1 Introduction
Technical Specification: Portable Avatar Format (V1.2) enables an implementation of the Avatar-Based Videoconference Use Case. Table 2 lists all Data Types required by the Portable Avatar Data Type and MPAI Technical Specifications supporting them. Chapter 7 provides the full specification including references of the MPAI-PAF Data Formats.
2 Scope of Use Case
The MPAI-PAF Avatar-Based Videoconference (PAF-ABV) Use Case enables a form of videoconference held in a Virtual Environment populated by Avatars representing humans showing their visual appearance and uttering their voices. Figure 2 depicts the system composed of four types of subsystems:
- Videoconference Client Transmitters
- Avatar Videoconference Server
- Virtual Meeting Secretary
- Videoconference Client Receivers.
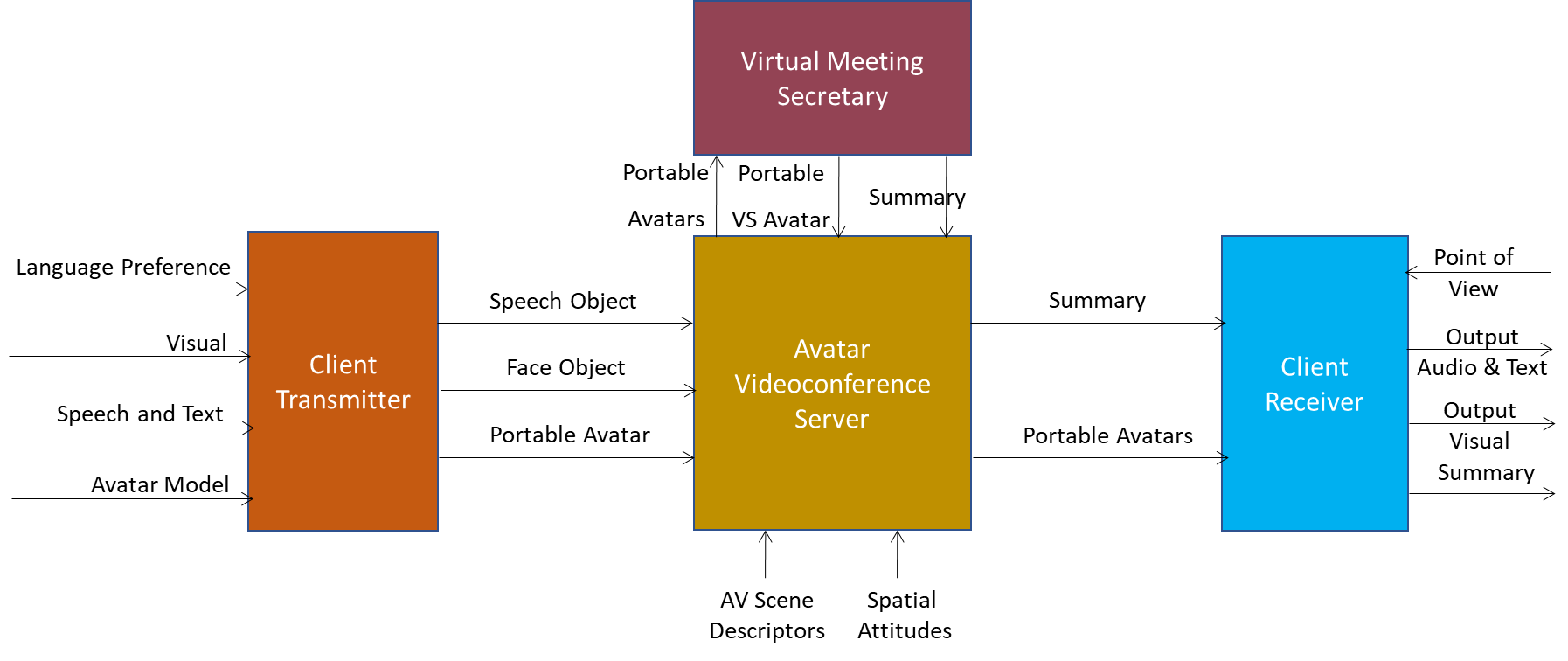
Figure 2 – Avatar-Based Videoconference end-to-end diagram
The components of the PAF-ABV system:
- participant: a human joining an ABV either individually or as a member of a group of humans in the same physical space.
- Audio-Visual Scene: a Virtual Audio-Visual Environment equipped with Visual Objects such as a Table and an appropriate number Cf chairs and Audio Objects described by Audio-Visual Scene Descriptors.
- Portable Avatar: digitally represents a human participant as part of a Portable Avatar Format (PAF).
- Client Transmitter:
- At the beginning of the conference:
- Receives from Participants and sends to the Server Portable Avatars containing the Avatar Models and Language Preferences.
- Sends to the Server Speech Object and Face Object for Authentication.
- Continuously sends to the Server Portable Avatars containing Avatar Descriptors and Speech.
- At the beginning of the conference:
- The Avatar Videoconference Server
- At the beginning:
- Selects the Audio-Visual Descriptors, e.g., a Meeting Room.
- Equips the Room with Objects, i.e., Table and Chairs.
- Places Avatar Models around the table with a given Spatial Attitude.
- Distributes Environment and Portable Avatars containing Avatars Models, and their Spatial Attitudes to all Receiving Clients.
- Authenticates Speech and Face Objects and assigns IDs to Avatars.
- Sets the common conference language.
- Continuously:
- Translates Speech to Participants according to their Language Preferences.
- Sends Portable Avatars containing Avatar Descriptors, Speech, and Spatial Attitude of Participants and Virtual Meeting Secretary to all Receiving Clients and Virtual Meeting Secretary.
- At the beginning:
- Virtual Meeting Secretary is an Avatar not corresponding to any Participant that continuously:
- Uses a common meeting Language.
- Understands Avatars’ utterances and extracts their Personal Statuses.
- Drafts a Summary of its understanding of Avatars’ Text and Personal Status.
- Displays the Summary either to:
- Outside of the Virtual Environment for participants to read and edit directly, or
- The Visual Space for Avatars to comment, e.g., via Text.
- Refines the Summary.
- Sends its Portable Avatar containing its Avatar Descriptors to the Server.
- Client Receiver:
- At the beginning:
- Receives Visual Scene Descriptors and Portable Avatars containing Avatar Models with Spatial Attitudes.
- Continuously:
- Receives Portable Avatars with Avatar Descriptors and Speech.
- Produces Visual and Audio Scene Descriptors.
- Renders the Audio-Visual Scene by spatially adding the Avatars’ Utterances to the Spatial Attitude of the respective Avatars’ Mouths. Rendering may be done from a Point of View, possibly different from the Position assigned to their Avatars in the Visual Scene, selected by participant who use a device of their choice (Head Mounted Display or 2D display/earpad) to experience the Audio-Visual Scene.
Each component of the Avatar-Based Videoconference Use Case is implemented as an AI Workflow (AIW) composed of AI Modules (AIMs). It includes the following elements:
| 1 | Functions of the AIW | The functions performed by the AIW implementing the Use Case. |
| 2 | Reference Model of the AIW | The Topology of AIMs in the AIW. |
| 3 | Input and Output Data of the AIW | Input and Output Data of the AIW. |
| 4 | Functions of the AIMs | Functions performed by the AIMs. |
| 5 | Input and Output Data of the AIW | Input and Output Data of the AIMs. |
| 6 | AIMs and JSON Metadata | Links to summary specification on the web of the AIMs and corresponding JSON Metadata [2]. |
Most MPAI Standards specify Use Cases that are implemented as AI Workflows. This page lists AI Workflows per Technical Specifications.
| Acronym | Names and Specifications of AI Workflows |
| PAF-CTX | Videoconference Client Transmitter |
| MMC-VMS | Virtual Meeting Secretary |
| PAF-AVS | Avatar Videoconference Server |
| PAF-CRX | Videoconference Client Receiver |