| Function | Reference Model | Input/Output Data |
| SubAIMs | JSON Metadata | Profiles |
1. Function
The Audio Spatial Reasoning AIM (PGM‑ASR) AIM processes the audio components of the environment to detect, segment, and analyse the audio environment including human speech. It acts as a bridge between raw Audio Scene Descriptors and higher-level reasoning modules by interpreting and refining spatial audio context to support reasoning and action execution:
| Receives | Audio Action Directive | Specifying how ASR should operate, including:
|
| Context | Current, unenhanced audio snapshot, used as the observational basis for updating its internally maintained, temporally coherent audio scene model:
|
|
| Refines | Audio Scene Descriptors | By constructing and updating structured representations of the audio scene, including:
|
| Aligns | The descriptors by consulting Domain Access, using domain knowledge to:
|
|
| Produces | ASD1 | Containing:
ASD1 is the authoritative description of the current audio scene sent to Prompt Creation (PGM-PRC). |
| Audio Action Status | Including:
Sent to A‑User Control to support orchestration. |
Specific Functionalities
- Speech Signal Acquisition: The ASR AIM receives the audio stream corresponding to Human speech as delivered by the system’s audio acquisition pipeline.
- Speech Activity Detection: The ASR AIM detects the presence of Human speech, identifies utterance boundaries, and segments audio into units suitable for processing.
- Acoustic and Linguistic Feature Extraction: The ASR AIM extracts the acoustic and linguistic elements of the speech signal, including phonetic/phonemic information, word/subword units, prosodic cues, timing, and structural markers such as pauses or hesitations.
- Audio‑Linguistic Descriptor Generation: The ASR AIM generates Audio‑Linguistic Descriptors from speech segments. These descriptors provide the formal representation of spoken language for downstream modules.
- Utterance Structuring: The ASR AIM organises descriptor sequences into coherent utterance structures, preserving temporal order, alignment, and metadata.
- Support for Referenced Expressions: The ASR AIM preserves linguistic markers that may refer to spatial or contextual elements (e.g., “this”, “that”, “here”, “there”), without resolving their meaning or grounding.
- Noise‑Robust Processing: The ASR AIM applies signal‑processing techniques suitable for reducing interference and maintaining descriptor accuracy under ambient noise conditions.
2. Reference Model
Figure 1 gives the of Audio Spatial Reasoning (PGM-ASR) AIM Reference Model.

Figure 1 – The Reference Model of the Audio Spatial Reasoning (PGM-ASR) AIM
3. Input/Output Data
Table 1 gives the Input/Output Data of the Audio Spatial Reasoning AIM.
Table 1 – Input/Output Data of the Audio Spatial Reasoning AIM
| Input | Description |
| Context | A structured and time-stamped snapshot representing the initial understanding of the environment and the User posture achieved by Context Capture. |
| Audio Spatial Directive | A dynamic modifier provided by the Domain Access AIM to help the interpretation of the Audio Scene by injecting directional constraints, source focus hints, salience maps, and refinement logic. |
| Audio Action Directive | Instructions issued by the A-User Control AIM to guide the Audio Spatial Reasoning AIM (PGM-ASR) in interpreting and acting upon the audio scene. |
| Output | Description |
| Audio Scene Descriptors | The enriched ASD1 enriched with the results of the reasoning made on the input ASD0, such as motion flags, proximity classification, and acoustic characteristics (e.g. reverb, echo, ambient noise). |
| Audio Action Status | A a report on the execution state and outcome of an Audio Action Directive. |
4. SubAIMs (informative)
A PGM-ASR implementation may implement the architecture of Figure 2.
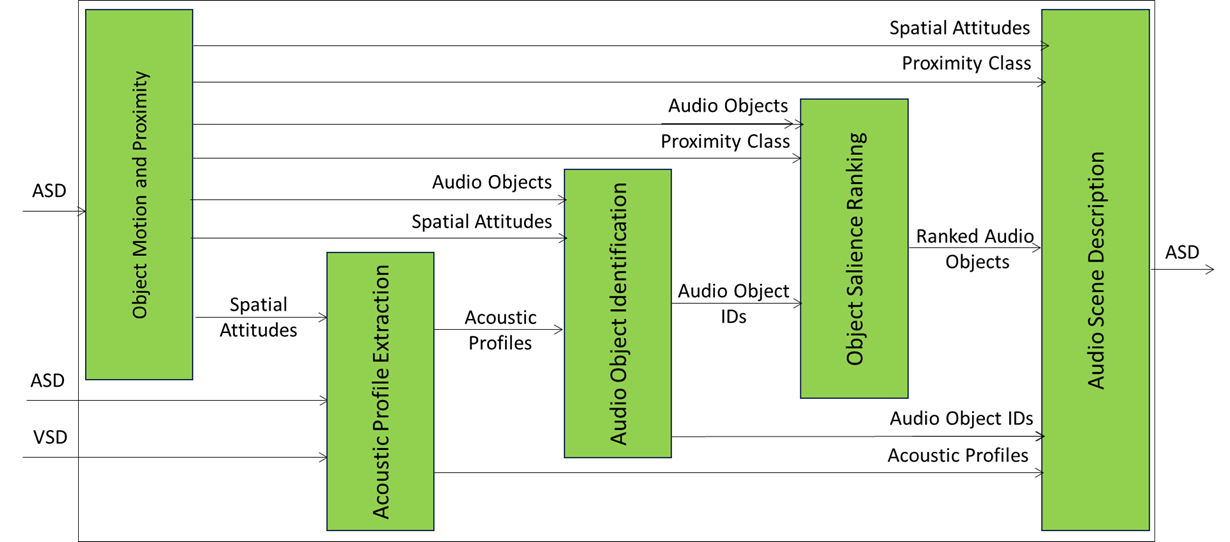
Figure 2 -Reference Model of the Composite Audio Spatial Reasoning (PGM-ASR) AIM.
Table 2 specifies the Functions performed by PGM-ASP AIM’s SubAIMs in the current example.
Table 2 – Functions performed by PGM-ASP AIM’s SubAIMs (example)
| SubAIM | Specification |
| Object Motion & Proximity | Purpose: Detects movement and proximity of audio objects with the following steps: – Track object trajectories over time. – Classify proximity zones (near, mid, far). – Extracts Spatial Attitude. Output: Motion and proximity metadata for each object. |
| Acoustic Profile Extraction | Purpose: Characterises objects’ Acoustic Profiles with the following steps: – Estimate reverberation (RT60), loudness, timbre, and frequency characteristics. – Identify environmental conditions (e.g., noisy, reverberant). Output: Acoustic Profile for each object |
| Audio Object Identification | Purpose: Adds preliminary semantic meaning to audio objects with the following steps: – Classify objects into broad categories (speech, music, noise, alarm). – Attach confidence scores. Output: Instance Identifier. |
| Object Salience Ranking | Purpose: Prioritises audio objects based on relevance with the following step: – Rank objects using proximity, semantic importance, and A-User Control Directives. Output: Ranked Audio Objects list. |
| Audio Scene Description | Purpose: Aggregates all enriched data into ASD₁ with the following steps: – Combine spatial, acoustic, semantic, and salience metadata. – Add PointOfView, EnrichmentTime, AIM ID. Output: ASD₁ is passed to DAC for domain-specific enrichment (and will be received as ASD₂). |
Table 3 gives the AIMs composing the Audio Spatial Reasoning (PGM-ASR) Composite AIM:
Table 3 – AIMs of the Audio Spatial Reasoning (PGM-ASR) Composite AIM
| # | SubAIM | Input | Output | To |
| OMP | Object Motion & Proximity | Audio Scene Descriptors | Spatial Attitudes, Proximity Class | ASD |
| Spatial Attitudes | APE | |||
| APE | Acoustic Profile Extraction | Audio Scene Descriptors | Audio Objects, Acoustic Profile | AOI |
| AOI | Audio Object Identification | Audio Objects, Acoustic Profiles, Motion Flags | Audio Object IDs | OSR |
| OSR | Object Salience Ranking | Audio Object IDs, Proximity Class | Ranked Audio Objects | ASD |
| ASD | Audio Scene Description | Spatial Attitudes, ProximityClass, AcousticProfile, Audio Objects, Audio Object IDs, RankedAudio Objects | ASD₁ | DAC |
| VSD | Visual Scene Description | Object Audio Characteristics | VDS₁ | DAC |
Table 4 provides the mapping from ASR Inputs/Outputs mapped to Unified Messages.
Table 4 — ASR Inputs/Outputs mapped to Unified Messages
| ASR Data Name | Role | Origin / Destination | Unified Schema Mapping |
|---|---|---|---|
| Audio Scene Descriptors (ASD0) | Input | From Context Capture (CXC) | Consumed by ASR as scene input; refined and returned via Status.Result |
| Audio Action Directive | Input | From A‑User Control (AUC) | Directive → Constraints/scopes in Parameters/Constraints; scheduling via Priority |
| Entity State (optional) | Input | From Context Capture (CXC) | If used by ASR: carried in Context, referenced as Entity State for posture/attention |
| Audio Scene Descriptors (refined ASD1/ASD2) | Output | To DAC / PRC | Status → Result (refined ASD); maintain Envelope.CorrelationId |
| Audio Action Status | Output | To A‑User Control (AUC) | Status → State/Progress/Summary/Result/Errors; feasibility/occlusion/reachability |
5. JSON Metadata
https://schemas.mpai.community/PGM1/V1.0/AIMs/AudioSpatialReasoning.json
6. Profiles
No Profiles