Highlights
- Presentation of Autonomous Users in metaverse
- New project for Autonomous Users in an MMM metaverse instance
- Meetings in the November 2025 cycle.
Presentation of Autonomous Users in metaverse
The Call for Technologies: Pursuing Goals in metaverse (MPAI-PGM) – Autonomous User Architecture (AUA) V1.0 addressing a new project leveraging MPAI competence and standards integrated by new technologies target of the Call will be presented online on 2025/11/17:
Register
New project for Autonomous Users in an MMM metaverse instance
The Mayflower Pilgrims left a world they considered oppressive to a new one that they expected would be challenging but more hospitable. With the development of one of its standards – the MPAI Metaverse Model – some MPAI members virtually left this world not because it was unfriendly but because they thought that the new virtual one would be more or differently attractive.
Like the Pilgrims, these MPAI members had to face a new world that they wanted to populate. As they could not put humans in the new world (populating a virtual world with atoms remains an unsolved problem), these MPAI members populated theirs with Processes that represented them – called Users – and digital versions of things in this world they called Items. It was not so difficult to populate it with “native” things of the new world because digital things have been in existence for a long time.
The idea of populating the new world with “native” Users (Processes), i.e., agents endowed with the capability of autonomous agency is appealing. The MPAI Metaverse Model – Technologies (MMM-TEC) standard assumes that the new world – called a metaverse instance (M-Instance) – is populated by Processes acting on Items (any “thing” in the metaverse) and/or other Processes. Some Processes – called Users – represent humans: Human Users (H-Users) are directly operated by humans, while Autonomous Users (A-Users) have a high degree of operational autonomy. Both types of Users may be rendered as avatars called Personae.
MMM-TEC specifies technologies enabling Users to perform a variety of Actions on things in an M-Instance (Items) such as sensing data from the real world or moving Items in the M-Instance, possibly in combination with other Processes. However, MMM-TEC is silent on how an A-User reaches the decision of performing an Action.
MPAI has decided to develop a new standard that specifies what native M-Instance Users – the A-Users – do when they decide to do something to achieve a Goal in an M-Instance. MPAI has assembled a considerable repertory of technologies relevant to the PGM-AUA standard project but needs more technologies to achieve the project goal. Therefore, the 61st MPAI General Assembly (MPAI-61) has published the Call for Technologies Pursuing Goals in metaverse (MPAI-PGM) – Autonomous User Architecture (AUA). The Call requests interested parties – irrespective of their membership in MPAI – to submit responses that may enable MPAI to reach the goal of developing an A-User Architecture standard that is both robust and attractive to implementers and users.
What is the scope of this planned standard? An initial formulation is the following: PGM-AUA will specify functions and interfaces by which an A-User interacts with another User, either A-User or H-User. Therefore, the term “User” means “conversational partner in the metaverse”, whether autonomous or driven by a human. A-Users can capture text and audio-visual information originated by, or surrounding, the User, extract the User State, i.e., a snapshot of the User’s cognitive, emotional, and interactional state; produce an appropriate multimodal response, rendered as a speaking Avatar; and also move in the relevant virtual space.
One possible approach to the A-User standard is the use of a very powerful Large Language Model able to use spatial and media information. As this solution is hard to extend, MPAI assumes instead to give spatial, audio-visual, and User description information to a relatively simple Large Language Model with basic language and reasoning capabilities.
An A-User requires many technologies that must be integrated so that the architecture is:
- Modular, i.e., able to swap or update modules independently from other modules.
- Transparent, i.e., able to perform clear roles and expose well-defined interfaces.
- Extensible, i.e., able to add or replace specific competences as needed.
An obvious choice to achieve this integration is the MPAI AI Framework (MPAI-AIF) standard, already provides the necessary infrastructure underpinning the A-User on which the necessary technologies can be added. MPAI-AIF specifies an environment composed of an AI Workflow (AIW) representing the application (the A-User, in this case) as composed of AI Modules (AIMs).
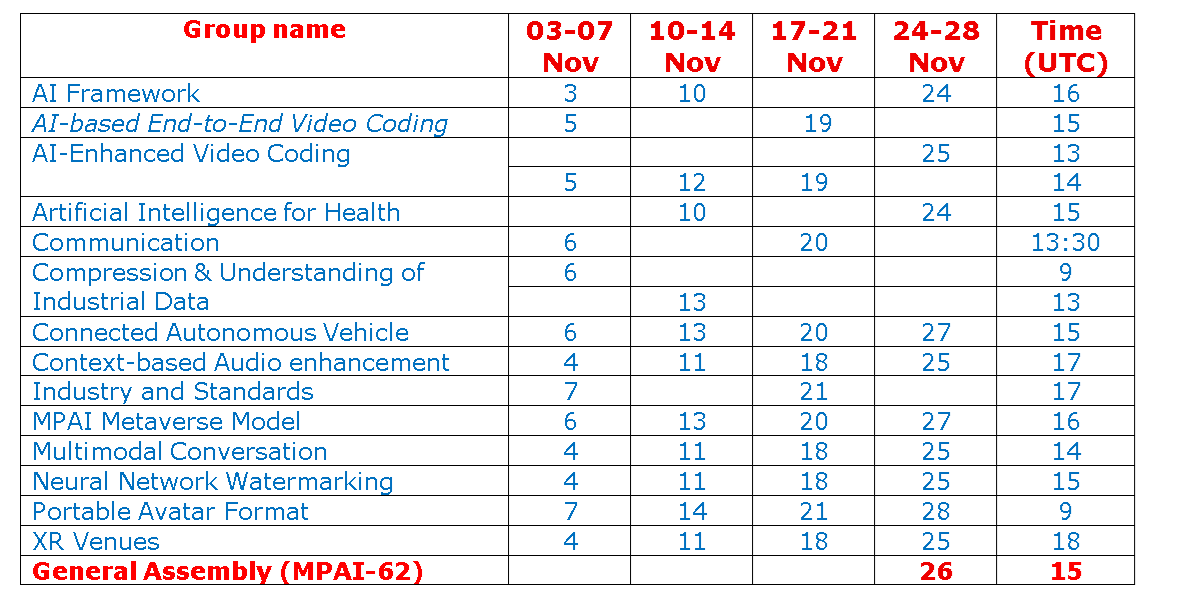
The figure represents an initial diagram of the A-User architecture.
Let’s walk through this model.
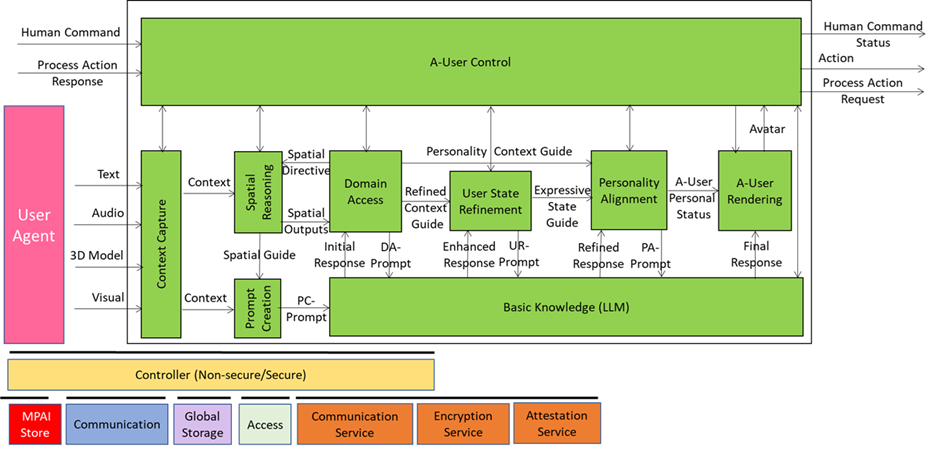
The A-User Control AIM drives A-User operation by controlling how it interacts with the environment and performs Actions and Process Actions based on the Rights it holds and the M-Instance Rules by:
- Performing or requesting another Process to perform an Action.
- Controlling the operation of AIMs, in particular A-User Rendering.
The human may take over or modify the operation of the A-User Control.
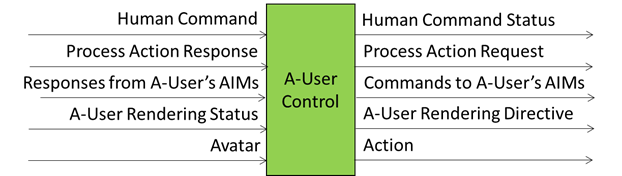
The Context Capture AIM, prompted by the A-User Control, perceives a particular location of the M-Instance – called M-Location – where the User i.e., the A-User’s conversation partner, is rendering its Avatar. The result of the capture is called Context, a time-stamped structured snapshot representing the initial A-User understanding of the M-Location. Context is composed of
- Audio-Visual Scene Descriptors describing the spatial content.
- User State, describing the User’s cognitive, emotional, and attentional posture within the environment.
The Spatial Reasoning AIM is analyses Context and sends:
- Audio and Visual Spatial Output, i.e., spatial relationships, referent resolutions, and interaction constraints, to the Domain Access AIM seeking additional domain-specific information.
- Audio and Visual Spatial Guides, i.e., audio source relevance, directionality, and proximity (Audio) and object relevance, orientation, proximity, and affordance (Visual) to the Prompt Creation AIM to enrich the User’s spoken or written input with additional User information before sending PC-Prompt to Basic Knowledge, a basic LLM. PC-Prompt includes
- User Text and User State (from Context Capture).
- Audio and Visual Spatial Guide (from Spatial Reasoning).
Spatial Reasoning is specified as two separate AIMs.
Basic Knowledge sends Domain Access an Initial Response containing a core answer as a direct response to the PC-Prompt and general reasoning based on foundational LLM capabilities.
Domain Access
- Processes and responds to two flows:
- Audio and Visual Spatial Output:
- Accesses domain-specific models, ontologies, or M-Instance services.
- Returns Audio and Visual Spatial Directive to inject contextual priors, scene-specific logic, and task relevance into the reasoning loop of Spatial Reasoning to improve its fidelity of spatial interpretation.
- Initial Response:
- Accesses domain-specific models, ontologies, or M-Instance services to retrieve:
- Scene-specific object roles (e.g., “this is a surgical tool”)
- Task-specific constraints (e.g., “only authorised Users may interact”)
- Semantic affordances (e.g., “this object can be grasped”)
- Returns to Basic Knowledge DA-Prompt that includes, initial reasoning, spatial semantics, domain overlays, and User/task constraints
- Accesses domain-specific models, ontologies, or M-Instance services to retrieve:
- Produces two flows:
- Refined Context Guide:
- Includes a structured object with:
- Updated User descriptors
- Scene salience and relevance
- Interaction history and inferred goals
- Enables User State Refinements to update User State and to generate a UR-Prompt that reflects the refined understanding.
- Includes a structured object with:
- Refined Context Guide:
- Audio and Visual Spatial Output:
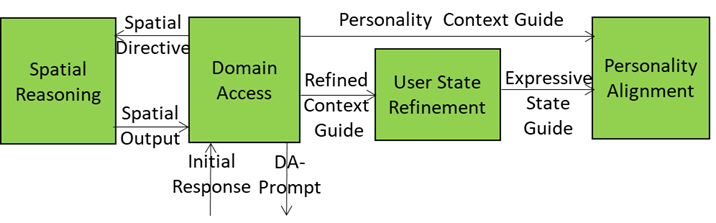
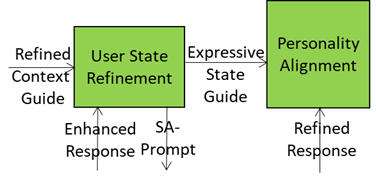
Basic Knowledge produces and sends Enhanced Response to the User State Refinement AIM.
User State Refinement refines its understanding of User State, produces and sends to:
- Basic Knowledge a UR-Prompt.
- Personality Alignment AIM Expressive State Guide, a structured representation of the A-User’s current User State, informing Personality Alignment how to adopt an A-User Personality that is emotionally effective and contextually appropriate.
Basic Knowledge produces and sends to Personality Alignment a Refined Response.
Personality Alignment
- Selects a Personality based Refined Response and Expressive State Guide and conveying a variety of elements such as:
- Expressivity, e.g.:
- Tone, e.g., formal, casual, empathetic, assertive.
- Tempo, e.g., fast, slow, rhythmic.
- Expressivity, e.g.:
- Gesture style, e.g., expansive, restrained, animated.
- Facial dynamics, e.g., smile frequency, gaze behaviour, eyebrow movement.
- Etc.
- Behavioural Traits, e.g.:
- Verbosity level
- Use of metaphors or humour
- Degree of emotional expressiveness
- Type of role: assistant, mentor, negotiator, entertainer, etc.
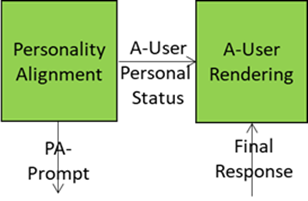
- Formulates and sends
- An A-User Personal Status (using MPAI-specified Personal Status) reflecting the Personality to A-User Rendering.
- A PA-Prompt to Basic Knowledge reflecting:
- Speech modulation instructions (e.g., pitch, emphasis)
- Facial expression timing and intensity
- Gesture choreography
- Synchronisation cues across modalities
Basic Knowledge sends a Final Response that conveys semantic content, contextual integration, expressive framing, and personality consistence.
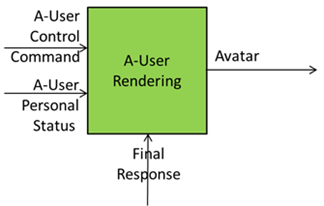
A-User Rendering uses Final Response and A-User Personal Status to synthesise a speaking Avatar and A-User Control Command from A-User Control to shape the speaking Avatar.
The complexity of the model has prompted MPAI to extend its Call for Technologies practice. In addition to the usual Call for Technologies, Use Cases and Functional Requirements, Framework Licence, and Template for Responses the Call makes reference to Tentative Technical Specification, a document drafted as if it were an actual Technical Specification. Respondents to the Call are free to comment on, change, or extend the Tentative Technical Specification or to propose anything else relevant to the Call but unrelated to it.
Anybody, irrespective of the status of their MPAI membership may respond to the Call. Responses to this Call shall reach the MPAI Secretariat by 2026/01/21T23:59.
Appropriate MPAI working groups will thoroughly review the Responses and retain those appropriate for the future PGM-AUA standard. MPAI will select suitable technologies from those submitted in Responses, but is not obligated to select a particular proposal, or any proposal. Respondents will be encouraged to join MPAI and those whose Responses will be accepted in full or in part, shall join MPAI or MPAI will discontinue consideration of those selected technologies.
MPAI organises two online presentations with similar content on 2025/11/17. To attend register:
Meetings in the November 2025 cycle.