Human-CAV Interaction operates based on the assumptionthat the CAV is impersonated by an avatar, selected/produced by the CAV owner, the users interacts with. The CAV avatar features are:
- Visible: head, face and torso.
- Audible: speech embedding the expression, e.g., emotion, that a human driver would display.
The CAV’s avatar is reactive to:
- Environment, e.g., it shows an altered face if a human driver has done what it considers an improper action.
- Humans, e.g., it shows an appropriate face to a human in the cabin who has made a joke gazing at them.
Other forms of interaction are:
- CAV authenticates humans interacting with it by speech and face.
- A human issues commands to a CAV, e.g.:
- Commands to Autonomous Motion Subsystem, e.g.: go to a Waypoint or display Full World Representation, etc.
- Other commands, e.g.: turn off air conditioning, turn on radio, call a person, open window or door, search for information etc.
- A human entertains a dialogue with a CAV, e.g.:
- CAV offers a selection of options to human (e.g., long but safe way, short but likely to have interruptions).
- Human requests information, e.g., time to destination, route conditions, weather at destination etc.
- Human entertains a casual conversation.
- A CAV monitors the passenger cabin, e.g.:
- Physical conditions, e.g., temperature level, media being played, sound level, noise level, anomalous noise, etc.
- Passenger data, e.g., number of passengers, ID, estimated age, destination of passengers.
- Passenger activity, e.g., level of passenger activity, level of passenger-generated sound, level of passenger movement, emotion on face of passengers.
- Passenger-to-passenger dialogue, two passengers shake hands, or passengers hold everyday conversation.
Reference architecture
Figure 4 represents the Human-CAV Interaction (HCI) Reference Model.
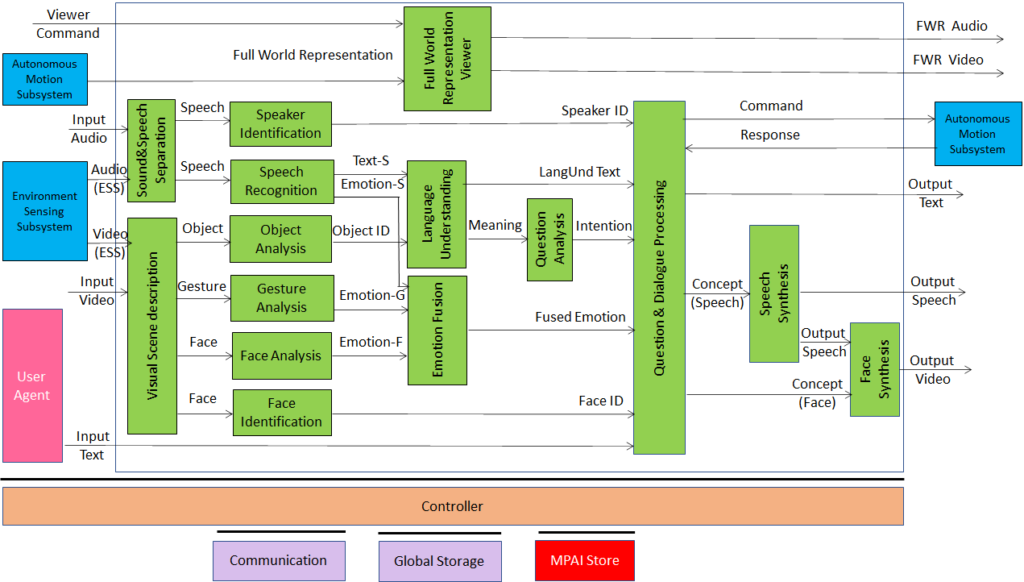
Figure 1 – Human-CAV Interaction Reference Model
The operation of the HCI is the following:
- A human approaches the CAV and identified as follows
- The speech of the human is separated from the environment audio.
- The human is identified by their speech.
- The human object is separated from the environment.
- The human is identified by their face.
- In the cabin:
- The locations and identities of the passengers are determined.
- Meaning and emotion are extracted from speech, face and gesture.
- Object information is extracted from video.
- Emotions are fused.
- Intention is derived.
- Expression (Speech) and Expression (Face) are produced to animate the CAV avatar with a realistic gazing.
- Human commands are issued and responses from Autonomous Motion Subsystem processed
- Full World Representation is presented to let humans get a complete view of the Environment.
Depending on the technology used (data processing or AI), the AIMs in Figure 1 may need to access external information, such as Knowledge Bases, to perform their functions.
Return to About MPAI-CAV