This is the public page of the Multi-Modal Conversation (MPAI-MMC) standard providing technical information. Also see the MPAI-MMC homepage.
MPAI has developed Version 1 and Version 2 of MPAI-MMC.
MPAI-MMC: Version 2 | Version 1
Technical Specification: Multimodal Conversation (MPAI-MMC) V2 specifies technologies further enhancing the capability of a human to converse with a machine in a variety of application environments compared to V1. In particular it extends the notion and the data format of Emotion to Personal Status that additionally includes Cognitive State and Social Attitude. V2 applies Personal Status and other data types to support new use cases.
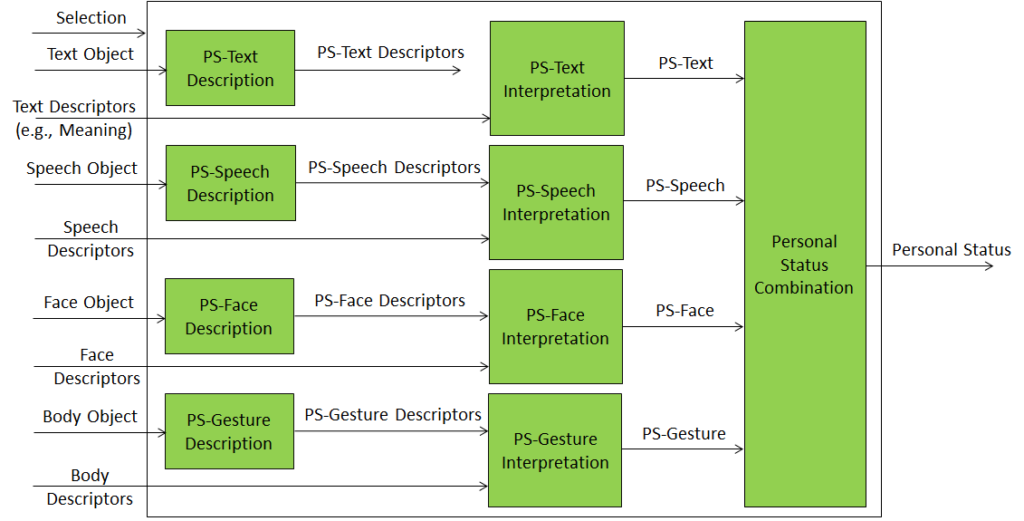 |
Personal Status Extraction: provides an estimate of the Personal Status (PS) – of a human or an avatar – conveyed by a Modality (Text, Speech, Face, and Gesture). PS is the ensemble of Factors, i.e., information internal to a human or an avatar (Emotion, Cognitive State, and Social Attitude), extracted through the steps of Description Extraction and PS Interpretation. |
| Figure 1 – Personal Status Extraction (PSE) | |
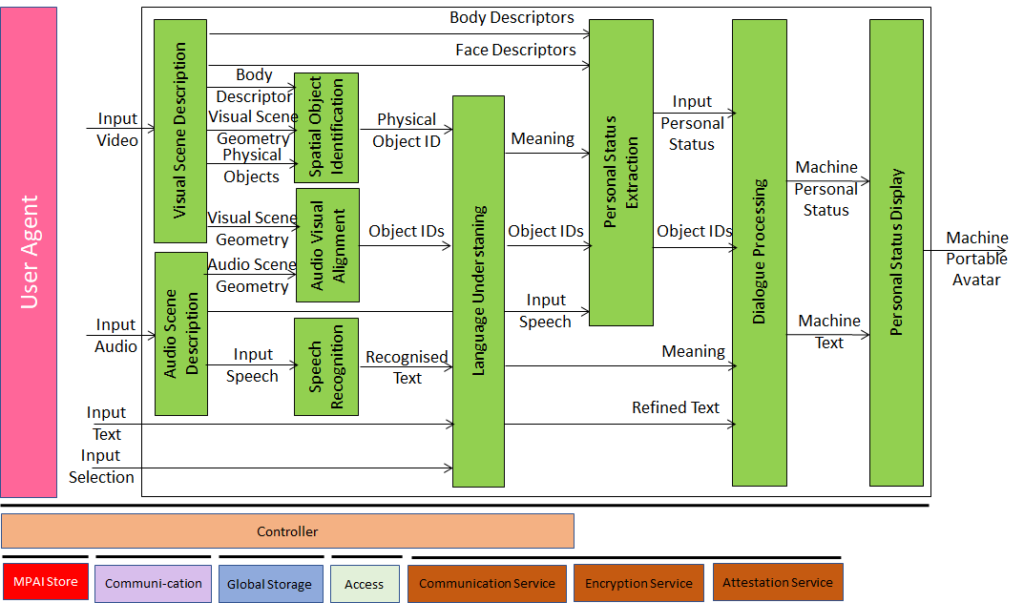 |
An entity – a real or digital human – converses with a machine possibly about physical objects in the environment. The machine captures and understands Speech, extracts Personal Status from the Text, Speech, Face, and Gesture Factors, fuses the Factors into an estimated Personal Status of the entity to achieve a better understanding of the context in which the entity converses. The machine is represented by a Portable Avatar. |
| Figure 2 – Conversation with Personal Status (MMC-CPS) | |
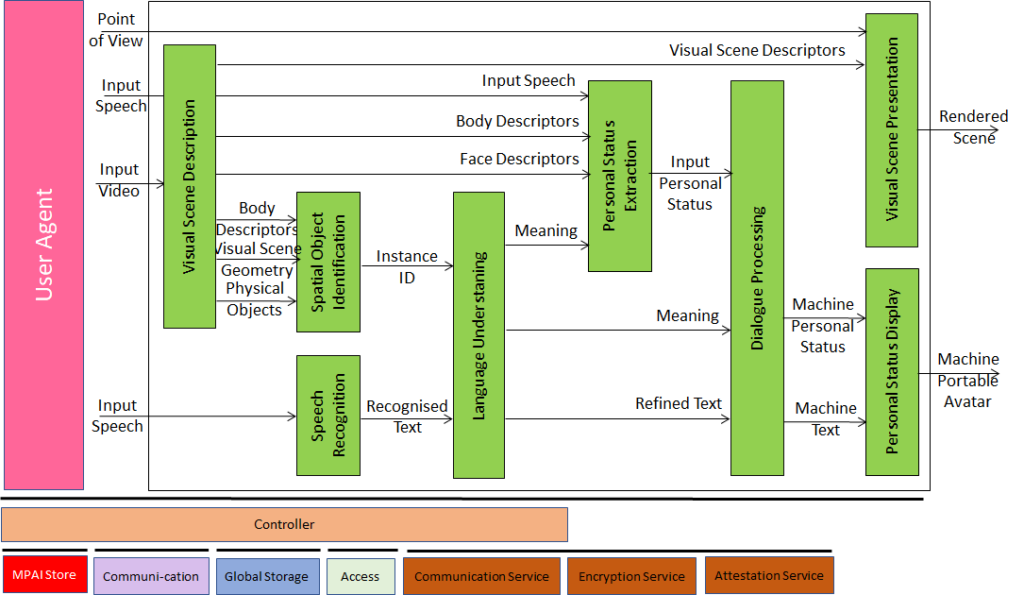 |
A human holds a conversation with a machine about objects around the human. While conversing, the human points their fingers to indicate their interest in a particular object. The machine uses Visual Scene Description to extract the Human Object and the Physical Object, uses PSE to understand the human’s PS, and uses Personal Status Display (PSD) to respond while showing its PS. |
| Figure 3 – Conversation About a Scene (CAS) | |
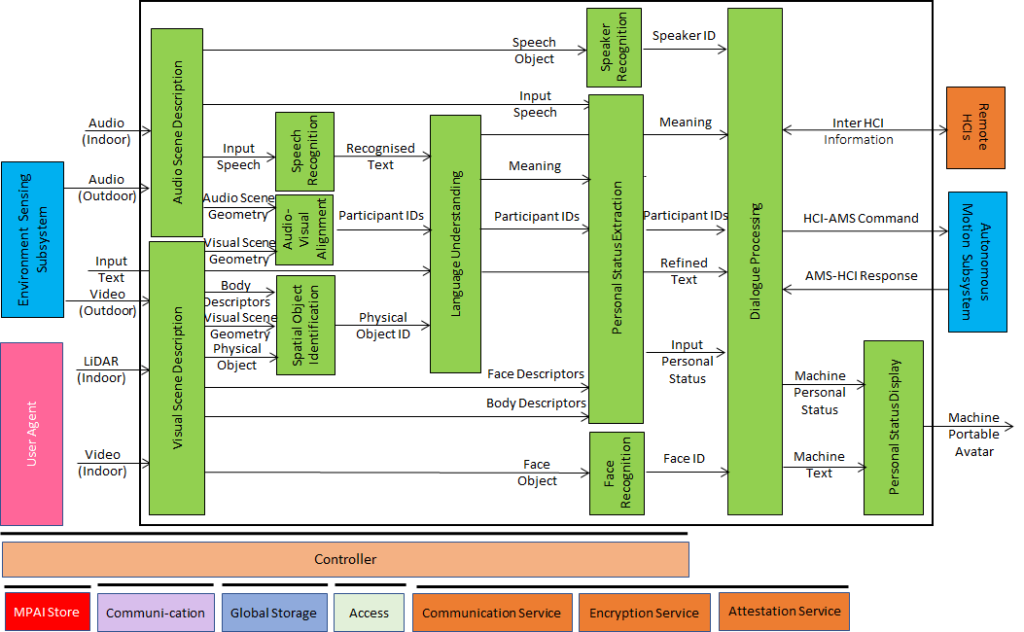 |
Humans converse with a CAV which understands their utterances and their PSs by means of the PSE and manifests itself as the output of a PSD. HCI also recognises humans by face and speech both when they are outside and approach the CAV and inside the cabin. The figure also represents the communication of the Ego CAV HCI with Remote HCIs. |
| Figure 4 – Human-Connected Autonomous Vehicle (CAV) Interaction (HCI) | |
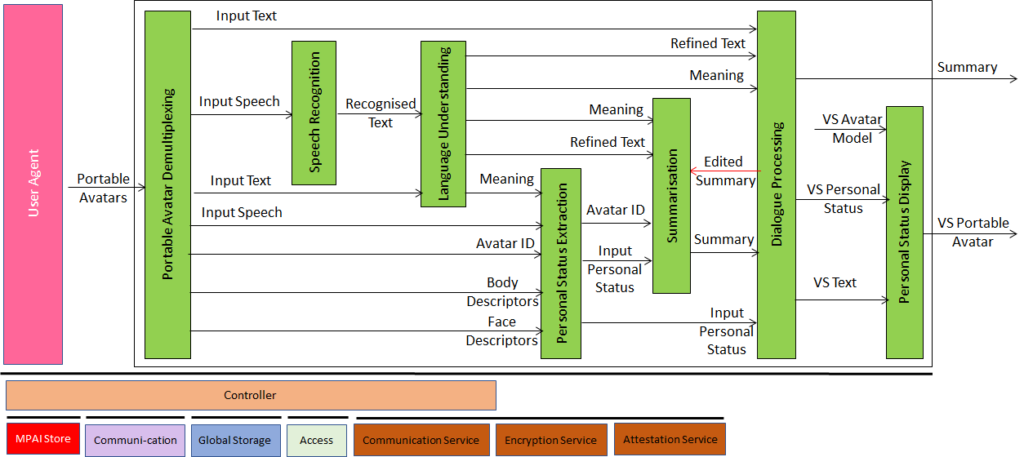 |
The Virtual Secretary (VS) is a human-like speaking avatar not representing a human who produces a summary of what is being said at the meeting, including the participants’ PSs. Participating avatars can make comments to the VS, answer questions, etc. The VS manifests itself through a PSD. |
| Figure 5 – Avatar-Based Videoconference (Virtual Secretary) | |
MPAI-MMC: Version 1 – Version 2
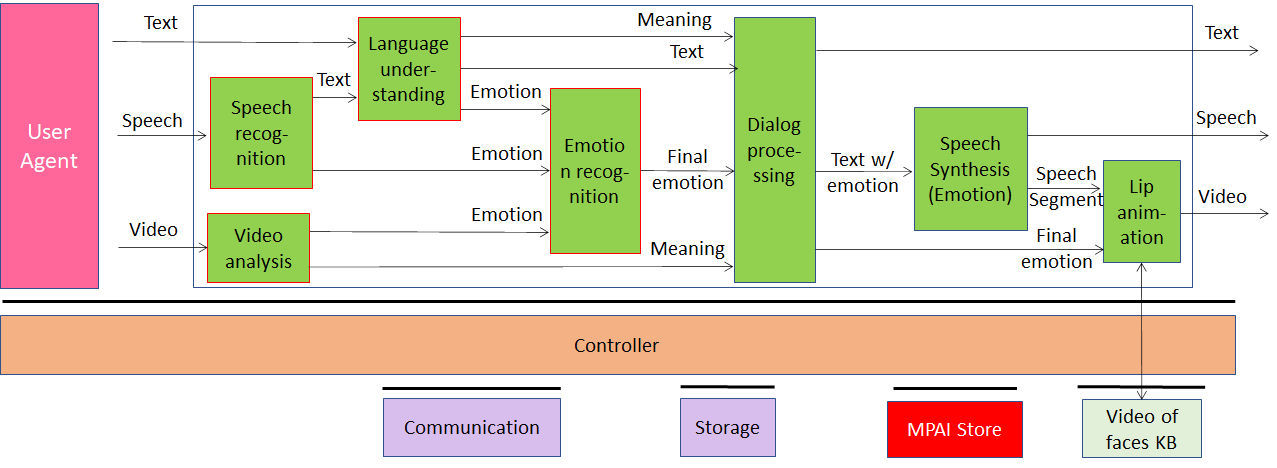
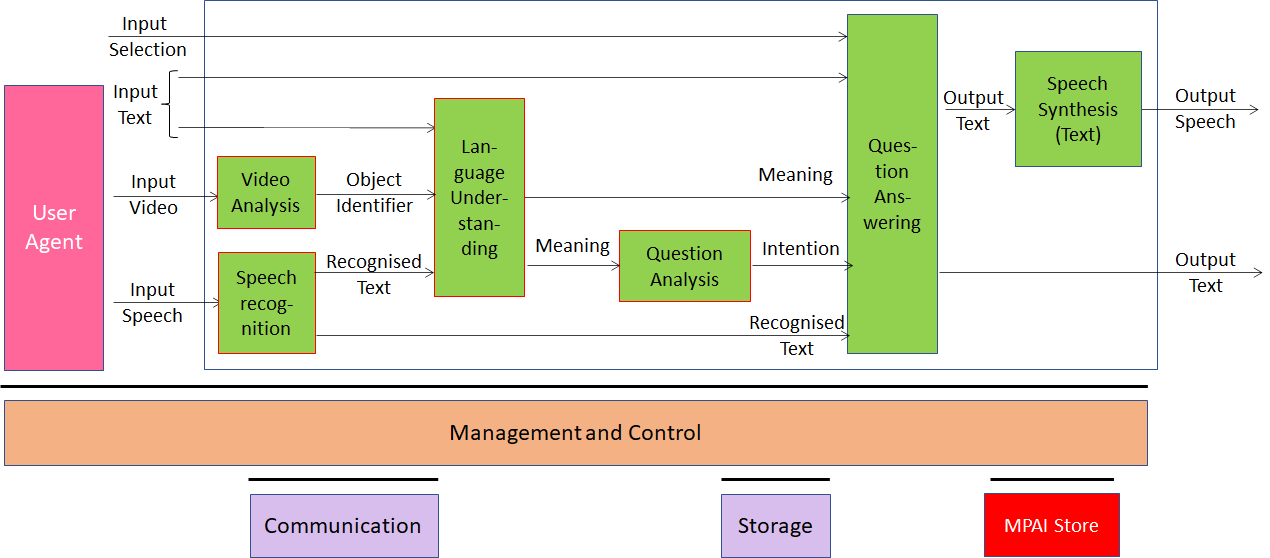
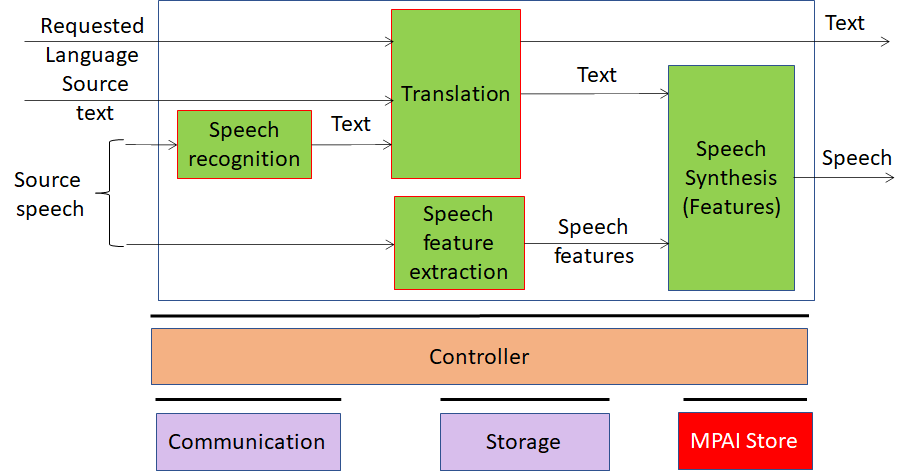
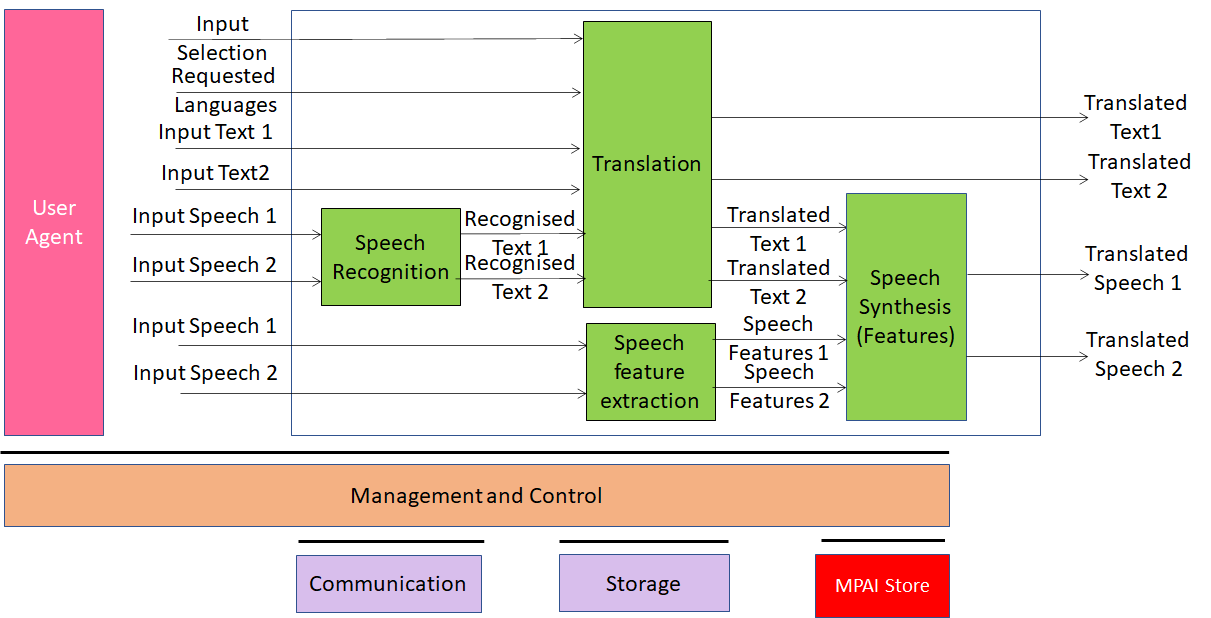
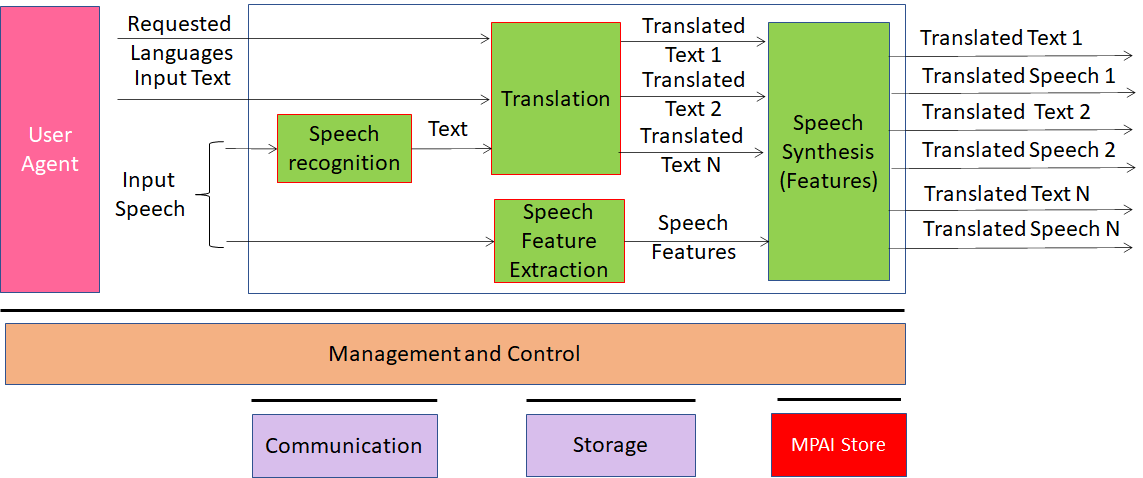
Version 1: MPAI-MMC V1 enables human-machine conversation emulating human-human conversation in completeness and intensity using AI. The MPAI-MMC standard includes 5 Use Cases: Conversation with Emotion, Multimodal Question Answering, Unidirectional Speech Translation, Bidirectional Speech Translation and One-to-Many Unidirectional Speech Translation.
The figures below shows the reference models of the MPAI-MMC Use Cases. Note that an Implementation is supposed to run in the MPAI-specified AI Framework (MPAI-AIF).
If you wish to participate in this work you have the following options:
- Join MPAI
- Keep an eye on this page.
Return to the MPAI-MMC page