Autonomous User (A-User) is an autonomous agent able to move and interact (converse, etc.) with another User in a metaverse. It is a “conversation partner in a metaverse interaction” with the User, itself an A-User or and H-User directly controlled by a human. The figure shows a diagram of the A-User while the User generates audio-visual streams of information and possibly text as well.
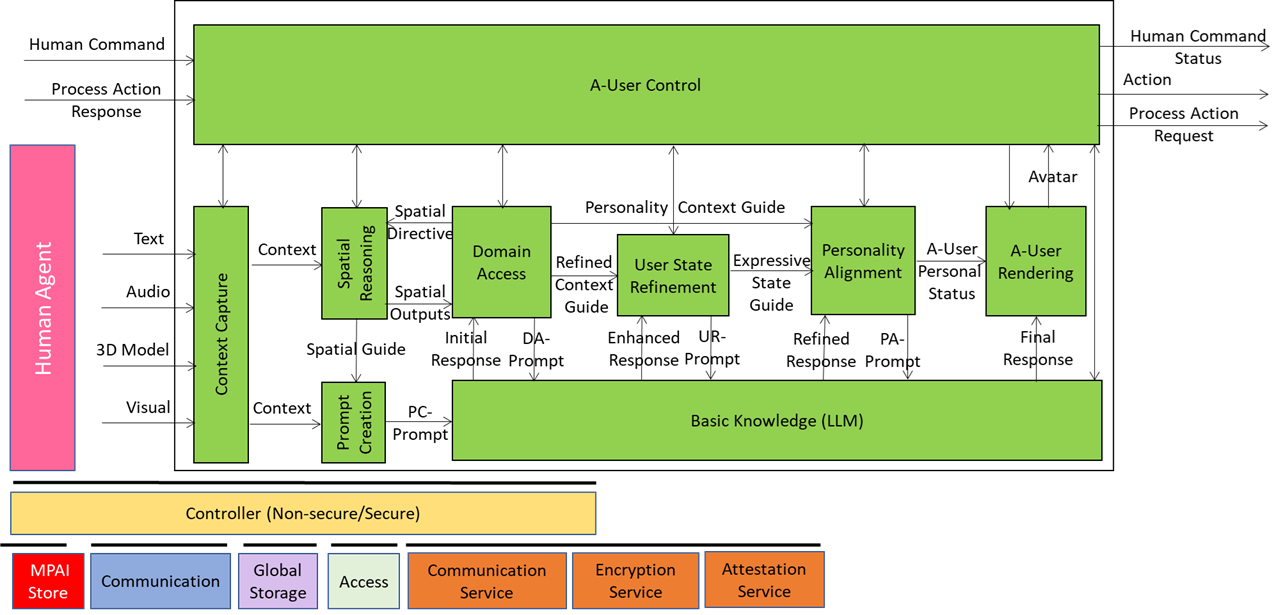
The sequence of posts – of which this is the second – that illustrates more in depth the architecture of an A-User provides as an easy entry point for those who wish to respond to the MPAI Call for Technology on Autonomous User Architecture. The first post dealt with the A-User Control, the AI-Module (AIM) that controls the other AIM of the A-User and is possibly controlled by a human.
Context Capture is the A-User’s sensory front-end – the AIM that opens up perception by scanning the environment and assembling a structured snapshot of what’s out there in the moment. It is the first AI Module (AIM) in the loop providing the data and setting the stage for everything that follows. When A-User Control decides it’s time to engage, it prompts Context Capture to focus on a specific M-Location – the zone where the User is active, rendering its Avatar.
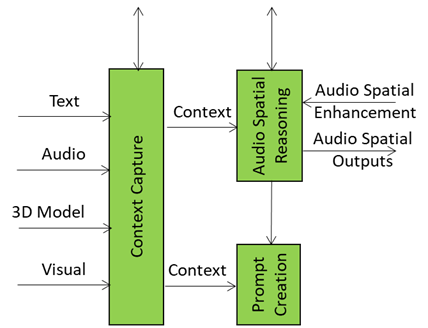
What Context Capture produces is called Context – a time-stamped, multimodal snapshot that represents the A-User’s initial understanding of the scene. But this isn’t just raw data. Context is composed of two key ingredients: Audio-Visual Scene Descriptors and User State.
The Audio-Visual Scene Descriptors are like a spatial sketch of the environment. They describe what’s visible and audible: objects, surfaces, lighting, motion, sound sources, and spatial layout. They provide the A-User with a sense of “what’s here” and “where things are.” But they’re not perfect. These descriptors are often shallow – they capture geometry and presence but not meaning. A chair might be detected as a rectangular mesh with four legs, but Context Capture doesn’t know if it’s meant to be sat on, moved, or ignored.
That’s where Spatial Reasoning comes in. Spatial Reasoning is the AIM that takes this raw spatial sketch and starts asking the deeper questions:
- “Which object is the User referring to?”
- “Is that sound coming from a relevant source?”
- “Does this object afford interaction, or is it just background?”
It analyses the Context and produces two critical outputs:
- Spatial Output: a refined map of spatial relationships, referent resolutions, and interaction constraints.
- Spatial Guide: a set of cues that enrich the user’s input — highlighting which objects or sounds are relevant, how close they are, and how they might be used.
These outputs are sent downstream to Domain Access and Prompt Creation. The former refines the spatial understanding of the scene. The latter enriches the A-User’s query when it formulates the prompt to the Basic Knowledge (LLM).
Then there’s User State – a snapshot of the User’s cognitive, emotional, and attentional posture. Is the User focused, distracted, curious, frustrated? Context Capture reads facial expressions, gaze direction, posture, and vocal tone to infer a baseline state. But again, it’s just a starting point. User behaviour may be nuanced, and initial readings can be incomplete, noisy or ambiguous. That’s why User State Refinement exists – to track changes over time, infer deeper intent, and guide the alignment of the A-User’s expressive behaviour done by Personality Alignment.
In short, Context Capture is the A-User’s first glimpse of the world – a fast, structured perception layer that’s good enough to get started, but not good enough to finish the job. It’s the launchpad for deeper reasoning, richer modulation, and more expressive interaction. Without it, the A-User would be blind. With it, the system becomes situationally aware, emotionally attuned, and ready to reason – but only if the rest of the AIMs do their part.
Responses to the Call must reach the MPAI Secretariat (secretariat@mpai.community) by 2025/01/21.
To know more, register to attend the online presentations of the Call on 17 November at 9 UTC (https://tinyurl.com/y4antb8a) and 16 UTC (https://tinyurl.com/yc6wehdv).