Clarifications of the Call for Use Cases and Functional Requirements
MPAI-5 has approved the MPAI-MMC Use Cases and Functional Requirements as attachment to the Call for Technologies N173. However, MMC-DC has identified some issues that are worth a clarification. This is posted on the MPAI web site and will be communicated to those who have informed the Secretariata of their intention to respond.
General issue
MPAI understands that the scope of both N151 and N153 is very broad. Therefore it reiterates the point made in N152 and N154 that:
Completeness of a proposal for a Use Case is a merit because reviewers can assess that the components are integrated. However, submissions will be judged for the merit of what is proposed. A submission on a single technology that is excellent may be considered instead of a submission that is complete but has a less performing technology.
Multimodal Question Answering (Use case #2 in N153)
MPAI welcomes submission that propose a standard set of “type of question intentions” and the means to indicate the language used in the Query Format.
MPAI welcomes proposals that propose a concept format for Reply in addition to or instead of a text format.
The assessment of submissions by Respondents who elect to not consider this point in their submission will not influence the assessment of the rest of their submission
References
- MPAI-MMC Use Cases & Functional Requirements; MPAI N153; https://mpai.community/standards/mpai-mmc/#UCFR
- MPAI-MMC Call for Technologies, MPAI N154; https://mpai.community/standards/mpai-mmc/#Technologies
- MPAI-MMC Framework Licence, N173; https://mpai.community/standards/mpai-mmc/#Licence
Use Cases and Functional Requirements
This document is also available in MS format MPAI-MMC Use Cases and Functional Requirements
2 The MPAI AI Framework (MPAI-AIF)
3.1 Conversation with emotion (CWE)
3.1.1 Multimodal Question Answering (MQA)
3.1.2 Personalised Automatic Speech Translation (PST)
4.2 Conversation with Emotion.
4.2.1 Implementation architecture.
4.2.3 I/O interfaces of AI Modules.
4.2.4 Technologies and Functional Requirements.
4.3 Multimodal Question Answering.
4.3.1 Implementation Architecture.
4.3.3 I/O interfaces of AI Modules.
4.3.4 Technologies and Functional Requirements.
4.4 Personalized Automatic Speech Translation.
4.4.1 Implementation Architecture.
4.4.3 I/O interfaces of AI Modules.
4.4.4 Technologies and Functional Requirements.
5 Potential common technologies.
1 Introduction
Moving Picture, Audio and Data Coding by Artificial Intelligence (MPAI) is an international association with the mission to develop AI-enabled data coding standards. Research has shown that data coding with AI-based technologies is more efficient than with existing technologies.
The MPAI approach to developing AI data coding standards is based on the definition of standard interfaces of AI Modules (AIM). AIMs operate on input data having a standard format to provide output data having a standard format. AIMs can be combined and executed in an MPAI-specified AI-Framework called MPAI-AIF. The MPAI-AIF standard is being developed based on the responses to the Call for MPAI-AIF Technologies (N100) [2] satisfying the MPAI-AIF Use Cases and Functional Requirements (N74) [1].
While AIMs must expose standard interfaces to be able to operate in an MPAI AI Framework, the technologies used to implement them may influence their performance. MPAI believes that competing developers striving to provide more performing proprietary and interoperable AIMs will promote horizontal markets of AI solutions that build on and further promote AI innovation.
This document is a collection of Use Cases and Functional Requirements for the MPAI Multimodal Conversation (MPAI-MMC) application area. The MPAI-MMC Use Cases enable human-machine conversation that emulates human-human conversation in completeness and intensity. Currently MPAI has identified three Use Cases falling in the Multimodal Communication area:
- Conversation with emotion (CWE)
- Multimodal Question Answering (MQA)
- Personalized Automatic Speech Translation (PST)
This document is to be read in conjunction with the document MPAI-MMC Call for Technologies (CfT) (N154) [4] as it provides the functional requirements of all the technologies that have been identified as required to implement the current MPAI-MMC Use Cases and Functional Requirements. Respondents to the MPAI-MMC CfT should make sure that their responses are aligned with the functional requirements expressed in this document.
In the future, MPAI may issue other Calls for Technologies falling in the scope of MPAI-MMC to support identified Use Cases.
It should also be noted that some technologies identified in this document are the same, similar, or related to technologies required to implement some of the Use Cases of the companion document MPAI-CAE Use Cases and Functional Requirements (N151) [3]. Readers of this document are advised that being familiar with the content of the said companion document is a prerequisite for a proper understanding of this document.
This document is structured in 7 chapters, including this Introduction.
| Chapter 2 | briefly introduces the AI Framework Reference Model and its six Components |
| Chapter 3 | briefly introduces the 3 Use Cases. |
| Chapter 4 | presents the 4 MPAI-MMC Use Cases with the following structure:
1. Reference architecture 2. AI Modules 3. I/O data of AI Modules 4. Technologies and Functional Requirements |
| Chapter 5 | identifies the technologies likely to be common across MPAI-MMC and MPAI-CAE, a companion standard project whose Call for Technologies is issued simultaneously with MPAI-MMC’s. |
| Chapter 6 | gives suggested references. |
| Chapter 7 | gives a basic list of relevant terms and their definition |
For the reader’s convenience, the meaning of the acronyms of this document is given in Table 1.
Table 1 – Acronyms of used in this document
| Acronym | Meaning |
| AI | Artificial Intelligence |
| AIF | AI Framework |
| AIM | AI Module |
| CfT | Call for Technologies |
| CWE | Conversation with emotion |
| DP | Data Processing |
| KB | Knowledge Base |
| ML | Machine Learning |
| MQA | Multimodal Question Answering |
| PST | Personalized Automatic Speech Translation |
2 The MPAI AI Framework (MPAI-AIF)
Most MPAI applications considered so far can be implemented as a set of AIMs – AI, ML and even traditional Data Processing (DP)-based units with standard interfaces assembled in suitable topologies to achieve the specific goal of an application and executed in an MPAI-defined AI Framework. MPAI is making all efforts to identify processing modules that are re-usable and upgradable without necessarily changing the inside logic. MPAI plans on completing the development of a 1st generation AI Framework called MPAI-AIF in July 2021.
The MPAI-AIF Architecture is given by Figure 1.
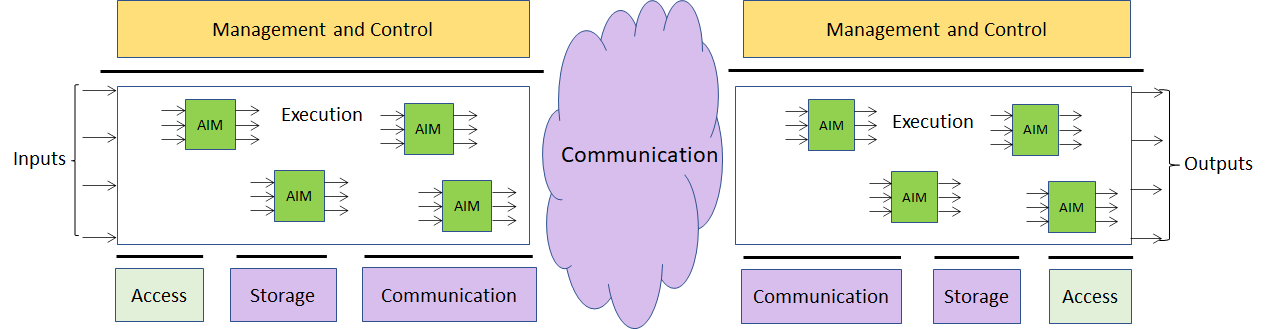
Figure 1 – The MPAI-AIF Architecture
MPAI-AIF is made up of 6 Components:
- Management and Control manages and controls the AIMs, so that they execute in the correct order and at the time when they are needed.
- Execution is the environment in which combinations of AIMs operate. It receives external inputs and produces the requested outputs, both of which are Use Case specific, activates the AIMs, exposes interfaces with Management and Control and interfaces with Communication, Storage and Access.
- AI Modules (AIM) are the basic processing elements receiving processing specific inputs and producing processing specific outputs.
- Communication is the basic infrastructure used to connect possibly remote Components and AIMs. It can be implemented, e.g., by means of a service bus.
- Storage encompasses traditional storage and is used to e.g., store the inputs and outputs of the individual AIMs, intermediary results data from the AIM states and data shared by AIMs.
- Access represents the access to static or slowly changing data that are required by the application such as domain knowledge data, data models, etc.
3 Use Cases
3.1 Conversation with emotion (CWE)
When people talk, they use multiple modalities. Emotion is one of the key features to understand the meaning of the utterances made by the speaker. Therefore, a conversation system with the capability to recognize emotion can better understand the user and produce a better reply.
This MPAI-MMC Use Case handles conversation with emotion. It is a human-machine conversation system where the computer can recognize emotion in the user’s speech and/or text, also using the video information of the face of the human to produce a reply.
Emotion is recognised in the following way and reflected in the speech production side. First, a set of emotion related cues are extracted from text, voice and video. Then, each recognition module for text, voice and video, recognises emotion independently. The emotion recognition module determines the final emotion based on each emotion. The emotion will be transferred to dialog processing module. Then the dialog processing module produces the reply based on the final emotion and meaning from the text and video analysis. Finally, the speech synthesis module produces the speech from the reply in text.
3.1.1 Multimodal Question Answering (MQA)
Question Answering Systems (QA) answer a user’s question presented in natural language. Current QA system only deals with the case where input is in “text” form or “speech” form. However, more attention is paid these days to the case where mixed inputs such as speech with an image are presented to the system. For example, a user asks a question: “Where can I buy this tool?” showing the picture of the tool. In that case, the QA system should process the question in a text along with the image and should find out the answer to the question.
Question and image are recognised and analysed in the following way and answers are produced in the output speech: The meaning of the question is recognised in the form of text or voice. Image is analysed to find the object name which is sent to the language understanding module. Then, the integrated meaning from the multimodal inputs is generated from the language understanding module. The Intention analysis module determines the intention of the question and the intention is sent to the QA module. The QA module produces the answer based on the intention of the question, and the meaning from the Language understanding module. The speech synthesis module produces the speech from the answer in text.
3.1.2 Personalised Automatic Speech Translation (PST)
Automatic speech translation technology denotes technology that recognizes a voice uttered in a language by a speaker, converts the recognized voice into another language through automatic translation, and outputs a converted voice as text-type subtitles or as a synthesized voice preserving the speaker’s features in the translated speech. Recently, as interest in voice synthesis among main technologies for automatic interpretation increases, research concentrates on personalized voice synthesis, a technology that outputs a target language through voice recognition and automatic translation, as a synthesis voice similar to a tone (or an utterance style) of a speaker.
The automatic interpretation system for generating a synthetic sound having characteristics similar to those of an original speaker’s voice includes a speech recognition to generate text data for an original speech signal of an original speaker and extract characteristic information such as pitch information, vocal intensity information, speech speed information, and vocal tract characteristic information of the original speech. Then the text data produced by the speech recognition module go through the automatic translation module to generate a synthesis-target translation and a speech synthesis module to generate a synthetic sound that resembles the original speaker using the extracted characteristic information.
4 Functional Requirements
4.1 Introduction
The Functional Requirements developed in this document refer to the individual technologies identified as necessary to implement Use Cases belonging to MPAI-MMC application areas using AIMs operating in an MPAI-AIF AI Framework. The Functional Requirements developed adhere to the following guidelines:
- AIMs are defined to allow implementations by multiple technologies (AI, ML, DP)
- DP-based AIMs need interfaces such as to a Knowledge Base. AI-based AIMs will typically require a learning process, however, support for this process is not included in the document. MPAI may develop further requirements covering that process in a future document.
- AIMs can be aggregated in larger AIMs. Some data flows of aggregated AIMs may not necessarily be exposed any longer.
- AIMs may be influenced by the companion MPAI-CAE Use Cases and Functional Requirements [3] as some technologies needed by some MPAI-MMC AIMs share a significant number of functional requirements.
- Current AIMs do not feed information back to AIMs upstream. Respondents to the MPAI-MMC Call for Technologies [5] are welcome to motivate such feed-back data flows and propose associated requirements.
The Functional Requirements described in the following sections are the result of a dedicated effort by MPAI experts over many meetings where different AIM partitionings have been proposed, discussed and revised. MPAI is aware that alternative partitioning or alternative I/O data to/from AIMs are possible, and those reading this document for the purpose of submitting a response to the MPAI-MMC Call for Technologies (N154) [5] are welcome to propose in their submissions alternative partitioning or alternative I/O data. However, they are required to justify the proposed new partitioning and to determine the functional requirements of the relevant technologies. The evaluation team will study the proposed alternative arrangement and may decide to accept all or part of the proposed new arrangement.
4.2 Conversation with Emotion
4.2.1 Implementation architecture
Possible architectures of this Use Case are given by Figure 2 and Figure 3. The two figures differ in the use of legacy DP technology vs AI technology:
- In Figure 2 some AIMs need a Knowledge Base to perform their tasks.
- In Figure 3 Knowledge Bases may not be required as the relevant information is embedded in neural network that are part of an AIM.
Intermediate arrangements with only some Knowledge Bases are also possible, but not represented in a figure.
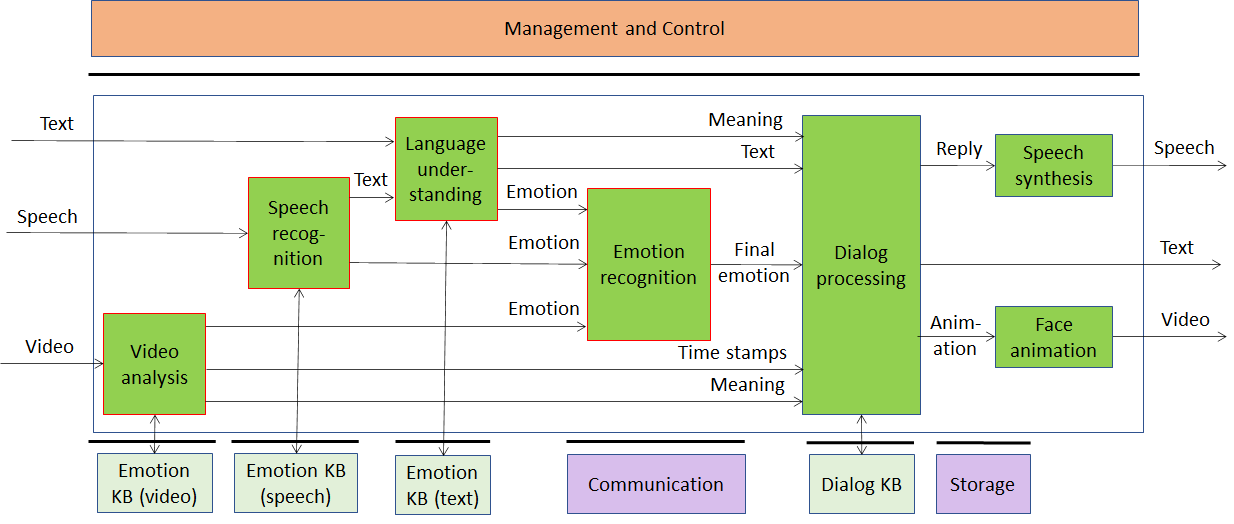
Figure 2 – Conversation with emotion (using legacy DP technologies)
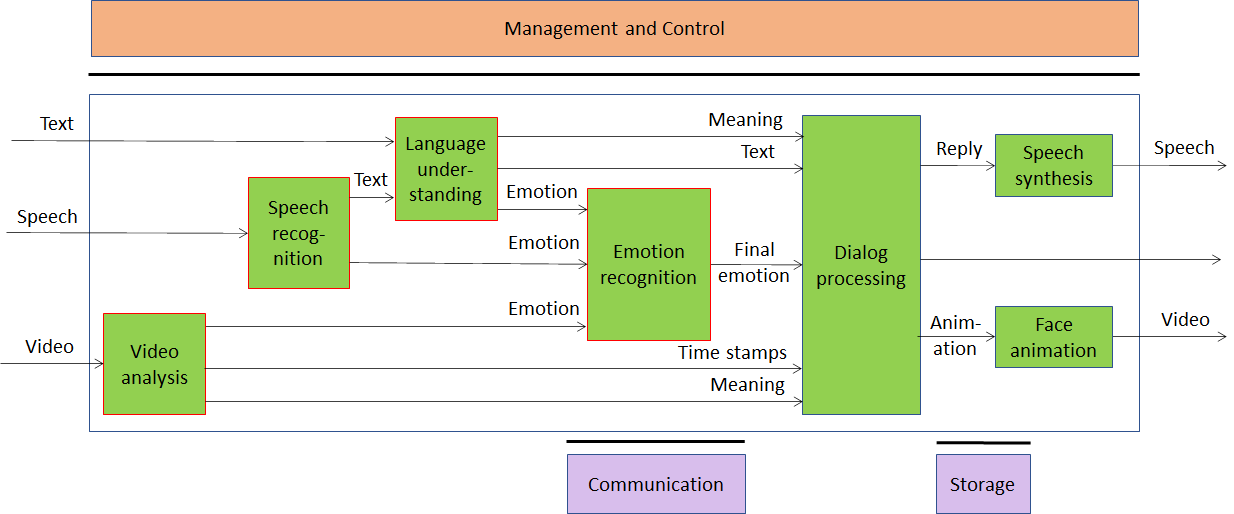
Figure 3 – Conversation with emotion (fully AI-based)
4.2.2 AI Modules
The AI Modules of Conversation with Emotion are given in Table 2
Table 2 – AI Modules of Conversation with Emotion
| AIM | Function |
| Language understanding | Analyses natural language in a text format to produce its meaning and emotion included in the text |
| Speech Recognition | Analyses the voice input and generates text output and emotion carried by it |
| Video analysis | Analyses the video and recognises the emotion it carries |
| Emotion recognition | Determines the final emotion from multi-source emotions |
| Dialog processing | Analyses user’s Meaning and produces Reply based on the meaning and emotion implied by the user’s text |
| Speech synthesis | Produces speech from Reply (the input text) |
| Face animation | Produces an animated face consistent with the machine-generated Reply |
| Emotion KB (text) | Contains words/phrases with associate emotion. Language understanding queries Emotion KB (text) to obtain the emotion associated with a text |
| Emotion KB (speech) | Contains features extracted from speech recordings of different speakers reading/reciting the same corpus of texts with an agreed set of emotions and without emotion, for a set of languages and for different genders.
Speech recognition queries Emotion KB (speech) to obtain emotions corresponding to the features provided as input. |
| Emotion KB (video) | Contains features extracted from video recordings of different people speaking with an agreed set of emotions and without emotion for different genders.
Video analysis queries Emotion KB (video) to obtain emotions corresponding to the features provided as input. |
| Dialog KB | Contains sentences with associated dialogue acts. Dialog processing queries Dialog KB to obtain dialogue acts with associated sentences. |
4.2.3 I/O interfaces of AI Modules
The I/O data of AIMs used in Conversation with Emotion are given in Table 3.
Table 3 – I/O data of Conversation with Emotion AIMs
| AIM | Input Data | Output Data |
| Video analysis | Video | Emotion
Meaning Time stamp |
| Speech recognition | Input Speech
Response from Emotion KB (Speech) |
Text
Emotion Query to Emotion KB (Speech) |
| Language understanding | Input Text
Recognised Text Response from Emotion KB (Text) |
Text
Emotion Meaning Query to Emotion KB (Text) |
| Emotion recognition | Emotion (from text)
Emotion (from speech) Emotion (from image) |
Final Emotion |
| Dialog processing | Text
Meaning Final emotion Meaning Response from Dialogue KB |
Reply
Text Animation
Query to Dialogue KB |
| Speech synthesis | Reply | Speech |
| Face animation | Animation parameters | Video |
| Emotion KB (text) | Query | Response |
| Emotion KB (speech) | Query | Response |
| Emotion KB (video) | Query | Response |
| Dialog KB | Query | Response |
4.2.4 Technologies and Functional Requirements
4.2.4.1 Text
Text should be encoded according to ISO/IEC 10646, Information technology – Universal Coded Character Set (UCS) to support most languages in use [6].
To Respondents
Respondents are invited to comment on this choice.
4.2.4.2 Digital Speech
Speech is sampled at a frequency between 8 kHz and 96 kHz and digitally represented between 16 bits/sample and 24 bits/sample (both linear).
To Respondents
Respondents are invited to comment on these two choices.
4.2.4.3 Digital Video
Digital video has the following features.
- Pixel shape: square
- Bit depth: 8-10 bits/pixel
- Aspect ratio: 4/3 and 16/9
- 640 < # of horizontal pixels < 1920
- 480 < # of vertical pixels < 1080
- Frame frequency 50-120 Hz
- Scanning: progressive
- Colorimetry: ITU-R BT709 and BT2020
- Colour format: RGB and YUV
- Compression: uncompressed, if compressed AVC, HEVC
To Respondents
Respondents are invited to comment on these choices.
4.2.4.4 Emotion
By Emotion we mean an attribute that indicates an emotion out of a finite set of Emotions.
Emotion is extracted and digitally represented as Emotion from text, speech and video.
The most basic emotions are described by the set: “anger, disgust, fear, happiness, sadness, and surprise” [6], or “joy versus sadness, anger versus fear, trust versus disgust, and surprise versus anticipation” [8]. One of these sets can be taken as “universal” in the sense that they are common across all cultures. An Emotion may have different Grades [9,10].
To Respondents
Respondents are invited to propose:
- A minimal set of Emotions whose semantics are shared across cultures.
- A set of Grades that can be associated to Emotions.
- A digital representation of Emotions and their Grades [11].
This CfT does not specifically address culture-specific Emotions. However, the proposed digital representation of Emotions and their grades should either be capable to accommodate or be extensible to support culture-specific Emotions.
4.2.4.5 Emotion KB (speech) query format
Emotion KB (speech) contains features extracted from speech recordings of different speakers reading/reciting the same corpus of texts with an agreed set of emotions and without emotion, for a set of languages and for different genders.
The Emotion KB (speech) is queried with a list of speech features. The Emotion KB responds with the emotions of the speech.
Speech features are extracted from the input speech and are used to determine the Emotion of the input speech.
Examples of features that have information about emotion are:
- Features to detect the arousal level of emotions: sequences of short-time prosody acoustic features (features estimated on a frame basis), e.g., short-term speech energy [15].
- Features related to the pitch signal (i.e., the glottal waveform) that depends on the tension of the vocal folds and the subglottal air pressure. Two parameters related to the pitch signal can be considered: pitch frequency and glottal air velocity. E.g., high velocity indicates a speech emotion like happiness. Low velocity is in harsher styles such as anger [17].
- The shape of the vocal tract is modified by the emotional states. The formants (characterized by a center frequency and a bandwidth) could be a representation of the vocal tract resonances. Features related to the number of harmonics due to the non-linear airflow in the vocal tract. E.g., in the emotional state of anger, the fast air flow causes additional excitation signals other than the pitch. Teager Energy Operator-based (TEO) features could be an example of measure of the harmonics and cross-harmonics in the spectrum [18].
An example solution of the features could be the Mel-frequency cepstrum (MFC) [19].
To Respondents
Respondents are requested to propose an Emotion KB (speech) query format that satisfies the following requirements:
- Capable of querying by specific speech features
- Speech features should be:
- Suitable for extraction of Emotion information from natural speech containing emotion:
- Extensible, i.e., capable to include additional speech features.
When assessing proposed Speech features, MPAI may resort to objective testing.
Note: An AI-based implementation may not need Emotion KB (Speech).
4.2.4.6 Emotion KB (text) query format
Emotion KB (text) contains text features extracted from a text corpus with an agreed set of Emotions, for a set of languages and for different genders.
The Emotion KB (text) is queried with a list of Text features. Text features considered are:
- grammatical features, e.g., parts of speech.
- named entities, places, people, organisations.
- semantic features, e.g., roles, such as agent [21].
The Emotion KB (text) responds by giving Emotions correlated with the text features provided as input.
To Respondents
Respondents are requested to propose an Emotion KB (text) query format that satisfies the following requirements:
- Capable of querying by specific Text features.
- Text features should be:
- Suitable for extraction of Emotion information from natural language text containing Emotion.
- Extensible, i.e., capable to include additional text features.
When assessing the proposed Text features, MPAI may resort to objective testing.
Note: An AI-based implementation may not need Emotion KB (Text).
4.2.4.7 Emotion KB (video) query format
Emotion KB (video) contains features extracted from the video recordings of different speakers reading/reciting the same corpus of texts with and without an agreed set of emotions and meanings, for different genders.
Emotion KB (video) is queried with a list of Video features. Emotion KB responds with the associated Emotion, its Grade, and Meaning.
To Respondents
Respondents are requested to propose an Emotion KB (video) query format that satisfies the following requirements:
- Capable of querying by specific Video features.
- Video features should be:
- Suitable for extraction of emotion information from a video containing the face of a human expressing emotion.
- Extensible, i.e., capable of including additional Video features.
When assessing proposed Video features, MPAI may resort to objective testing.
Note: An AI-based implementation may not need Emotion KB (video).
4.2.4.8 Meaning
Meaning is information extracted from input text, speech and video such as question, statement, exclamation, expression of doubt, request, invitation [18].
To Respondents
Respondents are requested to propose an extensible list of meanings and their digital representations satisfying the following requirements:
- The meaning extracted from the input text shall have a structure that includes grammatical information and semantic information.
- The digital representation of meaning shall allow for the addition of new features to be used in different applications.
4.2.4.9 Dialog KB query format
Dialog KB contains sentence features with associated dialogue acts. Dialog processing AIM queries Dialog KB to obtain dialogue acts with associated sentence features.
The Dialog KB is queried with sentence features. The sentence features considered are:
- Sentences analysed by the language understanding AIM.
- Sentence structures.
- Sentences with semantic features for the words composing sentences, e.g., roles, such as agent [21].
The Dialog KB responds by giving dialog acts correlated with the sentence provided as input.
To Respondents
Respondents are requested to propose a Dialog KB query format that satisfies the following requirements:
- Capable of querying by specific sentence features.
- Sentence features should be:
- Suitable for extraction of sentence structures and meaning.
- Extensible, i.e., capable to include additional sentence features.
When assessing the proposed Sentence features, MPAI may resort to objective testing.
Note: An AI-based implementation may not need Dialog KB.
4.2.4.10 Input to speech synthesis (Reply)
Respondents should propose suitable technology for driving the speech synthesiser. Note that “Text with emotion” and “Concept with emotion” are both candidates for consideration.
To Respondents
Text with emotion
A standard format for text with Emotions attached to different portions of the text. An example of how emotion in the text could be added to text is offered by emoticons.
Text should be encoded according to ISO/IEC 10646, Information technology – Universal Coded Character Set (UCS) to support most languages in use.
Respondents are requested to comment on the choice of the character set and to propose a solution for emotion added to a text satisfying the following requirements:
- It should include a scheme for annotating text with emotion either as text with emotion expressed with text or with additional characters.
- It should include an extensible emotion annotation representation scheme for basic emotions.
- The emotion annotation representation scheme should be language independent.
Concept with emotion
Respondents are requested to propose digital representation of concept that enables to go straight from meaning and emotion to “concept to speech synthesiser”, as, e.g., in [28].
4.2.4.11 Input to face animation
A face can be animated using the same parameters used to synthesise speech.
To respondents
Respondents are requested to provide the same types of data format as for speech of to propose and justify a different data format.
4.3 Multimodal Question Answering
4.3.1 Implementation Architecture
Possible architectures of this Use Case are given by Figure 4 and Figure 5. In the former case some AIMs need a Knowledge Base to perform their tasks. In the latter case Knowledge Bases may not be required as the relevant information is embedded in neural networks that are part of an AIM. Intermediate arrangements where only some Knowledge Bases are used, are also possible but not represented by a figure.
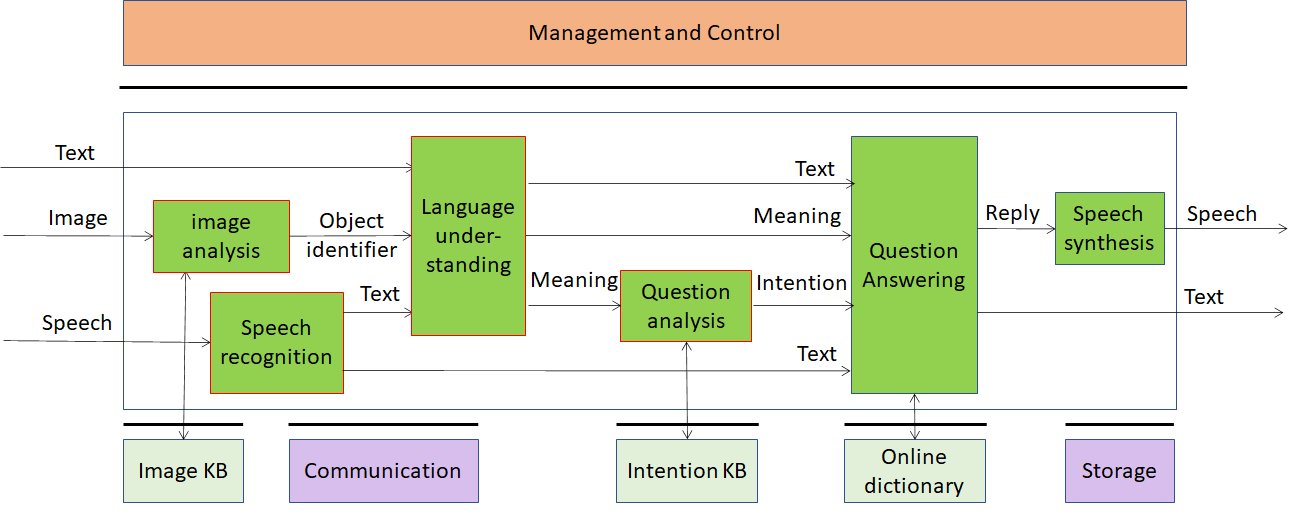
Figure 4 – Multimodal Question Answering (using legacy DP technologies)
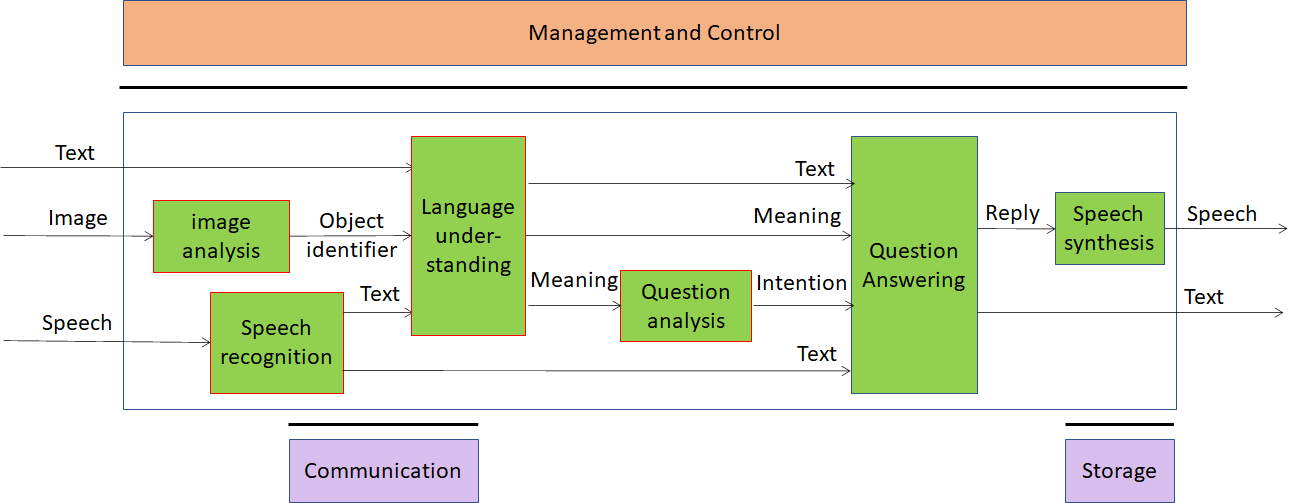
Figure 5 – Multimodal Question Answering (fully AI-based)
4.3.2 AI Modules
The AI Modules of Multimodal Question Answering are given in Table 4.
Table 4 – AI Modules of Multimodal Question Answering
| AIM | Function |
| Language understanding | Analyses natural language expressed as text using a language model to produce the meaning of the text |
| Speech Recognition | Analyse the voice input and generate text output |
| Speech synthesis | Converts input text to speech |
| Image analysis | Analyses image and produces the object name in focus |
| Question analysis | Analyses the meaning of the sentence and determines the Intention |
| Question Answering | Analyses user’s question and produces a reply based on user’s Intention |
| Intention KB | Responds to queries using a question ontology to provide the features of the question |
| Image KB | Responds to Image analysis’s queries providing the object name in the image |
| Online dictionary | Allows Question Answering AIM to find answers to the question |
4.3.3 I/O interfaces of AI Modules
The AI Modules of Multimodal Question Answering are given in Table 5.
Table 5 – I/O data of Multimodal Question Answering AIMs
| AIM | Input Data | Output Data |
| Speech Recognition | Digital Speech | Text |
| Image analysis | Image
Image KB response |
Image KB query
Text |
| Language understanding | Text
Text |
Meaning
Meaning |
| Question analysis | Meaning
Intention KB response |
Intention
Intention KB query |
| QA | Meaning
Text Intention Online dictionary query |
Text
Online dictionary response |
| Speech synthesis | Text | Digital speech |
| Intention KB | Query | Response |
| Image KB | Query | Response |
| Online dictionary | Query | Response |
| Dialog KB | Query | Response |
4.3.4 Technologies and Functional Requirements
4.3.4.1 Text
Text should be encoded according to ISO/IEC 10646, Information technology – Universal Coded Character Set (UCS) to support most languages in use [6].
To Respondents
Respondents are invited to comment on this choice.
4.3.4.2 Digital Speech
Multimodal QA (MQA) requires that speech be sampled at a frequency between 8 kHz and 96 kHz and digitally represented between 16 bits/sample and 24 bit/sample (linear).
To Respondents
Respondents are invited to comment on these two choices.
4.3.4.3 Digital Image
A Digital image is an uncompressed or a JPEG compressed picture [19].
To Respondents
Respondents are invited to comment on this choice.
4.3.4.4 Image KB query format
Image KB contains feature vectors extracted from different images of those objects intended to be used in this Use Case [29].
The Image KB is queried with a vector of image features extracted from the input image representing an object [21]. The Image KB responds by giving the identifier of the object.
To Respondents
Respondents are requested to propose an Image KB query format that satisfies the following requirements:
- Capable of querying by specific Image features.
- Image features should be:
- Suitable for querying the Image KB.
- Extensible to include additional image features and additional object types.
When assessing proposed Image features, MPAI may resort to objective testing.
An AI-Based implementation may not need Image KB.
4.3.4.5 Object identifier
The object must be uniquely identified.
To Respondents
Respondents are requested to propose a universally applicable object classification scheme.
4.3.4.6 Meaning
Meaning is information extracted from the input text such as question, statement, exclamation, expression of doubt, request, invitation [18].
To Respondents
Respondents are requested to propose an extensible list of meanings and their digital representations satisfying the following requirements:
- The meaning extracted from the input text shall have a structure that includes grammatical information and semantic information.
- The digital representation of meaning shall allow for the addition of new features to be used in different applications.
4.3.4.7 Intention KB query format
Intention KB contains question patterns extracted from the user questions that denote those intention types. It is the result of the question analysis.
For instance, what, where, from where, for whom, by whom, how… [22].
The Intention KB is queried by giving text as input. Intention KB responds with the type of question intention.
To Respondents
Respondents are requested to propose an Intention KB query format satisfying the following requirements:
- Capable of querying by questions with meaning provided by the Language Understanding AIM.
- Extensible, i.e., capable to include additional intention features.
Respondents are requested to propose an extensible classification of Intentions and their digital representations satisfying the following requirements:
- The intention of the question shall be represented as including question types, question focus and question topics.
- The digital representation of intention shall be extensible, i.e., allow for the addition of new features to be used in different applications.
An AI-Based implementation may not need Intention KB.
4.3.4.8 Online dictionary query format
Online dictionary contains structured data that include topics and related information in the form of summaries, table of contents and natural language text [23].
The Online dictionary is queried by giving text as input. The Online dictionary responds with paragraphs where to find answers that have high correlation with the user question.
To Respondents
Respondents are requested to propose an Online dictionary KB query format satisfying the following requirements:
- Capable of querying by text as keywords.
- Extensible, i.e., capable to include additional text features.
4.4 Personalized Automatic Speech Translation
4.4.1 Implementation Architecture
The AI Modules of a personalized automatic speech translator are configured as in Figure 6.
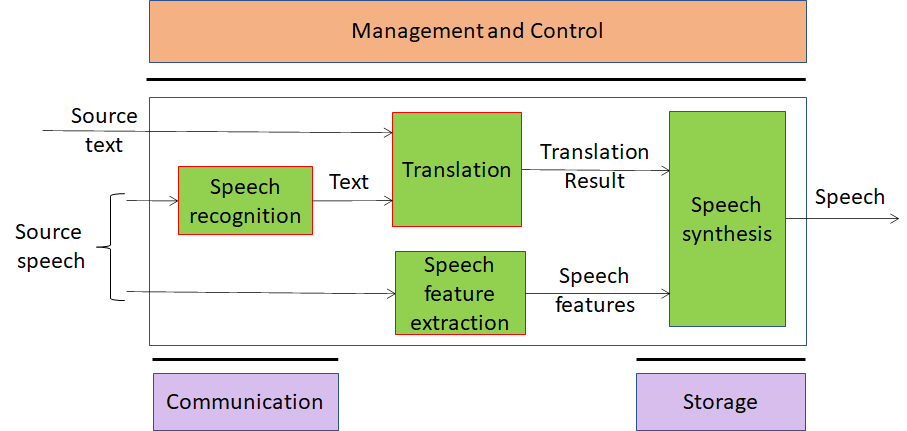
Figure 6 – Personalized Automatic Speech Translation
4.4.2 AI Modules
The AI Modules of Personalized Automatic Speech Translation are given in Table 6.
Table 6 – AI Modules of Personalized Automatic Speech Translation
| AIM | Function |
| Speech Recognition | Converts Speech into Text |
| Translation | Translates the user text input in source language to the target language |
| Speech feature extraction | Extracts Speech features such as tones, intonation, intensity, pitch, emotion, intensity or speed from the input voice specific of the speaker. |
| Speech synthesis | Produces Speech from the text resulting from translation with the speech features extracted from the speaker of the source language |
4.4.3 I/O interfaces of AI Modules
The AI Modules of Personalized Automatic Speech Translation are given in Table 7.
Table 7 – I/O data of Personalized Automatic Speech Translation AIMs
| AIM | Input Data | Output Data |
| Speech Recognition | Digital Speech | Text |
| Translation | Text
Speech |
Translation result |
| Speech feature extraction | Digital speech | Speech features |
| Speech synthesis | Translation result
Speech features |
Digital speech |
4.4.4 Technologies and Functional Requirements
4.4.4.1 Text
Text should be encoded according to ISO/IEC 10646, Information technology – Universal Coded Character Set (UCS) to support most languages in use [6].
To Respondents
Respondents are invited to comment on this choice.
4.4.4.2 Digital Speech
Speech should be sampled at a frequency between 8 kHz and 96 kHz and digitally represented between 16 bits/sample and 24 bit/sample (both linear).
To Respondents
Respondents are invited to comment on these two choices.
4.4.4.3 Speech features
Speech features such as tones, intonation, intensity, pitch, emotion or speed are used to encode speech features of the speaker.
The following features should be included in the speech features to describe the speaker’s voice: pitch, prosodic structures per intonation phrase, vocal intensity, speed of the utterance per word/sentence/intonation phrase, vocal tract characteristics of the speaker of the source language, and additional speech features associated with hidden variables. The vocal tract characteristics can be expressed as characteristic parameters of Mel-frequency cepstral coefficient (MFCC) and glottal wave.
To Respondents
Respondents are requested to propose a set of speech features that shall be suitable for
- Extracting voice characteristic information from natural speech containing personal features.
- Producing synthesized speech reflecting the original user’s voice characteristics.
When assessing proposed Speech features, MPAI may resort to subjective/objective testing.
4.4.4.4 Language identification
ISO 639 – Codes for the Representation of Names of Languages — Part 1: Alpha-2 Code.
To Respondents
Respondents are requested to comment on this choice.
4.4.4.5 Translation results
Respondents should propose suitable technology for driving the speech synthesiser. “Text to speech” and “concept to speech” are both considered.
To Respondents
Text to speech
Text should be encoded according to ISO/IEC 10646, Information technology – Universal Coded Character Set (UCS) to support most languages in use.
Respondents are requested to comment on the choice of character set.
Concept to speech
Respondents are requested to propose digital representation of concept that enables to go straight from translation result to “concept to speech synthesiser”, as, e.g., in [28].
5 Potential common technologies
Table 8 introduces the MPAI-CAE and MPAI-MMC acronyms.
Table 8 – Acronyms of MPAI-CAE and MPAI-MMC Use Cases
| Acronym | App. Area | Use Case |
| EES | MPAI-CAE | Emotion-Enhanced Speech |
| ARP | MPAI-CAE | Audio Recording Preservation |
| EAE | MPAI-CAE | Enhanced Audioconference Experience |
| AOG | MPAI-CAE | Audio-on-the-go |
| CWE | MPAI-MMC | Conversation with emotion |
| MQA | MPAI-MMC | Multimodal Question Answering |
| PST | MPAI-MMC | Personalized Automatic Speech Translation |
Table 9 gives all MPAI-CAE and MPAI-MMC technologies in alphabetical order.
Please note the following acronyms
| KB | Knowledge Base |
| QF | Query Format |
Table 9 – Alphabetically ordered MPAI-CAE and MPAI-MMC technologies
| Notes | UC=Use case |
| UCFR=Use Cases and Functional Requirements document number | |
| Section=Section of the above document | |
| Technology=name of technology |
| UC | UCFR | Section | Technology |
| EAE | N151 | 4.4.4.4 | Delivery |
| AOG | N151 | 4.5.4.7 | Delivery |
| CWE | N153 | 4.2.4.9 | Dialog KB query format |
| ARP | N151 | 4.3.4.1 | Digital Audio |
| AOG | N151 | 4.5.4.1 | Digital Audio |
| ARP | N151 | 4.3.4.3 | Digital Image |
| MQA | N153 | 4.3.4.3 | Digital Image |
| EES | N151 | 4.2.4.1 | Digital Speech |
| EAE | N151 | 4.4.4.1 | Digital Speech |
| CWE | N153 | 4.2.4.2 | Digital Speech |
| MQA | N153 | 4.3.4.2 | Digital Speech |
| PST | N153 | 4.4.4.2 | Digital Speech |
| ARP | N151 | 4.3.4.2 | Digital Video |
| CWE | N153 | 4.2.4.3 | Digital Video |
| EES | N151 | 4.2.4.2 | Emotion |
| CWE | N153 | 4.2.4.4 | Emotion |
| EES | N151 | 4.2.4.4 | Emotion descriptors |
| CWE | N153 | 4.2.4.5 | Emotion KB (speech) query format |
| CWE | N153 | 4.2.4.6 | Emotion KB (text) query format |
| CWE | N153 | 4.2.4.7 | Emotion KB (video) query format |
| EES | N151 | 4.2.4.3 | Emotion KB query format |
| MQA | N153 | 4.3.4.4 | Image KB query format |
| CWE | N153 | 4.2.4.11 | Input to face animation |
| CWE | N153 | 4.2.4.10 | Input to speech synthesis |
| MQA | N153 | 4.3.4.7 | Intention KB query format |
| PST | N153 | 4.4.4.4 | Language identification |
| CWE | N153 | 4.2.4.8 | Meaning |
| MQA | N153 | 4.3.4.6 | Meaning |
| EAE | N151 | 4.4.4.2 | Microphone geometry information |
| AOG | N151 | 4.5.4.2 | Microphone geometry information |
| MQA | N153 | 4.3.4.5 | Object identifier |
| MQA | N153 | 4.3.4.8 | Online dictionary query format |
| EAE | N151 | 4.4.4.3 | Output device acoustic model metadata KB query format |
| ARP | N151 | 4.3.4.6 | Packager |
| AOG | N151 | 4.5.4.3 | Sound array |
| AOG | N151 | 4.5.4.4 | Sound categorisation KB query format |
| AOG | N151 | 4.5.4.5 | Sounds categorisation |
| PST | N153 | 4.4.4.3 | Speech features |
| ARP | N151 | 4.3.4.4 | Tape irregularity KB query format |
| ARP | N151 | 4.3.4.5 | Text |
| CWE | N153 | 4.2.4.1 | Text |
| MQA | N153 | 4.3.4.1 | Text |
| PST | N153 | 4.4.4.1 | Text |
| PST | 4.4.4.5 | Translation results | |
| AOG | N151 | 4.5.4.6 | User Hearing Profiles KB query format |
The following technologies are shared or shareable across Use Cases:
- Delivery
- Digital speech
- Digital audio
- Digital image
- Digital video
- Emotion
- Meaning
- Microphone geometry information
- Text
Image features apply to different visual objects in MPAI-CAE and MPAI-MMC.
The Speech features in Use Cases of both standards are different. However, respondents may consider the possibility of proposing a unified set of Speech features, e.g., as proposed in [30].
6 Terminology
Table 10 – MPAI-MMC terms
| Term | Definition |
| Access | Static or slowly changing data that are required by an application such as domain knowledge data, data models, etc. |
| AI Framework (AIF) | The environment where AIM-based workflows are executed |
| AI Module (AIM) | The basic processing elements receiving processing specific inputs and producing processing specific outputs |
| Communication | The infrastructure that connects the Components of an AIF |
| Dialog processing | An AIM that produces a reply based on the input speech/text |
| Digital Speech | Digitised speech as specified by MPAI |
| Emotion | An attribute that indicates an emotion out of a finite set of Emotions |
| Emotion Grade | The intensity of an Emotion |
| Emotion Recognition | An AIM that decides the final Emotion out of Emotions from different sources |
| Emotion KB (text) | A dataset of Text features with corresponding emotion |
| Emotion KB (speech) | A dataset of Speech features with corresponding emotion |
| Emotion KB (Video) | A dataset of Video features with corresponding emotion |
| Emotion KB query format | The format used to interrogate a KB to find relevant emotion |
| Execution | The environment in which AIM workflows are executed. It receives external inputs and produces the requested outputs both of which are application specific |
| Image analysis | An AIM that extracts Image features |
| Image KB | A dataset of Image features with corresponding emotion |
| Intention | Intention is the result of a question analysis that denotes information on the input question |
| Intention KB | A question classification providing the features of a question |
| Language Understanding | An AIM that analyses natural language as Text to produce its meaning and emotion included in the text |
| Management and Control | Manages and controls the AIMs in the AIF, so that they execute in the correct order and at the time when they are needed |
| Meaning | Information extracted from the input text such as syntactic and semantic information |
| Online Dictionary | A dataset that includes topics and related information in the form of summaries, table of contents and natural language text |
| Question Analysis | An AIM that analyses the meaning of a question sentence and determines its Intention |
| Question Answering | An AIM that analyses the user’s question and produces a reply based on the user’s Intention |
| Speech features | Features used to extract Emotion from Digital Speech |
| Speech feature extraction | An AIM that extracts Speech features from Digital speech |
| Speech Recognition | An AIM that converts Digital speech to Text |
| Speech Synthesis | An AIM that converts Text or concept to Digital speech |
| Storage | Storage used to, e.g., store the inputs and outputs of the individual AIMs, data from the AIM’s state and intermediary results, shared data among AIMs |
| Text | A collection of characters drawn from a finite alphabet |
| Translation | An AIM that converts Text in a source language to Text in a target language |
7 References
- MPAI-AIF Use Cases and Functional Requirements, N74; https://mpai.community/standards/mpai-aif/#Requirements
- MPAI-AIF Call for Technologies, N100; https://mpai.community/standards/mpai-aif/#Technologies
- MPAI-CAE Use Cases and Functional Requirements, N151; https://mpai.community/standards/mpai-cae/#Requirements
- MPAI-CAE Call for Technologies, N152; https://mpai.community/standards/mpai-cae/#Technologies
- MPAI-MMC Call for Technologies, N154; https://mpai.community/standards/mpai-mmc/#Technologies
- ISO/IEC 10646:2003 Information Technology — Universal Multiple-Octet Coded Character Set (UCS)
- Ekman, P. (1999). Basic Emotions. In T. Dalgleish and T. Power (Eds.) The Handbook of Cognition and Emotion pp. 45–60. Sussex, U.K.: John Wiley & Sons, Ltd.
- Plutchik R., Emotion: a psychoevolutionary synthesis, New York Harper and Row, 1980
- Russell, James (1980). “A circumplex model of affect”. Journal of Personality and Social Psychology. 39 (6): 1161–1178. doi:10.1037/h0077714
- Cahn, J. E., The Generation of Affect in Synthesized Speech, Journal of the American Voice I/O Society, 8, July 1990, p. 1-19
- https://www.w3.org/TR/2014/REC-emotionml-20140522/
- Burkhardt, F., & Sendlmeier, W. F., Verification of Acoustical Correlates of Emotional Speech using Formant-Synthesis, ISCA Workshop on Speech & Emotion, Northern Ireland 2000, p. 151-156.
- Scherer, K. R., Ladd, D. R., & Silverman, K., Vocal cues to speaker affect: Testing two models, Journal of the Acoustic Society of America, 76(5), 1984, p. 1346-1356
- Kasuya, H., Maekawa, K., & Kiritani, S., Joint Estimation of Voice Source and Vocal Tract Parameters as Applied to the Study of Voice Source Dynamics, ICPhS 99, p. 2505-2512
- Mozziconacci, S. J. L., Speech Variability and Emotion: Production and Perception, PhD Thesis, Technical University Eindhoven, 1998
- Burkhardt, F., & Sendlmeier, W. F., Verification of Acoustical Correlates of Emotional Speech using Formant-Synthesis, ISCA Workshop on Speech & Emotion, Northern Ireland 2000, p. 151-156.
- Cahn, J. E., The Generation of Affect in Synthesized Speech, Journal of the American Voice I/O Society, 8, July 1990, p. 1-19
- Hamed Beyramienanlou, Nasser Lotfivand, “An Efficient Teager Energy Operator-Based Automated QRS Complex Detection”, Journal of Healthcare Engineering, vol. 2018, Article ID 8360475, 11 pages, 2018. https://doi.org/10.1155/2018/8360475]
- Davis S B. Comparison of parametric representations for monosyllabic word recognition in continuously spoken sentences. IEEE Trans. Acoust. Speech Signal Process. 1980, 28(4):65-74
- Proceedings of the Ninth International Conference on Language Resources and Evaluation (LREC’14), Reykjavik, Iceland, pp. 3501–3504, May 2014. 2- Moataz El Ayadi, Mohamed S. Kamel, Fakhri Karray. Survey on speech emotion recognition: Features, classification schemes, and databases. Pattern Recognition Journal, Elsevier, 44 (2011) 572–587
- Mohamed Zakaria Kurdi (2017). Natural Language Processing and Computational Linguistics: semantics, discourse, and applications, Volume 2. ISTE-Wiley.
- Semaan, P. (2012). Natural Language Generation: An Overview. Journal of Computer Science & Research (JCSCR)-ISSN, 50-57
- Hudson, Graham; Léger, Alain; Niss, Birger; Sebestyén, István; Vaaben, Jørgen (31 August 2018). “JPEG-1 standard 25 years: past, present, and future reasons for a success”. Journal of Electronic Imaging. 27 (4)
- Hobbs, Jerry R.; Walker, Donald E.; Amsler, Robert A. (1982). “Natural language access to structured text”. Proceedings of the 9th conference on Computational linguistics. 1. pp. 127–32.
- MMP Petrou, C Petrou, Image processing: the fundamentals – 2010, Wiley
- Suman Kalyan Maity, Aman Kharb, Animesh Mukherjee, Language Use Matters: Analysis of the Linguistic Structure of Question Texts Can Characterize Answerability in Quora, ICWSM 2017
- Xanh Ho, Anh-Khoa Duong Nguyen, Saku Sugawara, Akiko Aizawa, Constructing A Multi-hop QA Dataset for Comprehensive Evaluation of Reasoning Steps, COLING 2020
- https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.433.7322&rep=rep1&type=pdf
- Mohamed Elgendy, Deep Learning for Vision Systems, Manning Publication, 2020
- Problem Agnostic Speech Encoder; https://github.com/santi-pdp/pase