Highlights
- MPAI-EEV Monthly Update: Breakthrough in Random Access Coding Efficiency
- MPAI and AI Agents
- Meetings in the coming February/March 2025 meeting cycle
MPAI-EEV Monthly Update: Breakthrough in Random Access Coding Efficiency
Deep neural networks have made significant advances in various fields, and their application to video coding has garnered increasing attention for their ability to enrich the horizon of image and video coding thanks to their non-linear modeling. The MPAI End-to-End Video coding project (MPAI-EEV) targets longer-term needs for fully neural-network-based video compression. This is a paradigm shift in the video coding field..
Recently, Evidence could be observed that they achieve promising rate-distortion performance on commonly adopted test benchmarks and realize comparable performances with the state-of-the-art standardized coding methods. MPAI EEV has achieved a pivotal milestone, demonstrating better BD-rate reduction over VVC random access configuration scenarios under standard test conditions. Our novel hierarchical motion compensation (HMC) and adaptive motion-prior propagation (AMP) algorithms exhibited superior Rate Distortion (RD) performance across different test sequences.
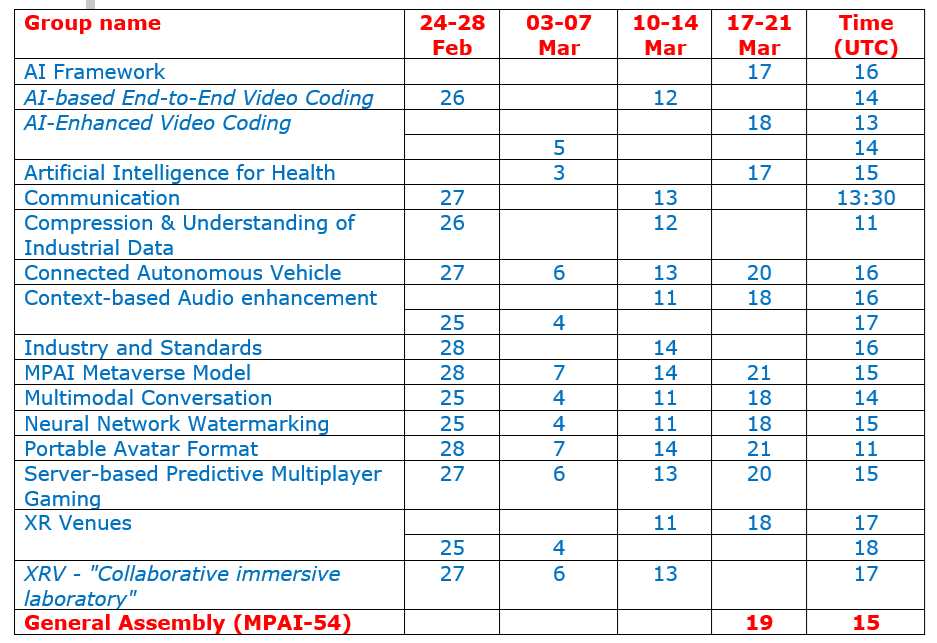
Figure 1 is the current reference model where the red stars indicate that the neural network models have an augmented number of parameters (circa 20% on average).
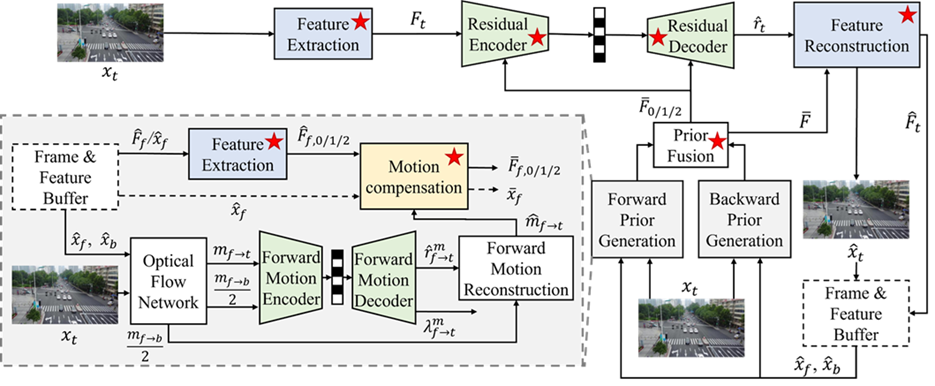
Figure 1 -Reference Model of EEV-0.6
MPAI and AI Agents
The idea of artificial entities having capabilities, perceiving the environment, and performing autonomous actions to achieve goals is not new. The Foundation for Intelligent Physical Agents (FIPA) was established in 1995 with the goal of developing standards for intelligent agents. FIPA produced several specifications and facilitated the development of several agent platform such as JADE and FIPA OS.
The great recent advances in Artificial Intelligence applied to the existing notion of intelligent agent have generated animated debate that has spun new terms such as Agentic AI and AI Agents. If you look at what the users of these terms mean, you will find a very wide range of abilities. A quick search revealed some 20 definitions from which we extracted the following abilities an AI Agent can have:
- Perceive the environment, make autonomous decisions, perform actions, achieve specific objectives [1].
- Perform actions on behalf of a user/system, design workflow, select from available tools [2]
- Perform actions within their roles [3].
- Understand and interpret questions [4].
- Generate action plan [5].
- Interact with environment [6].
- Communicate with other AI Agents [7].
- Learn or acquire knowledge [8].
- Rely on experience [9].
MPAI is studying AI Agents, which it calls Perceptible and Agentive AI (PAAI), defined as systems able to:
- Capture data from universe, metaverse, or machines/PAAIs.
- Describe data, combining also machines/PAAIs’.
- Interpret its descriptors, combining also other machines/PAAIs’.
- Reason about interpretations, considering also other machines/PAAIs’.
- Produce conclusions, considering also other PAAIs/humans’.
- Explain the path that led the PAAI to reach that decision.
- Actuate decisions in the universe or metaverse.
- Learn or acquire knowledge.
- Store experiences for possible later use and retrieve.
MPAI is well placed to address PAAIs thanks to its 14 developed standards.
As captured data may come in many forms, there is a need to have some means to navigate this space. For example, the entry point of the Live Theatrical Performance (XRV-LTP) standard being developed:
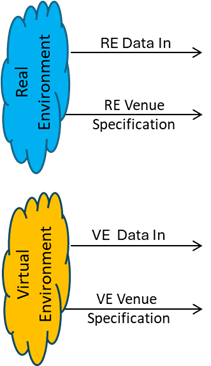
Figure 2 – Data acquisition from theatre and associated metaverses
There is a wide variety of data types each with their own formats that may change from a theatre to another theatre (and from a metaverse to another metaverse). XRV-LTP handles this problem by assuming that each theatre (venue) has a specification of the data types it uses. A Venue Specification references the entries of the Data Types, Formats, and Attributes (MPAI-TFA) standard, described in a previous newsletter. Because of the large number of existing data types, and the new ones that are expected, the activity of adding entries to the (MPAI-TFA) standard should be described as being a “permanent” one.
MPAI has a significant inventory of data description results (“descriptors”), for instance:
- Audio: audio scene descriptors.
- Finance: financial and organisation descriptors.
- Visual: visual scene descriptors.
- Audio-visual scene descriptors.
For instance, a Connected Autonomous Vehicle (CAV) interacting with a human perceives its audio-visual environment and produces a range of descriptors (Figure 2):

Figure 3 – Audio-Visual Scene Descriptors in a CAV perceiving its environment
On the right-hand side of Figure 2 you can see a variety of descriptors that are produced by the Audio-Visual Scene Description AI Module.
MPAI can claim even richer results in data interpretation (“interpretors”). For instance:
- Entity-to-entity communication (entity is a human or a machine): personal status describing the declared or inferred Cognitive State, Emotion, and Social Attitude of an entity.
- Meaning (from a text).
- Summary (of a multi-entity conversation).
- Interpretation (of multimodal data).
- Identification of an object based on taxonomy.
The AI Framework (MPAI-AIF) standard (Figure 3) provides a way for an AIF (a basic form of PAAI) to communicate with a human or another AIF:
Figure 4 – The AI Framework (MPAI-AIF) standard
In Figure 3, User Agent is tasked with interacting with the user (a human). Input data of known syntax and semantics enters the AIF and the AIF produces data of known syntax and semantics. This data can be communicated to another AIF as is the case for the Communicating Autonomous Vehicle (MPAI-CAV) depicted in Figure 4:
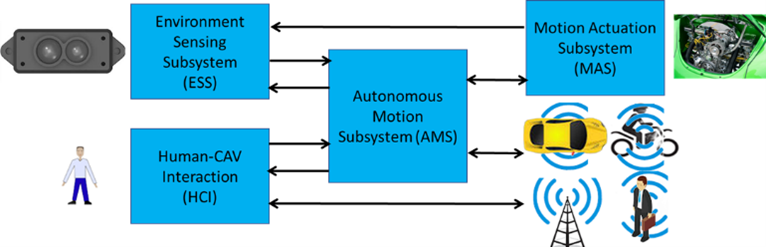
Figure 5 – Communicating Subsystems in MPAI-CAV
Arrows indicate data of known syntax and semantics that is exchanged between CAV subsystems.
Existing projects have required and will require more “Reasoning” functionalities. Most MPAI-MMC use cases and the MPAI-HMC Communicating Entities in Context use case need an Entity Dialogue Processing (MMC-EDP) AIM that, in its simplest form, produces a text in response to a text. In its most complex configuration of the EDP (Figure 5), the AIM uses the descriptors of a scene of which the entity is part, the ID of an object, the identity of another entity and its personal status to provide not only the Text but also the personal status of the avatar representing the AIF that utters the response.
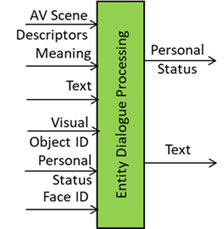
Figure 6 – Entity Dialogue Processing
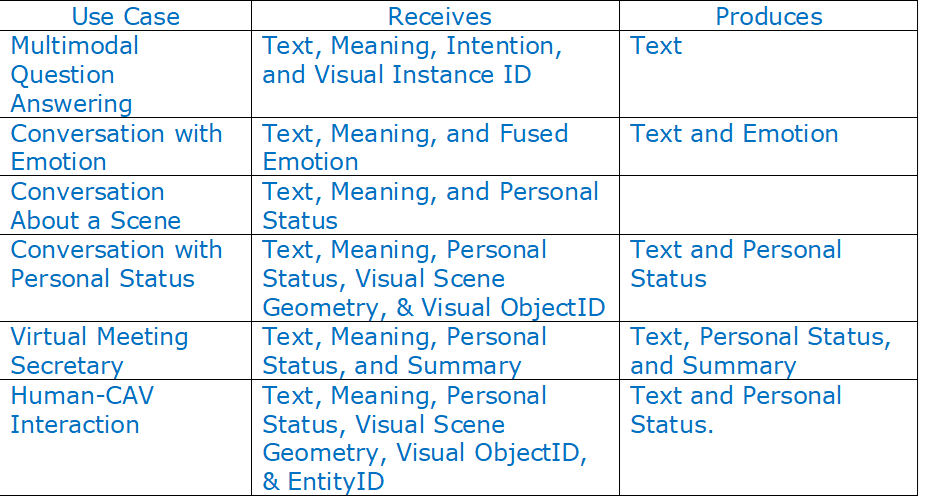
Table 1 lists different configurations of input and output data in sevean different use cases.
Table 1 – Data received and produced by MMC-EDP in different use cases
Meetings in the coming February/March 2025 meeting cycle