Technical Specification: Compression and Understanding of Industrial Data (MPAI-CUI) was one of the first projects launched in the early MPAI days and the standard was also among the standards approved in September 2021, just one year after the establishment of MPAI.
In December 2024, MPAI published a Call for Technologies for a new version of the standard strengthened with new functionalities. After a full year of intense work, the 63rd General Assembly approved Company Performance Prediction (CUI-CPP) V2.0 with a request for Community Comments. This article provides a summary of the new version.
CUI-CPP V2.0 specifies an AI Workflow based on Technical Specification: AI Framework (MPAI-AIF) V2.2, specifying the standard AI Framework (AIF) that enables initialisation, execution, dynamic configuration, and control of AI Workflows (AIW) composed of interconnected AI Modules (AIM).
The inputs to the CUI-CPP AI Workflow are:
- Prediction Horizon.
- Finance Descriptors.
- Governance Descriptors.
- Primary Risk Statements, for which an AI Model complying with relevant regulations is available.
- Secondary Risk Statements, for which only company-provided statements are available.
The outputs are:
- Organisation Descriptors, composed of organisation suitability score and the impacts of each Governance Descriptor on the score.
- Primary Default Descriptors, composed of Primary Default Probability and the impact of each Governance and Financial Descriptor on the probability.
- Primary Discontinuity Descriptors, composed of Primary Discontinuity Probability and the impact of each Primary Risk Descriptor on the probability.
- Secondary Discontinuity Probability, the probability that the company will be affected by a business discontinuity due to the Secondary Risks.
This is depicted in Figure 1.
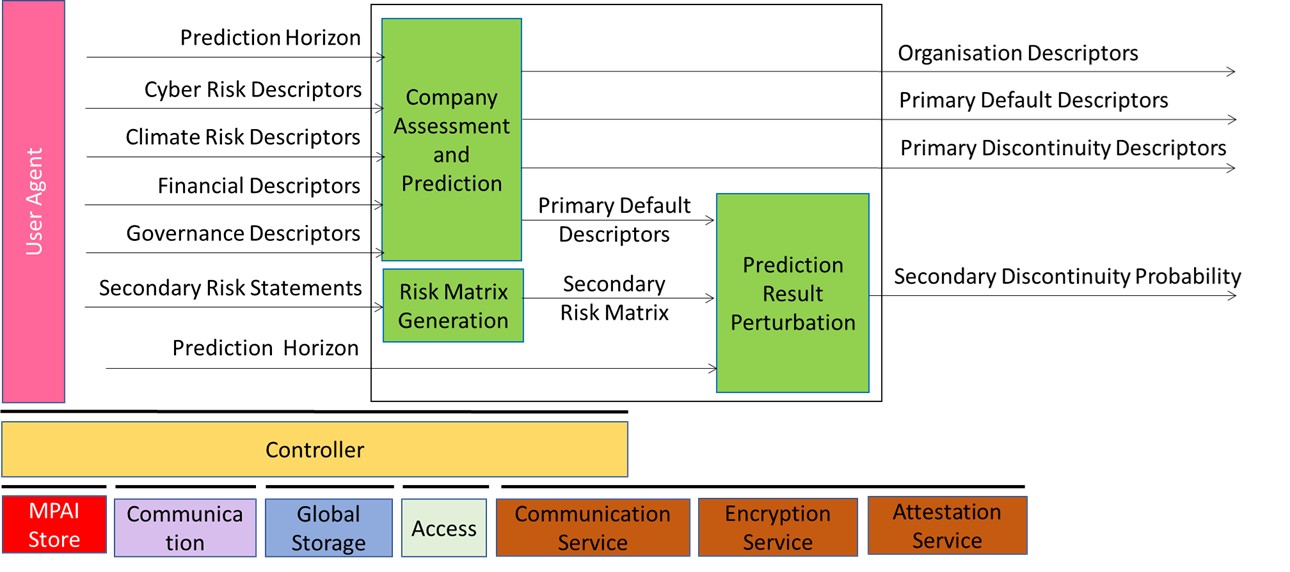
Figure 1 – The Reference Model of Company Performance Prediction (CUI-CPP) V2.0
CUI-CPP V2.0 is the first MPAI standard that has identified the need to signal whether Machine Learning Data – resulting from the application of training data to a process – is authorised, in a given jurisdiction, to process data and make it available to an AI Module (AIM).
The problem was addressed by developing a specification of “Machine Learning Object”, a data type composed of Machine Learning “Data” (e.g., a Neural Network) and a Machine Learning “Qualifier”, metadata providing information on the Machine Learning Model.
A Machine Learning Qualifier is composed of three elements:
- Sub-Type
- MLModel Type (which type of Machine Learning Model it is)
- NNModel Type (which type of Neural Network Model it is)
- Format
- Extension (e.g., Keras or Onnx)
- Framework (e.g., Caffe or PyTorch)
- Exchange (Onnx or NNEF)
- Attributes
- Manifest (specifying the type of input data that can be provided to the Machine Learning/Neural Network Model).
- Regulation (currently specifying the following: AI Act, CAIO, Data Act, Data Governance Act, EBSI, and GDPR).
- Certification Type (currently, ByLaw, SandBox).
- Validity (duration of certification validity).
Let’s now analyse the meaning of the input and output data types.
Financial Descriptors: Descriptors of the principal financial elements as specified by IFRS (International Finance Reporting Standards) provided according to the CUI-CPP format.
Governance Descriptors: A set of indexes/parameters provided according to the CUI-CPP format.
Primary Risk Descriptors: A set of risk descriptors, currently, Cyber Risk and Climate Risk Descriptors. A snippet of Cyber Risk Descriptors is:
| – AttackDetectionTime | Time the attack was started or detected. |
| – VectorProviderOrSource | Provider of input vector or external source. |
| – Type | IP address |
| – AttackSourceIPAddress | IP address of source of attack |
A snippet of Climate Risk Descriptors is:
| – Time | Time for the prediction |
| – Source | ID of prediction requester |
| – Type | GNSS Point |
| – Value of position | according to selected GNSS standard |
Secondary Risk Statements: Self-assessed Company Risks for which an AI Module is not available or may not be used. Each Secondary Risk is represented as a sequence of Level 2 Risk IDs that have the following elements – Impact, Probability, Severity, Retention – defined below:
| Impact | The anticipated extent of damage or disruption due to the Risk, described on a scale: None, Low, Medium, High. |
| Probability | The likelihood of the Risk occurring, described on a scale: None, Low, Medium, High. |
| Severity | The severity of consequences of the Risk occurring, described on a scale: None, Low, Medium, High. |
| Retention | The potential effect of the part of the Risk retained by the Company, i.e., the percentage not transferred to a third party, such as an insurance company. |
Organisation Descriptors: contain the most relevant elements of the Governance Descriptors affecting both the Primary Default Descriptors and the Primary Discontinuity Descriptors as:
- The impact of the set of Governance Descriptors on the Primary Default within the Prediction Horizon.
- A table including, for each row, the ID of the Governance Descriptor and its impact on the Primary Default, expressed as a percentage.
Primary Default Descriptors: produced by Primary Default Description AIM using the Financial Descriptors as:
- The Company Default Probability within the Prediction Horizon.
- A table including, for each row, the name of the Financial Descriptor and its importance to the Company Default, expressed as a percentage.
Primary Discontinuity Descriptors: produced by the Primary Discontinuity Description AIM using Primary Risk Statements, Financial Descriptors, and Governance Descriptors as:
- The Company Discontinuity Probability within the Prediction Horizon.
- A 3D tensor including the Descriptor category (Financial, Governance, and currently, Climate and Cyber) and, for each Descriptor category, the name of the Descriptors and their impact on the Company Discontinuity expressed as the percentage of the Company Discontinuity Probability.
- A 4D tensor having the following dimensions:
- Name of Primary Risk.
- The assessment of the Primary Risk between 0 and 1.
- For each Primary Risk, a 2D matrix including, for each row,
- The name of the Primary Risk Descriptor.
- A value between 0 and 1 representing the Descriptor impact on the Risk due to the Company Default, expressed as a percentage of the Risk value.
Secondary Risk Matrix: composed of as many rows as there are Secondary Risks with four columns for the characteristics: Occurrence, Impact, Severity, and Retention.