Towards Pervasive and Trustworthy Artificial Intelligence
MPAI celebrates its first 15 months of activity and the publication of 5 standards by publishing the first MPAI book.
With the printing industry sparing no efforts publishing books on Artificial Intelligence (AI), why should there be another that, in its title and subtitle, combines the overused words AI and trustworthy, with the alien words standards and pervasive?
The answer is that the book describes a solution that covers all the elements of the title: to effectively combine the AI and trustworthy words, but also to make AI pervasive. How? By developing standards for AI-based data coding.
Many industries need standards to run their business and have high respect for them. The MP3 standard put users in control of the content they wanted to enjoy, and the television – and now the video – experiences have little to do with how users approached audio-visual content some 30 years ago.
At that time, the media industry was loath to invest in open standards. The successful MPEG standards development model, however, changed its attitude. Similarly, the AI industry has been slow in developing AI-based data coding standards making proprietary solutions their preferred route.
This book provides the full description of mission, achievements and plans of the Moving Picture, Audio and Data Coding by Artificial Intelligence (MPAI) standards developing organisation. It describes how MPAI develops standards that can also be used, how standards can make AI pervasive and promote innovation, how MPAI gives users the means to make informed decisions about how to choose a standard implementation having the required level of trustworthiness.
The book is available on Amazon in electronic form (https://www.amazon.com/dp/B09NS4T6WN/) and in paper form (https://www.amazon.com/dp/B09NRKX74F).
MPAI-CAE standard
Standards for audio exist: MPEG-1 Audio layer II and layer III (so called MP3) and a slate of AAC standards serving all tastes offering efficient ways to store and transmit different types of mono, stereo and multichannel audio. MPEG-H offers ways to represent 3D audio experiences.
Never before, if not at the level of company products, however, was there a standard whose goal is not to preserve audio quality at low bitrates, but to improve it or, as the name of the standard – “Context-based Audio Enhancement”, acronym MPAI-CAE – says, enhance it.
Of course there are probably as many ways to enhance audio as there are target users, so what does audio enhancement mean and how can a standard be produced for such a goal?
The magic word that changes the perspective of the question is the word “context”. The MPAI-CAE standard identifies contexts in which audio can be enhanced. The next clarification comes from the fact that the standard is not monolithic, in other words, it identifies several contexts to which the standard can be applied.
Context #1: imagine that you have a sentence that you would like to be able to pronounce with a particular emotional charge: say, happy, or sad, or cheerful etc. or as if it were pronounced with the colour of a specific model utterance. If we were in a traditional encoder-decoder setting, there would be little to standardise. If you have the know how, you do it. If you don’t, you ask someone who has that know how to do it for you.
So, why should there be a standard for context #1?
To answer the question, I need to go back to a definition that I found years ago in the Encyclopaedia Britannica:
Standardisation, in industry: setting of guidelines that permit large production runs of component parts that are readily fitted to other parts without adjustment.
In practice the definition means that if there is a standard for nuts and bolts, and you have a standard nut, you can probably find someone who has the bolt to which your nut fits.
MPAI-CAE Context #1 is a straightforward application of the Encyclopaedia Britannica definition because it defines the components that can be assembled to make a system that lets you do one of the following:
- Receives your vocal utterance without colour and pronounces it using the speech features of the model utterance
- Receives your vocal utterance without colour, the indication of one or more emotions, the indication of a language and pronounces it with the particular emotion(s) and the “intonation” of the specified language.
There is one point that I must make clear. I said that the standard “defines the components” of the system, but I should have said that the “defines the interfaces of the components”. This is no different than the “nuts and bolts standard”. That standard defines neither the nuts nor the bolts. It defines the threading, i.e., the “interface” between the nut and the bolts.
Lets now go to a block diagram:
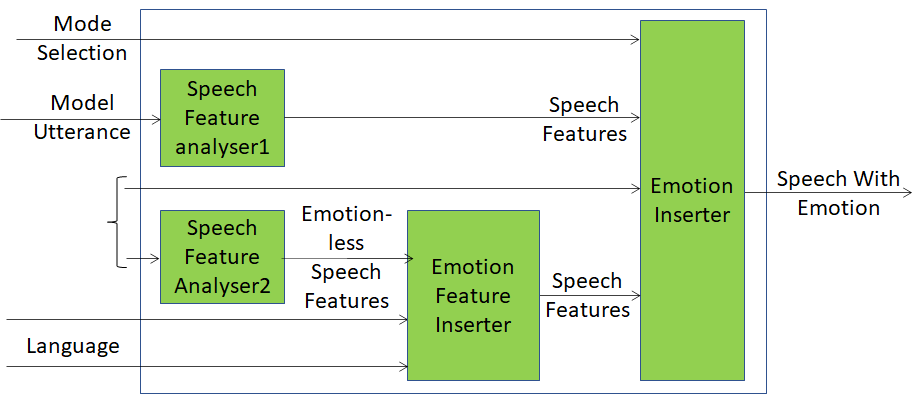
Figure 1 – Reference Model of Emotion Enhanced Speech
Here we see how the MPAI standardisation model works.
- Speech Feature Analyser2 is a very sophisticated technology component able to extract your speech features which are very specific of you and embedded deeply in your vocal utterances.
- Emotion Feature Inserter is an even more sophisticated technology component because it takes the Features of your Emotionless Speech, the Emotion, say, “cheerful” (whose semantics is defined by the MPAI-CAE standard), and the Language, and generates Speech Features that convey your personal speech features, the cheerful Emotion, and the specifics of the selected language.
- The Emotion Inserter, another very sophisticated component, receives the Speech Features from the Emotion Feature Inserter together with your Emotionless Speech and produces an emotionally charged vocal utterance according to your wishes.
A similar process unfolds for the upper branch of the diagram where a model utterance is used.
In principle, each of the identified components – that MPAI calls AI Modules (AIM) – can be re-used in other context. We will see how that is done because this is just the first MPAI-CAE context. There will be soon opportunities to introduce other contexts.
Context #2: Many audio archives urgently need to digitise their records, especially analogue magnetic tapes, because their life expectancy is short if compared to paper records. International institutions (e.g., International Association of Sound and Audio-visuals Archives, IASA; World Digital Library, WDL; Europeana) have defined guidelines, sometimes only partly compatible, but appropriate international standards are missing.
The Audio Recording Preservation use case (CAE-ARP) opens the way to effectively respond to methodological questions of reliability with respect to audio recordings as documentary sources, while clarifying the concept of “historical faithfulness”. The magnetic tape carrier may hold important information: multiples splices; annotations (by the composer or by the technicians) and/or display several types of irregularities (e.g., corruptions of the carrier, tape of different colour or chemical composition).
AI can have a significant impact on cultural heritage because it can make its safeguarding sustainable by drastically changing the way it is preserved, accessed, added value. To do that, audio archives, an important component of this heritage require significant resources in term of people, time, and funds.
CAE-ARP shows how AI can drastically reduce the resources necessary to preserve and make accessible analogue recordings. It provides a workflow for managing open-reel tape audio recordings. It focuses on audio read from magnetic tapes, digitised and fed into a preservation system together with the data from a video camera pointed to the head reading the magnetic tape. The output of the restoration process is composed by a preservation master file that contains the high-resolution audio signal and several other information types created by the preservation process. The goal is to cover the whole “philologically informed” archival process of an audio document, from the active preservation of sound documents to the access to digitised files.
Figure 2 depicts the CAE-ARP workflow. Its operation is concisely described below.
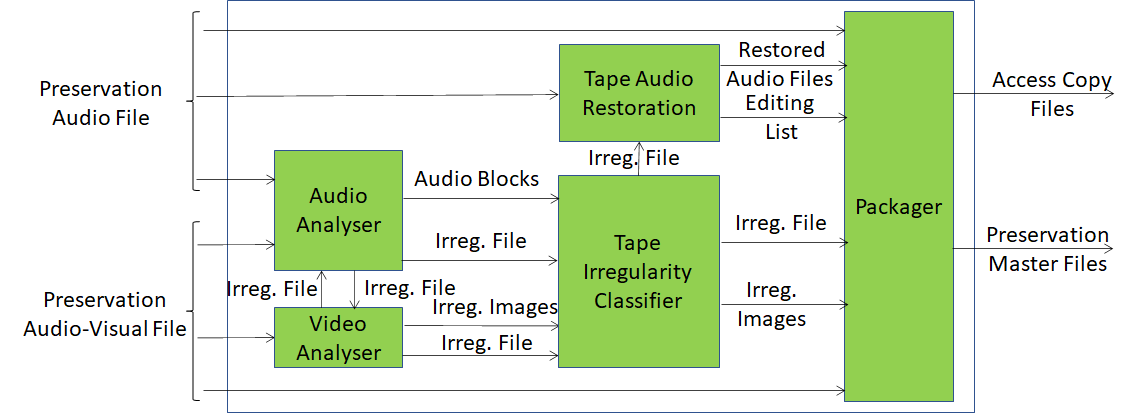
Figure 2 – Audio recording preservation
- The Audio Analyser and Video Analyser AIMs analyse the Preservation Audio File (a high-quality audio signal) and the Preservation Audio-Visual File (video of the reading head), respectively.
- All detected Audio and Image irregularities are sent to the Tape Irregularity Classifier AIM, which selects those most relevant for restoration and access.
- The Tape Audio Restoration AIM uses the irregularities to correct potential errors occurred at the time the audio signal was analogue-to-digital converted.
- The Restored Audio File, the Editing List (used to produce the Restored Audio File, the Irregularity Images, and the Irregularity File containing information about the irregularities) are inserted in the Packager.
- The Packager produces the Access Copy Files. These are used, as the name implies, to access the audio content and the Preservation Master Files, with the original inputs and data produced during the analysis, used for preservation.
The ARP workflow described above is complex and involves different audio and video competences. Therefore, the MPAI approach of subdividing complex systems in smaller components is well-suited to advance different algorithms and functionalities typically involving different professionals or companies.Currently, ARP is limited to mono audio recordings on open-reel magnetic tape. The goal is to extend it to more complex recordings and additional analogue carriers such as audiocassettes or vinyl.
MPAI-CAE includes technology to handle two more context. They will be analysed in the future. Those interested can have a look at https://mpai.community/standards/resources