(Tentative)
| Function | Reference Model | Input/Output Data |
| SubAIMs | JSON Metadata | Profiles |
Function
The A-User Rendering AIM (PGM-AUR) receives structured semantic and expressive inputs – Text, Personal Status, and Avatar Model parameters. Its primary function is to synthesise a coherent, expressive A-User embodiment by transforming semantic content and multimodal guidance into speech, facial expression, gesture, and avatar animation.
Internally, PGM-AUR performs the following operations:
- Personal Status Demultiplexing: Separates incoming Personal Status into modality-specific components – PS-Speech, PS-Face, and PS-Gesture – each guiding a distinct expressive channel.
- Speech Synthesis: Converts Machine Text into Machine Speech using a Speech Model, modulated by PS-Speech and formatted according to Speech Model specifications.
- Face Descriptor Construction: Combines Machine Speech and PS-Face to generate Entity Face Descriptors that encode expressive timing, gaze, and facial expression.
- Body Descriptor Construction: Uses PS-Gesture and Machine Text to produce Entity Body Descriptors, capturing posture, gesture rhythm, and spatial framing.
- Speaking Avatar Synthesis: Integrates Machine Speech, Face and Body Descriptors, and the Avatar Model to render a fully animated A-User Persona capable of expressive, multimodal communication.
The resulting outputs ensure that the A-User’s rendered behaviour is expressively coherent, semantically aligned, and visually synchronised with the User’s Personal Status – supporting emotionally resonant embodiment and reinforcing conversational trust through consistent multimodal expression.
Reference Model
Figure 11 gives the Reference Model of the A-User Rendering (PAF-AUR) AIM.
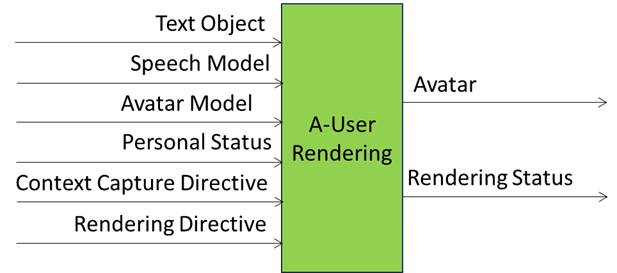
Figure 11 – Reference Model of A-User Rendering (PGM-AUR) AIM
Input/Output Data
Table 20 gives Input and Output Data of A-User Rendering (PAF-AUR) AIM.
Table 20 – Input and Output Data of A-User Rendering (PGM-AUR) AIM
| Input | Description |
| Text Object | Input Text. |
| Speech Model | Model used for speech synthesis. |
| Avatar Model | Model used for Avatar synthesis. |
| Personal Status | The A-User Personal Status of Speech, Face, and Gesture. |
| Rendering Directive | Commands driving avatar’s Personal Status and spatial output. |
| Output | Description |
| Avatar | Speaking Avatar uttering speech synthesised from Text and Personal Status. |
| Rendering Status | Rendering success and avatar expression state report to PGM-AUC. |
SubAIMs
Figure 12 gives the Reference Model of the A-User Rendering Composite AIM. This AIM is already standardised by MPAI with a different name.
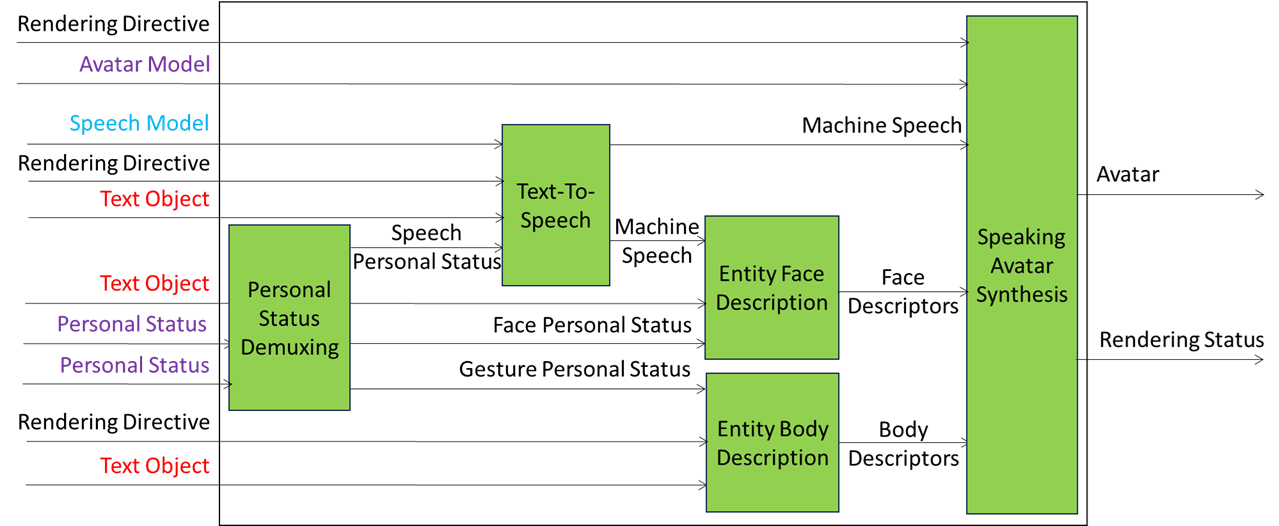
Figure 12 – Reference Model of the A-User Rendering Composite AIM
A-User Rendering Composite AIM operates as follows:
- Personal Status Demultiplexing makes available the component PS-Speech, PS-Face, and PS-Gesture Modalities.
- Machine Text is synthesised as Speech using a Speech Model in a format specified by NN Format and the Personal Status provided by PS-Speech.
- Machine Speech and PS-Face are used to produce the Entity Face Descriptors.
- PS-Gesture and Text are used for Entity Body Descriptors.
- Speaking Avatar Synthesis uses Avatar Model, Machine Speech, and Face and Body Descriptors to produce the Avatar.
- Rendering Directive overrides Avatar Model, Speech Model, Text,
- Avatar includes associated Speech.
- Rendering Status reports the success or otherwise of the Directive implementation.
Table 21 gives the list of PSD AIMs with their input and output Data.
Table 21 – AIMs of A-User Rendering Composite AIM and JSON Metadata
| AIW | AIMs | Name and Specification | JSON |
| PAF-SAR | A-User Rendering | X | |
| MMC-PDX | Personal Status Demultiplexing | X | |
| MMC-TTS | Text-to-Speech | X | |
| PAF-EFD | Entity Face Description | X | |
| PAF-EBD | Entity Body Description | X | |
| PAF-PMX | Speaking Avatar Synthesis | X |
JSON Metadata
https://mpai.community/standards/PGM1/V1.0/AIMs/AUserRendering.json
Profiles
No Profiles.