HighLight
- Video recordings and ppt files of five online presentations available
- Inch by inch End-to-End Video coding (MPAI-EEV) improves
- The MPAI Metaverse Model presented at IEEE Symposium on Emerging Metaverse
- Progress in standardisation of Qualifiers
- Meetings in the coming October/November meeting cycle
Video recordings and ppt files of five online presentations available
MPAI-48 was a watershed for MPAI: four revised standards and one major reference software implementation:
- Reference Software: Television Media Analysis (MPAI-TAF) V1.0
- Standard: Object and Scene Description (MPAI-OSD) V1.1
- Standard: Portable Avatar Format (MPAI-PAF) V1.2
- Standard: MPAI Metaverse Model (MPAI-MMM) V1.0
- Standard: Multimodal Conversation (MPAI-MMC) V2.2
If you missed the presentations, you can find the video recordings and the ppt slides at https://mpai.community/community/presentations/
Inch by inch End-to-End Video coding (MPAI-EEV) improves
ackground. MPAI-EEV is a standard project focused on developing an AI-based End-to-End (E2E) video coding standard. It aims to enhance video compression by utilizing AI technologies, moving beyond traditional data coding methods. As a technical body free from legacy IP constraints, MPAI seeks to ensure that the MPAI-EEV study meets the needs of those who require not only environments where academic knowledge is promoted but also a body that develops common understanding, models, and eventually standards-oriented E2E video coding.
Research objectives and process. MPAI-EEV group began with a functional requirement analysis for a novel video standard with AI technology, considering the use case study and corresponding verification models. MPAI-EEV project officially kicked off in Dec. 2021, studied the latest research literature, and constructed the reference model with the purpose of investigating the evidence for video codecs with the ability beyond existing standards. The ultimate goal of EEV lies in finding the near-optimal NN structure such that both video coding and network coding can benefit.
Several major milestones have been achieved from multiple perspectives. The group has released the working draft of the state-of-the-art E2E video coding solutions. As of Oct. 2024, MPAI-EEV has officially released five versions of the verification model with tags from EEV-0.1 to EEV-0.5. Additionally, the EEV aims to develop neural codecs for unmanned-aerial-vehicles (UAV) video coding and establish a public benchmark for this task. Related works [1-3] have been published in ACM Multimedia, IEEE Transactions on Circuits and Systems for Video Technology and IEEE Data Compression Conference.
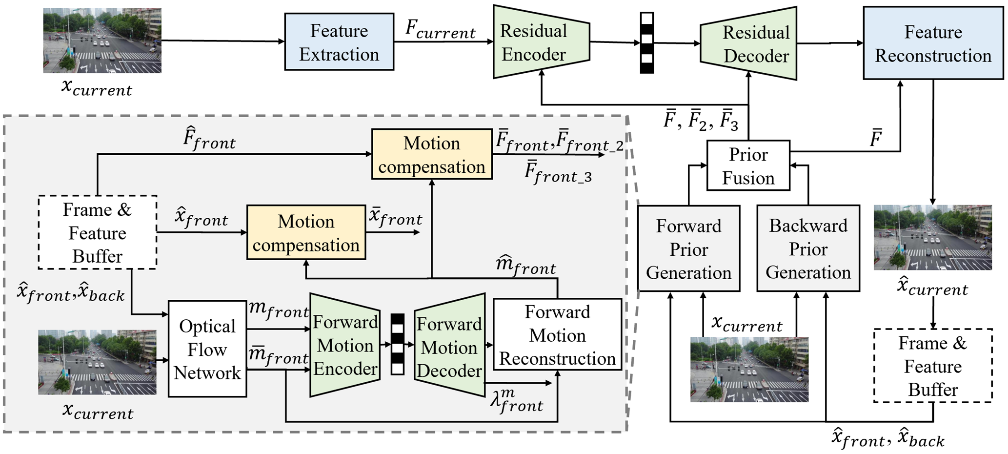
EEV-0.5: scaled hierarchical bi-directional prediction structure. EEV-0.5 model utilizes a scaled hierarchical bi-directional prediction structure to effectively capture temporal correlation among frames to obtain higher coding efficiency. By using parameter-shared motion codecs and efficient information fusion strategies, as well as introducing the concept of trust-worthy motion modeling, EEV-0.5 can get more accurate prediction features. Scaled motion priors and Interlayer rate-distortion adjustments can further reduce the overall bit rate.
Innovative Motion Coding and Information Fusion. A significant development is the separate encoding of forward and backward motion vectors. By employing two parameter-shared codecs instead of a single one, EEV-0.5 enhances the precision of motion dynamics. For fusion, features are extracted for three scales and then aligned and fused separately. Such a fusion strategy not only yields reliable prior information but also allows the subsequent residual coding process to have the exact same model design as the low-delay frameworks, thus simplifying the porting of state-of-the-art P-frame models to the proposed algorithm.
Scaled Motion Priors from Temporal Contexts. According to the basic assumptions of optical flow method, it is not difficult to speculate that the optical flow between the frame to be encoded and the reference frame should have a close temporal correlation with the optical flow between two reference frames. Thus, EEV-0.5 utilizes the optical flow between forward and backward reference frames prior to further take advantage of bidirectional prediction. This technique capitalizes on temporal context to refine the accuracy of motion predictions.
Trustworthy Motion Modeling. Recognizing the variable quality of reference frames in a hierarchical structure, EEV-0.5 introduces the concept of trustworthy motion modeling to evaluate the effectiveness of each reference. The motion decoder splits its output into predictive motion information and a confidence score. This score plays a crucial role in adjusting the model’s reliance on forward and backward predictions. The system dynamically modifies its predictions based on the quality of available reference information, improving the overall motion modeling process.
Rate-distortion Optimization Techniques. To further improve video compression, rate-distortion optimization is used to allocate bit rates effectively. The codec structure and loss function are modified to introduce a scalar function that adjusts bit rate allocation according to the desired quality, adjusting the coding rates across different layers of B-frames to enhance overall performance.
Reference diagram
The EEV0.5 Reference Model is given in the figure.
Tests and codes. The experimental results demonstrate that our model significantly outperform existing uni-directional and bi-directional NVC models in coding efficiency for HEVC Class B-E sequences when the intra-period was set to 16 for both PSNR and MSSSIM metric. The code is available https://github.com/yefeng00/DVC_with_Scaled_Hierarchical_Bi_directional_Motion_Model.
References
[1] Feng Ye, Li Zhang, Chuanmin Jia, Deep Video Compression with Scaled Hierarchical Bi-directional Motion Model, Proceedings of the 32nd ACM International Conference on Multimedia, 2024
[2] Chuanmin Jia, Feng Ye, Fanke Dong, KaiLin, Leonardo Chiariglione, Siwei Ma, Huifang Sun, Wen Gao, MPAI-EEV: Standardization Efforts of Artificial Intelligence based End-to-End Video Coding, IEEE Transactions on Circuits and Systems for Video Technology, 2023.
[3] Chuanmin Jia, Feng Ye, Huifang Sun, Siwei Ma, Wen Gao, Learning to Compress Unmanned Aerial Vehicle (UAV) Captured Video: Benchmark and Analysis. IEEE Data Compression Conference, 2024.
The MPAI Metaverse Model presented at IEEE Symposium on Emerging Metaverse
The MPAI Metaverse Model (MPAI-MMM) got three exposure opportunities at the IEEE Symposium on Emerging Metaverse held in Bellevue, WA on 21st October – as a regular paper, as an invited paper, and at a panel at the Standardisation panel.
The invited paper focused on the key element enabling interoperability – the categories that are relevant to the metaverse, the methods to represent them, and the language enabling a metaverse to express the metaverse-related matters that are relevant to it.
This list of results achieved by MMM standardisation were presented as
- Development of an informative operation model:
- An M-Instance behaves as if it were made of interacting Processes.
- A Process can be a Device, a User, a Service, or an App.
- Specification of:
- Functional requirements of 30 Actions
- JSON syntax and semantics of 65 Items.
- Qualifiers conveying info on technology used by Items.
- Human readable MMM- Script
- Backus-Naur form of MMM for inter-Process communication.
- 4 MMM Profiles.
- Description of 9 use cases with MMM Script to validate specification.
The focus of participation in the panel discussion was on Qualifiers. The MMM can be implemented as an interoperable metaverse because it does not specify technologies – most of them not even fully available today. Technologies are signalled by Qualifiers which means that it is possible to plug in technologies as a necessary but second-priority components of an implementation.
Progress in standardisation of Qualifiers
The MPAI blog has already presented the basic “Qualifier” idea in a post. Qualifiers are ancillary data attached to primary data to provide information about the primary data itself that is processable by a machine (e.g., an AI Module). Qualifiers are subdivided in three classes of data: Sub-Types (e.g., colour vs black and white for Visual Data), Formats (e.g., the Data or the File or the Streaming Format), and Attributes (e.g., semantic information about the primary data such as the violin player ID in Audio Data or the ID of the device that captured the Audio Data). The combination of data – e.g., Audio – and Qualifiers is called Object – i.e., in this case, Audio Object.
This short article describes what has been implemented so far in the Qualifier standards for three types of data: media, metaverse, and machine learning model published in three successive versions of Technical Specification: Data Types, Formats and Attributes (MPAI-TFA).
MPAI-TFA V1.0 provided the first batch of Qualifiers for media: Text, Speech, Audio, Visual, 3D Model, and Audio-Visual. The first remark is that there is a lot of ancillary data for media data. There are many forms of colour information for Visual Data, and many are the Formats and the number of Attributes that include not only the Device ID but also the position and orientation of the device, the identity of the speaker that utter Speech Data etc.
MPAI-TFA V1.1 enables MPAI to implement the “no-technology” strategy for the MMM. Qualifiers are defined for Contract, Discovery, Information, Interpretation, Location, Program, Rules and can be used with Media Qualifiers in the metaverse. Here the main goal is to provide a baseline specification for each of the data type (with the exclusion of Rules) with a minimum of specifications to facilitate the initial use of the MMM.
MPAI-TFA V1.2 specifies the Machine Learning Model Qualifier. This was done together with the very specification of the Machine Learning Model Data Type. The focus of the Qualifier is to provide the capability to signal which regulation it complies with, the certification status and the duration of the validity.
MPAI-TFA 1.1 is final while V1.2 is published for community comments. Comments should be directed to secretariat@mpai.community by the 16th of November 2024 to enable MPAI to consider them at the time the final version of the standard will be produced.
Meetings in the coming October/November meeting cycle