promising results. See MPAI – End-to-end Video (EEV) presented at the 2023/01/01 EEV-0.4 reference model event. See the video registration (YouTube, non-YouTube) of the event.
EEV0.4 is described in the following paper: MPAI-EEV: Standardization Efforts of Artificial Intelligence based End-to-End Video Coding
The software implementing it is available as Open Source Code.
MPAI offers its Unmanned Aerial Vehicle (UAV) sequence dataset for use by the video community in testing video coding algorithms. Please get an invitation from the MPAI Secretariat and come to one of the biweekly meetings of the MPAI-EEV group (starting from 1st of March 2023). The MPAI EEV is going to showcase its superior performance fully neural network-based video codec model for drone videos. The group is inclusive and planning for the future of video coding using end-to-end learning. Please feel free to participate, leaving your comments or suggestions to the MPAI EEV. We will discuss your contribution and our state of the art with the goal of progressing this exciting area of coding of video sequences from drones.
During the past decade, the Unmanned-Aerial-Vehicles (UAVs) have attracted increasing attention due to their flexible, extensive, and dynamic space-sensing capabilities. The volume of video captured by UAVs is exponentially growing along with the increased bitrate generated by the advancement of the sensors mounted on UAVs, bringing new challenges for on-device UAV storage and air-ground data transmission. Most existing video compression schemes were designed for natural scenes without consideration of specific texture and view characteristics of UAV videos.
The dataset contains various drone videos captured under different conditions, including environments, flight altitudes, and camera views. These video clips are selected from several categories of real-life objects in different scene object densities and lighting conditions, representing diverse scenarios in our daily life. Here are representative frames of the sequence.
A set of video sequences has been collected to build the UAV video coding benchmark from diverse contents, considering the recording device type (various models of drone-mounted cameras), diverse in many aspects including location (in-door and out-door places), environment (traffic workload, urban and rural regions), objects (e.g., pedestrian and vehicles), and scene object density (sparse and crowded scenes).
Table 1 provides a comprehensive summary of the prepared learned drone video coding benchmark for a better understanding of those videos.
Table 1 – Drone video test sequences
| Source | Sequence Name |
Spatial Resolution |
Frame Count |
Frame Rate |
Bit Depth |
Scene Feature |
|
Class A VisDrone-SOT TPAM12021 |
BasketballGround | 960×528 | 100 | 24 | 8 | Outdoor |
| GrassLand | 1344×752 | 100 | 24 | 8 | Outdoor | |
| Intersection | 1360×752 | 100 | 24 | 8 | Outdoor | |
| NightMall | 1920×1072 | 100 | 30 | 8 | Outdoor | |
| SoccerGround | 1904×1056 | 100 | 30 | 8 | Outdoor | |
| Class B VisDrone-MOT TPAM12021 |
Circle | 1360×752 | 100 | 24 | 8 | Outdoor |
| CrossBridge | 2720×1520 | 100 | 30 | 8 | Outdoor | |
| Highway | 1344×752 | 100 | 24 | 8 | Outdoor | |
| Class C Corridor IROS2018 |
Classroom | 640×352 | 100 | 24 | 8 | Indoor |
| Elevator | 640×352 | 100 | 24 | 8 | Indoor | |
| Hall | 640×352 | 100 | 24 | 8 | Indoor | |
| Class D UAVDT S ECCV2018 |
Campus | 1024×528 | 100 | 24 | 8 | Outdoor |
| RoadByTheSea | 1024×528 | 100 | 24 | 8 | Outdoor | |
| Theater | 1024×528 | 100 | 24 | 8 | Outdoor |
The corresponding thumbnail of each video clip is depicted in Fig. 1 as supplementary information. There are 14 video clips from multiple different UAV video dataset sources [1, 2, 3]. Their resolutions and frame rates range from 2720 × 1520 down to 640 × 352 and 24 to 30 respectively.

Figure 1 – Thumbnails of the drone video clips
Compared to natural videos, UAV-captured videos are generally recorded by drone-mounted cameras in motion and at different viewpoints and altitudes. These features bring several new challenges, such as motion blur, scale changes and complex background. Heavy occlusion, non-rigid deformation and tiny scales of objects might be of great challenge to drone video compression.
Introduction
In MPAI EEV project, we have contributed a detailed analysis of the current state of the field of UAV video coding. Then EEV establishes a novel task for learned UAV video coding and construct a comprehensive and systematic benchmark for such a task, present a thorough review of high quality UAV video datasets and benchmarks, and contribute extensive rate-distortion efficiency comparison of learned and conventional codecs after. Finally, we discuss the challenges of encoding UAV videos. It is expected that the benchmark will accelerate the research and development in video coding on drone platforms. Please read the full paper.
To comprehensively reveal the R-D efficiency of UAV video using both conventional and learned codecs, we encode the above-collected drone video sequences using the HEVC reference software with screen content coding (SCC) extension (HM-16.20-SCM-8.8) and the emerging learned video coding framework OpenDVC [4]. Moreover, the reference model of MPAI End-to-end Video (EEV) is also employed to compress the UAV videos. As such, the baseline coding results are based on three different codecs. Their schematic diagrams are shown in Fig. 1. The left panel represents the classical hybrid codec. The remaining two are learned codecs, OpenDVC and EEV respectively. It is easy to observe that the EEV software is an enhanced version of OpenDVC codecthat incorporates more advanced modules such as motion compensation prediction improvement, two-stage residual modelling, and in-loop restoration network.
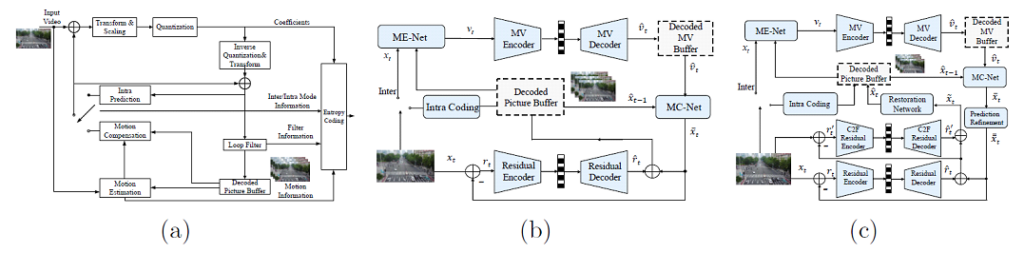
Figure 1 Block diagram of different codecs. (a) Conventional hybrid codec HEVC. (b)
OpenDVC. (3) MPAI EEV. Zoom-in for better visualization
Another important factor for learned codecs is train-and-test data consistency. It is widely accepted in the machine learning community that train and test data should be independent and identically distributed. However, both OpenDVC and EEV are trained using the natural video dataset vimeo-90k with mean-square-error (MSE) as distortion metrics. We employ those pre-trained weights of learned codecs without fine-tuning them on drone video data to guarantee that the benchmark is general.
Evaluation.
Since all drone videos in our proposed benchmark use the RGB color space, the quality assessment methods are also applied to the reconstruction in the RGB domain. For each frame, the peak-signal-noise-ratio (PSNR) is are calculated for each component channel. Then the RGB averaged value is obtained to indicate its picture quality. Regarding the bitrate, we calculate bit-per-pixel (BPP) using the binary files produced by codecs. We report the coding efficiency of different codecs using the Bjøntegaard delta bit rate (BD-rate) measurement.
Table 1: The BD-rate performance of different codecs (OpenDVC, EEV, and HM-16.20- SCM-8.8) on drone video compression. The distortion metric is RGB-PSNR.
| Category | Sequence Name |
BD-Rate Reduction EEV vs OpenDVC |
BD-Rate Reduction EEV vs HEVC |
|
Class A VisDrone-SOT |
BasketballGround | -23.84% | 9.57% |
| GrassLand | -16.42% | -38.64% | |
| Intersection | -18.62% | -28.52% | |
| NightMall | -21.94% | -6.51% | |
| SoccerGround | -21.61% | -10.76% | |
| Class B VisDrone-MOT | Circle | -20.17% | -25.67% |
| CrossBridge | -23.96% | 26.66% | |
| Highway | -20.30% | -12.57% | |
| Class C Corridor | Classroom | -8.39% | 178.49% |
| Elevator | -19.47% | 109.54% | |
| Hall | -15.37% | 58.66% | |
| Class D UAVDT S | Campus | -26.94% | -25.68% |
| RoadByTheSea | -20.98% | -24.40% | |
| Theater | -19.79% | 2.98% | |
| Class A | -20.49% | -14.97% | |
| Class B | -21.48% | –3.86% | |
| Class C | -14.41% | 115.56% | |
| Class D | -22.57% | -15.70% | |
| Average | -19.84% | 15.23% | |
The corresponding PSNR based R-D performances of the three different codecs are shown in Table 1. Regarding the simulation results, it is observed that around 20% bit-rate reduction could be achieved when comparing EEV and OpenDVC codec. This shows promising performances for the learned codecs and its improvement made by EEV software.
When we directly compare the coding performance of EEV and HEVC, obvious performance gap between the in-door and out-door sequences could be observed. Generally speaking, the HEVC SCC codec outperforms the learned codec by 15.23% over all videos. Regarding Class C, EEV is significantly inferior to HEVC by clear margin, especially for the Classroom and elevator sequences. Such R-D statistics reveal that learned codecs are more sensitive to the video content variations than conventional hybrid codecs if we directly apply natural-video-trained codec to UAV video coding. For future research, this point could be resolved and modeled as an out-of-distribution problem and extensive knowledge could be borrowed from the machine learning community.
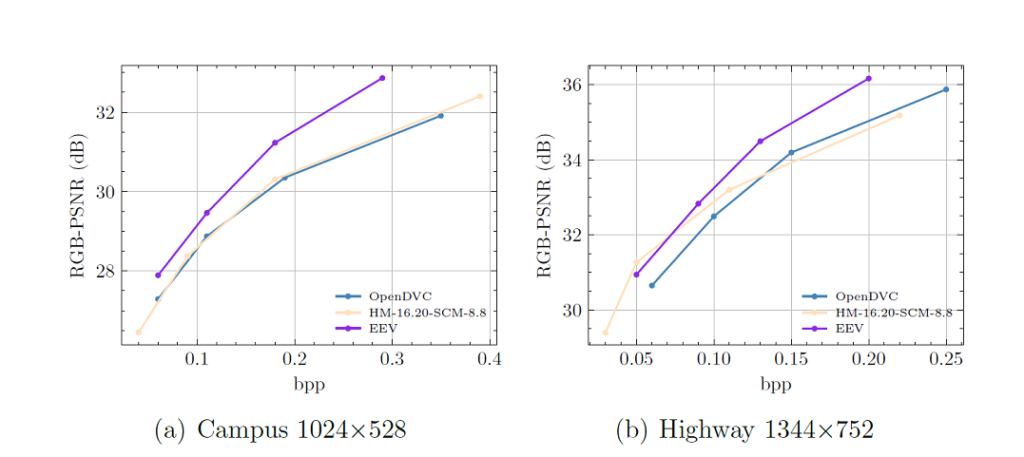
To further dive into the R-D efficiency interpretation of different codecs, we plot the R-D curves of different methods in Fig. 2. Specifically, we select Camplus and Highway for illustration. The blue-violet, peach-puff, and steel-blue curves denote EEV, HEVC, and OpenDVC codec respectively. The content characteristic of UAV videos and its distance to the natural videos shall be modeled and investigated in future research.
MPAI-EEV Working Mechanism
This work was accomplished in the MPAI-EEV coding project, which is an MPAI standard project seeking to compress video by exploiting AI-based data coding technologies. Within this workgroup, experts around the globe gather and review the progress, and plan new efforts every two weeks. In its current phase, attendance at MPAI-EEV meetings is open to interested experts. Since its formal establishment in Nov. 2021, the MPAI EEV has released three major versions of it reference models. MPAI-EEV plans on being an asset for AI-based end-to-end video coding by continuing to contribute new development in the end-to-end video coding field.
This work, contributed by MPAI-EEV, has constructed a solid baseline for compressing UAV videos and facilitates the future research works for related topics.
Reference
[1] Pengfei Zhu, Longyin Wen, Dawei Du, Xiao Bian, Heng Fan, Qinghua Hu, and Haibin Ling, “Detection and Tracking Meet Drones Challenge,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 44, no. 11, pp. 7380–7399, 2021.
[2] A. Kouris and C.S. Bouganis, “Learning to Fly by MySelf: A Self-Supervised CNN- based Approach for Autonomous Navigation,” in IEEE/RSJ International Conference on Intelligent Robots and Systems, 2018, pp. 5216–5223.
[3] Dawei Du, Yuankai Qi, Hongyang Yu, Yifan Yang, Kaiwen Duan, Guorong Li, Weigang Zhang, Qingming Huang, and Qi Tian, “The Unmanned Aerial Vehicle Benchmark: Object Detection and Tracking,” in European Conference on Computer Vision, 2018, 370–386.
[4] Ren Yang, Luc Van Gool, and Radu Timofte, “OpenDVC: An Open Source Imple- mentation of the DVC Video Compression Method,” arXiv preprint arXiv:2006.15862, 2020.
Video coding standards exist since 40 years. The first two standards – H.120 and H.261 – were taken over by MPEG-1 and then by MPEG-2. The subsequent 19 years-old MPEG-4 AVC is still the dominant video codec in the industry.
It is a matter of fact that, 9 years after its publication, MPEG-H HEVC decoders are installed in most TV sets and widely used, HEVC codecs are installed in mobile handsets and hardly used and 12% of internet video content – according to the last published statistics – uses HEVC.
The latest VVC codec is going to have significant competition from codecs based on different licensing models. Currently, some groups continue the practice of just adding technologies – this time also AI based – to existing standards. The practical use of future standards based on this approach is anybody’s guess.
A key element driving the establishment of MPAI has been licensability of data – in particular video – coding standards. Therefore, MPAI has focused its video coding activities on the MPAI-EVC Evidence Project seeking to replace or improve existing MPEG-5 EVC tools with AI tools. The latest results confirm the gains that can be obtained by using AI tools for video coding.
Based on public announcements, MPAI expects that the licensing landscape of the MPEG-5 EVC standard will be significantly simplified. The basic MPEG-5 EVC profile is expected to be royalty free and, in a matter of months, three major companies are due to publish their MPEG-5 EVC patent licences.
MPAI’s strategy is to start from a high-performance “clean-sheet” data-processing-based coding scheme and add AI-enabled improvements to it, instead of starting from a scheme where data processing technologies give insignificant improvements and are overloaded by IP problems.
Once the MPAI-EVC Evidence Project will demonstrate that AI tools can improve the MPEG-5 EVC efficiency by at least 25%, MPAI will be in a position to initiate work on its own MPAI-EVC standard. The functional requirements already developed need only to be revised while the framework licence needs to be developed before a Call for Technology can be issued.
Thus, MPAI-EVC can cover the short-to-medium term video coding needs.
There is consensus in the video coding research community – and some papers make claims grounded on results – that so-called End-to-End (E2E) video coding schemes can yield significantly higher performance. However, many issues need to be examined, e.g., how such schemes can be adapted to a standard-based codec (see Annex 1 for a first analysis). End-to-End E2E VC promises AI-based video coding standard with significantly higher performance in the longer term.
As a technical body unconstrained by IP legacy and whose mission is to provide efficient and usable data coding standards, MPAI should initiate the study of what we can call End-to-End Video Coding (MPAI-EEV). This decision would be an answer to the needs of the many who need not only environments where academic knowledge is promoted but also a body that develops common understanding, models and eventually standards-oriented End-to-End video coding.
The MPAI-EVC Evidence Project should continue and new resources should be found to support the new activity. MPAI-EEV should be considered at the Interest Collection stage.
Annex 1 – About End-to-End (E2E) video coding
Deep learning is a powerful tool to devise new architectures (alternative to the classic block-based hybrid coding framework) that offer higher compression, or more efficient extraction of relevant information from the data.
Motivated by the recent advances in deep learning, several E2E image/video coding schemes based have been developed. By replacing the traditional video coding chain with a fully AI-based architecture, it is expected that higher compression will be obtained and that compressed videos are more visually pleasing because they do not suffer from blocking artifacts and pixelation [1].
Generally speaking, the main features of E2E schemes are [1]:
- Generalisation of motion estimation to perform compensation beyond simple translation.
- Joint optimisation of all transmitted data (motion information and residuals).
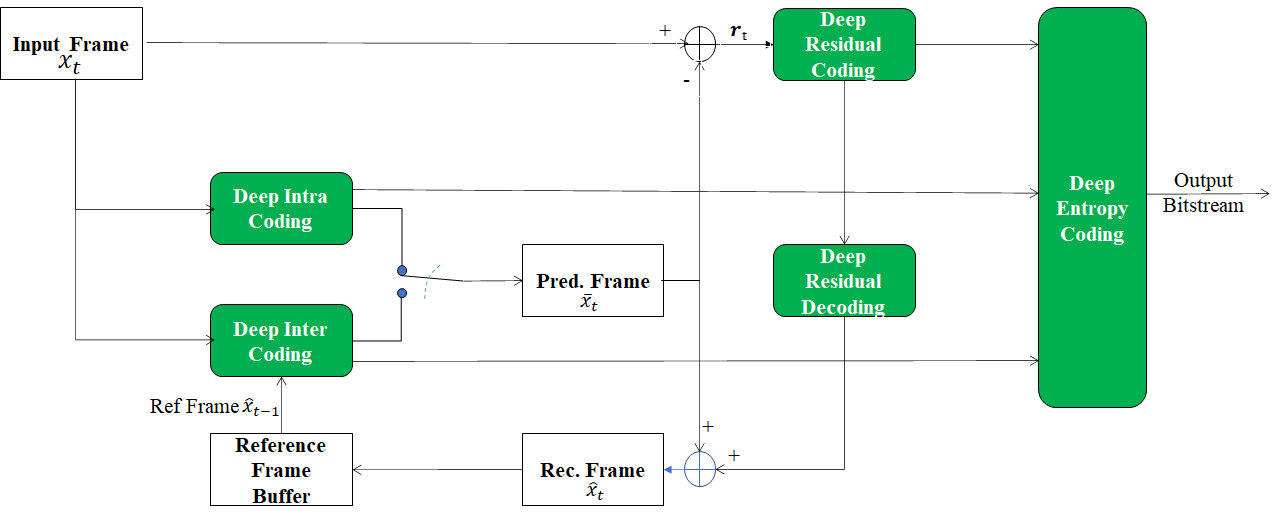 Figure 1 – An End-to-End deep video compression scheme
Figure 1 – An End-to-End deep video compression scheme
Figure 1 depicts a possible End-to-End deep video coding scheme. It predicts the current frame using a trained network (Deep Inter Coding) and uses two auto-encoder neural networks to compress motion information (Deep Inter Coding) and prediction residuals (Deep Residual Coding). The entire architecture is jointly optimised with a single loss function, i.e. the joint rate-distortion optimisation (Rate Distortion Optimisation aims to achieve higher reconstructed frame quality for a given number of bits for compression).
Research is moving towards experimenting more general and hopefully more effective architectures. Figure 2 depicts a single neural network trained to compress any video source and capable to learn and manage the trade-off between bitrate and final quality [2].
 Figure 2 – An general E2E architecture
Figure 2 – An general E2E architecture
As designing such a network might be a challenging goal, it may be necessary to face the End-to-End challenge step by step.
Papers Results
MPAI has carried out a literature survey on End-to-End video coding (M533). Table 1 summarises the gain (expressed in terms of the Bjontegaard Delta on the rate, BD-Rate) with respect to HEVC of the two deep video architectures considered.
Table 1 shows that the average voding efficiency improvement of two reported E2E deep video architecture is 31.59% compared to HEVC.
Table 1 – Gain of some End-to-End deep video architectures vs. AVC
| Paper | Test condition | BD- Rate |
| An End-to-End Learning Framework for Video Compression | AVC | -25.06% |
Table 2shows the coparison with HEVC of two selected E2E architecture and it shows an average coding efficiency improvement of 32.06%.
Taking into account the results above, the MPAI-EVC Evidence Project supports the new activity based on E2E video coding.
Table 2 – Gain of some End-to-End deep video architectures vs. HEVC
| Paper | Test condition | BD- Rate |
| ELF-VC: Efficient Learned Flexible-Rate Video Coding | HEVC Low Delay | -26% |
| Neural Video Compression Using Spatio-Temporal Priors | HEVC Main profile | -38.12% |
| Average | -32,06% | |
Taking into account the results above, the MPAI-EVC Evidence Project supports the new activity based on E2E video coding.
References
[1] G. Lu et al., An End-to-End Learning Framework for Video Compression, in “IEEE Transactions on Pattern Analysis and Machine Intelligence“, DOI: 10.1109/TPAMI.2020.2988453
[2] Jacob et al., Deep Learning Approach to Video Compression, in “2019 IEEE Bombay Section Signature Conference (IBSSC)“, 2019, DOI
MPAI has developed a study of the State of the art of end-to-end video coding. It has decided to start from the DVC and OpenDVC papers and is using the results of the study of the state of the art to add tools to OpenDVC and develop a reference model that will be used for collaborative investigations. Anybody is allowed to submit contributions, provided they are submitted with a statement declaring acceptance of the Basic Framework Licence for Collaborative Explorations.
If you wish to participate in this work you have the following options
- Join MPAI
- Participate until the MPAI-EEV Functional Requirements are approved (after that only MPAI members can participate) by sending an email to the MPAI Secretariat.
- Keep an eye on this page.
Return to the MPAI-EEV page