Like it or not, we do what the title says regularly, with mixed results. Searching for that file in your computer should be easy but it is often not, finding that an email is a hassle, especially when retrieving it is so important, and talking with an information service is often challenge to your nervous system.
I have no intention to criticise the – difficult – work that others have done, but the results of human-machine conversation are far from satisfactory.
Artificial Intelligence promises to do a better job.
Since a few months, MPAI has started working on an area called Multimodal Conversation (MMC). The intention is to use a plurality of communication means to improve the ability of humans to talk to machines. Currently, the area includes 3 Use Cases:
- Conversation with Emotion (CWE)
- Multimodal Question Answering (MQA)
- Personalized Automatic Speech Translation (PST).
In this article I would like to present the first, CWE.
The driver of this use case is that, to improve the ability of a machine to have a conversation with a human, it is important for the machine to have information about the words that are used by the human but also on other entities such as the emotional state of the human. If a human is asking a question about the quality of a telephone line, it is important for the machine to know if the emotion of the speaker is neutral – the question is likely purely informational – or altered – the question likely implies a dissatisfaction with the telephone service.
In CWE the machine uses speech, text from a keyboard and video to make the best assessment about the conversation partner’s emotional state. This is shown by Figure 1 where you can see that three blocks are dedicated to extracting emotion in 3 modes. The 3 estimated emotions are feed to another block which is tasked to make a final decision.
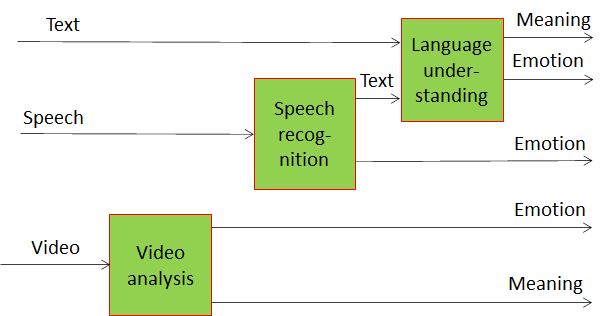
Figure 1 – Emotion extraction from text, speech, and video
The first three blocks starting from the left-hand side can be implemented as neural networks. But MPAI does not wish to disenfranchise those who have invested for years in traditional data processing solutions and have produced state-of-the-art technologies. MPAI seeks to define standards that are, as far as possible, technology independent. Therefore, in a legacy context Figure 1 morphes to Figure 2
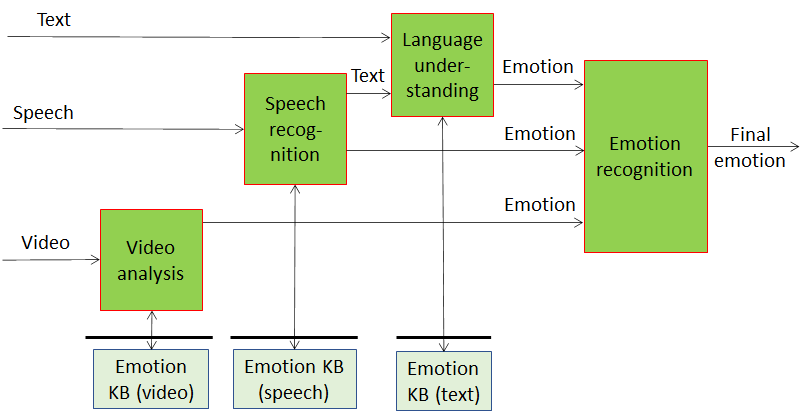
Figure 2 – Emotion extraction using legacy technologies
In the system of Figure 2, each of the 3 initial blocks extracts features from the input data and uses a vector of features to query an appropriate Knowledge Base that responds with one or more candidate emotions.
Actually, Video analysis and Language understanding do more than just providing emotion information. This is seen in the following Figure 3 where the two blocks additionally provide Meaning, i.e., information extracted from the text and video such as question, statement, exclamation, expression of doubt, request, invitation etc.
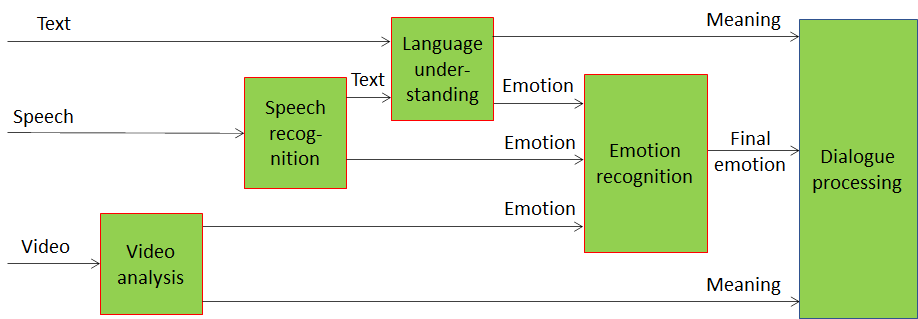
Figure 3 – Emotion and meaning enter Dialogue processing
Meaning and emotion are fed into the Dialogue processing component. Note that in a legacy implementation Dialogue processing, too, needs access to a Dialogue Knowledge Base. From now on, however, we will assume to deal with a full AI-based implementation.
Dialogue processing produces two streams of data, as depicted in Figure 4. The result is composed by:
- a data stream to drive speech synthesis expressed either as “Text with emotion” and “Concept with emotion”.
- a data stream to drive face animation in tune with the speech.
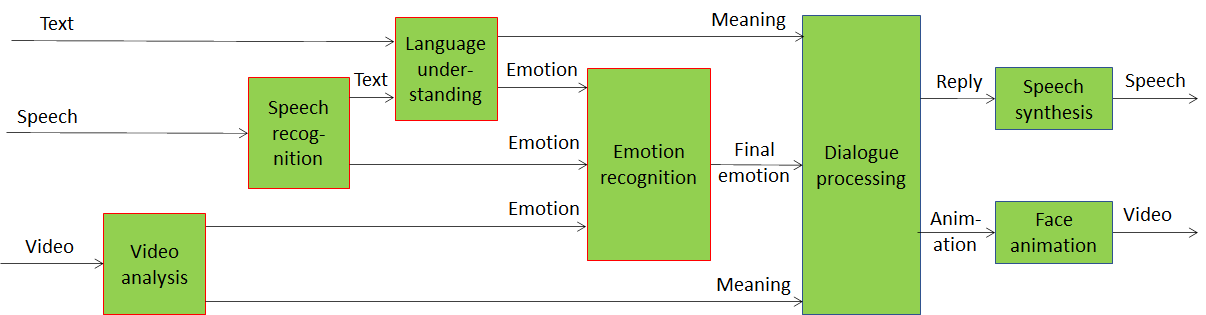
Figure 4 – End-to-end multimodal conversation with emotion
The last element, to move from theory to practice, is that you need an environment where you can place the blocks (that MPAI calls AI Modules – AIM) establish all connections, activate all timings, and execute the chain. One could even want to train or retrain the individual neural networks.
The technology that makes this possible by the MPAI AI Framework (MPAI-AIF) for which a Call for Technologies has been published on 2020/12/16 and whose responses are due on 2021/02/15. The full scheme of Multimodal conversation with emotion in the MPAI AI Framework is represented by Figure 5
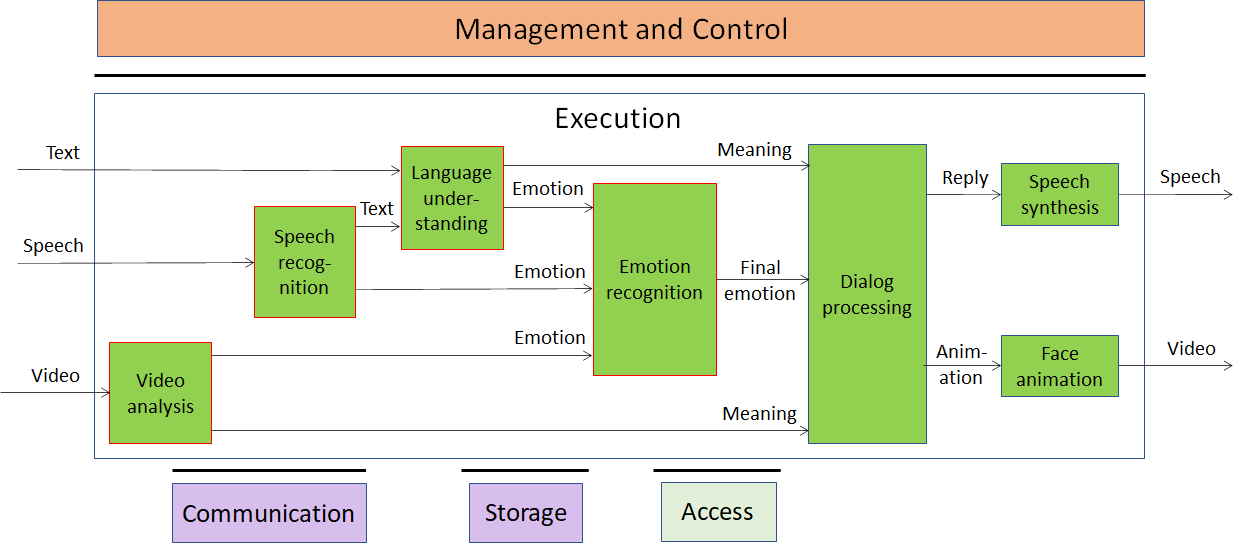
Figure 5 – Multimodal conversation with emotion in the MPAI AI Framework
The six components of MPAI-AIF are:
- Management and Control, in charge of the workflow
- Execution, the environment where the workflow is executed.
- AI Modules (AIM), the basic blocks of the system
- Communication, to handle both internal and external communication (e.g., Dialogue processing could be located on the cloud)
- Storage, for exchanging data between AIMs.
- Access, to access static or slowly changing external data.
What does MPAI intend to standardise in Conversation with emotion? In a full AI-based implementation
- The format of the Text leaving Speech recognition.
- Representation of Emotion
- Representation of Meaning
- Format of Reply: Text with Emotion or Concept with Emotion
- Format of Video anmation
In case of a legacy implementation, in addition to the above we need:
- Emotion KB (video) query format with Video features
- Emotion KB (speech) query format with Speech features
- Emotion KB (text) query format with Text features
- Dialoue KB query format
As you see MPAI standardisation is minimal, in tune with the requirement of standardisation to specify the minimum that is necessary for interoperability. In the MPAI case the minimum is what is required to assemble a working system using AIMs from independent sources.