This is the public page of Mixed-reality Collaborative Spaces (MPAI-MCS) standard. See the MPAI-MCS homepage.
MPAI-MCS is an MPAI standard project developing technologies for scenarios where geographically separated humans represented by avatars collaborate in virtual-reality spaces where:
- Virtual Twins of humans – embodied in speaking avatars having a high level of similarity, in terms of voice and appearance, with their Human Twins – are directed by Human Twins to achieve an agreed goal.
- Human-like speaking avatars, possibly without a visual appearance, not representing a human, e.g., a secretary taking notes of the meeting, answer questions, etc.
The space where the collaboration takes place is called Environment. It can be anything from a fictitious space to a replica of a real space.
MPAI is currently investigating the Use Case called Avatar-Based Videoconference where each participant is represented by an avatar sitting at a table. The avatars faithfully represent the participants with their speech, faces, and gestures. This is achieved by using the emotion extracted from speech, face and gesture of participants.
MPAI-MCS seeks to define standard formats for the Environment and for the Avatar so that, by owning an MCS client, a participant can:
- Distribute their own avatars reproducing their activity and speech to other participants in the virtual conference.
- Assemble the videcoconference room using the received avatars and participate in it.
The end-to-end block diagram of the Avatar-Based Videonference Use Case is given by the figure below where:
- Each participant sends:
- server (at start): language preferences, avatar model, and speech and face descriptors for authentication.
- server and virtual secretary (during conferemce): avatar description, and speech and text.
- The server sends each participant:
- (at start): Environment description and avatar models.
- (during conference): participant ID, speech and text in the requested language, avatar descriptors.
- The virtual secretary sends each participant its own avatar model (at start), avatars descriptors, and speech and text.
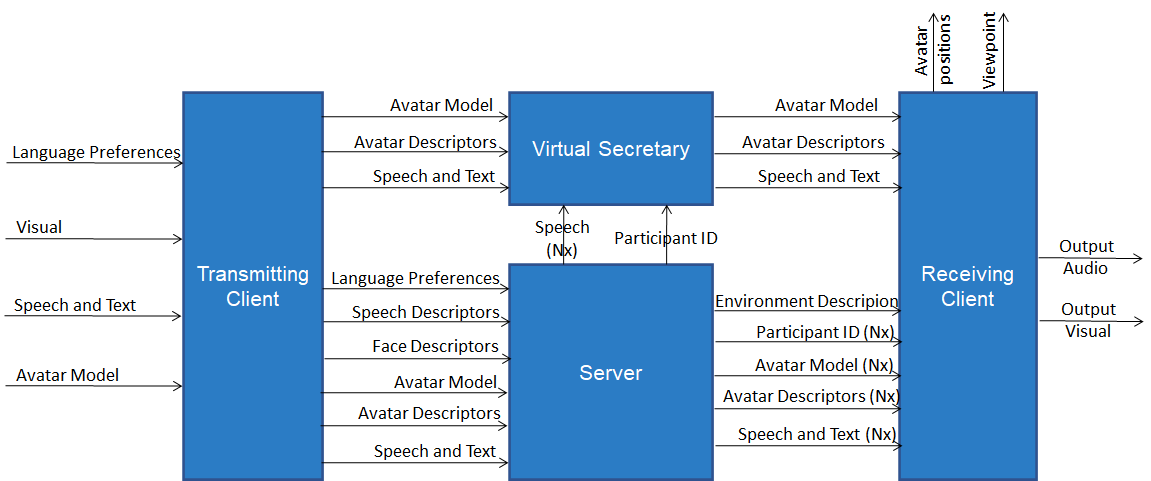
Figure 1 – Reference Model of the Avatar-Based Videoconference
The figures below describe the internals of the 4 system components with a particular partitioning of functionality: transmitting client (Figure 2), server (Figure 3), virtual secretary (Figure 4), and receiving client (Figure 5). Different partitions are obtained by moving the internal components from one system component (blue blocks in the figure above) to another).
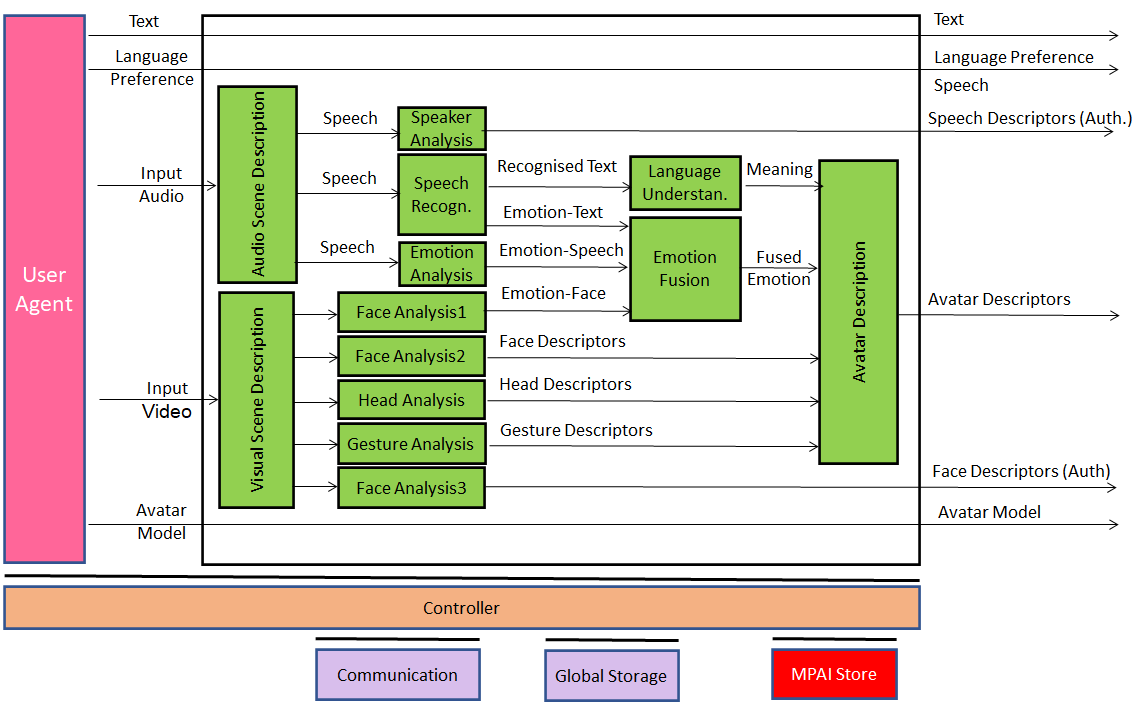

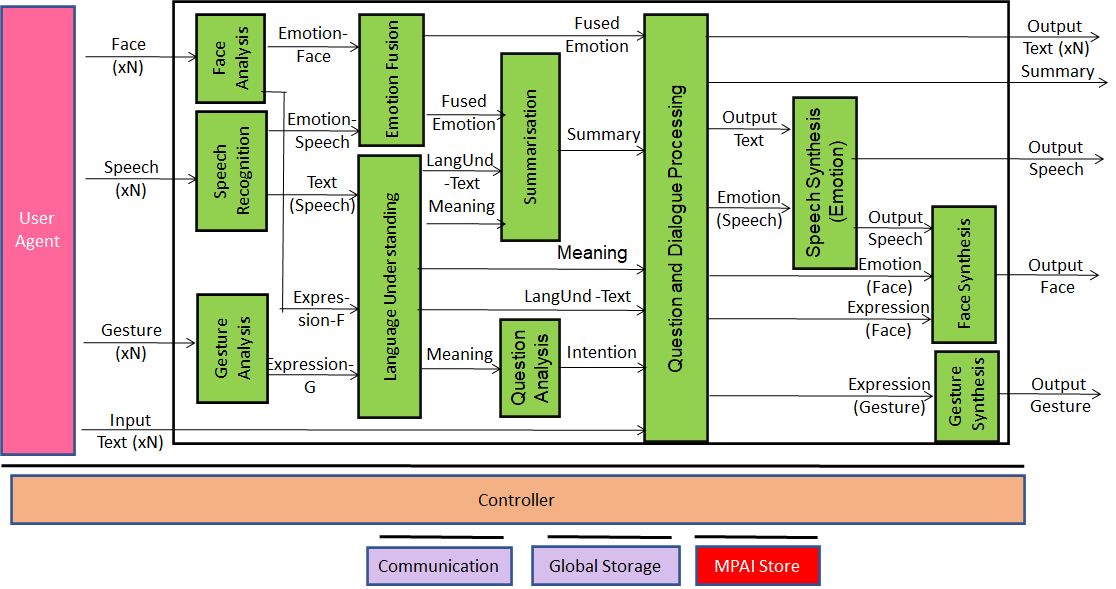
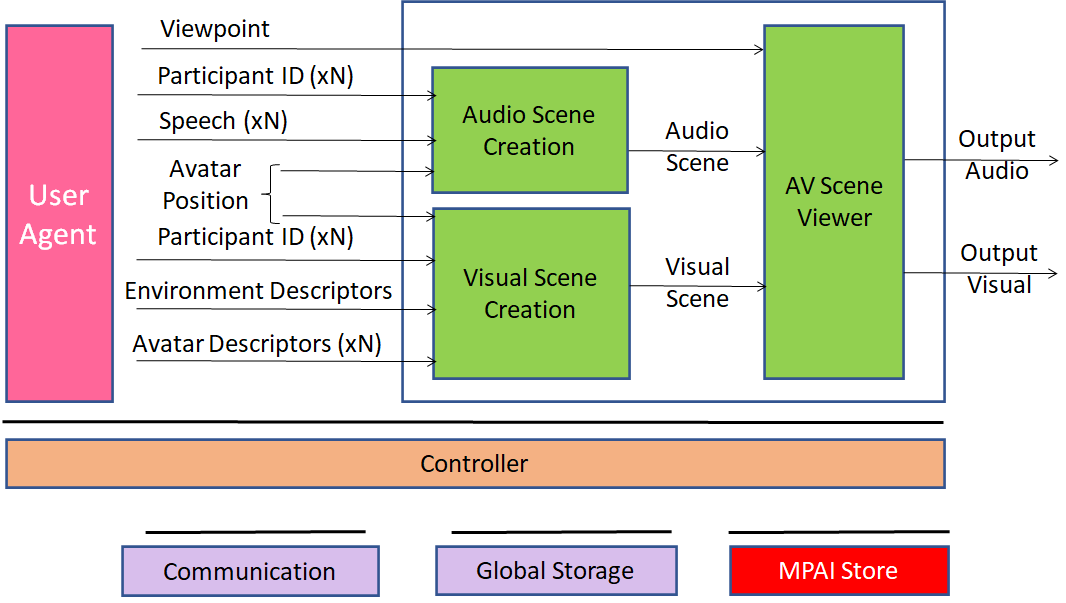
This use case is part of theMPAI-MMC Use Cases and Functional Requirements WD1.4. MPAI intends to issue a Call for Technologies on 9 July 2022. Anybody may respond to the Call. If a proposed technology is accepted, the proponent is requested to join MPAI.
MPAI-MCSis at the level of Use Cases and Functional Requirements. If you wish to participate in this work you have the following options
- Join MPAI
- Participate until the MPAI-MCS Functional Requirements are approved (after that only MPAI members can participate) by sending an email to the MPAI Secretariat.
- Keep an eye on this page.
Return to the MPAI-MCS page