| 1. Function | 2. Reference Model | 3. Input/Output Data |
| 4. SubAIMs | 5. JSON Metadata | 6. Profiles |
| 7. Reference Software | 8. Conformance Testing | 9.Performance Assessment |
1. Function
The Space and User Description (PGM-SUD) AIM performs interpretative enrichment and cross‑modal analysis of a captured media scene in order to produce:
- enhanced descriptions of the audio and visual scene, and
- an interpreted description of the User Entity State.
SUD operates on time‑synchronised perceptual descriptors produced by Context Capture and applies modality‑specific analysis, cross‑modal alignment, and optional domain knowledge to derive evidence and state descriptions suitable for downstream reasoning and control.
2. Reference Model
The Space and User Description (PGM-SUD) reference model is organised as a multi‑stage interpretative pipeline operating on captured audio-visual descriptors as depicted in Figure 1.
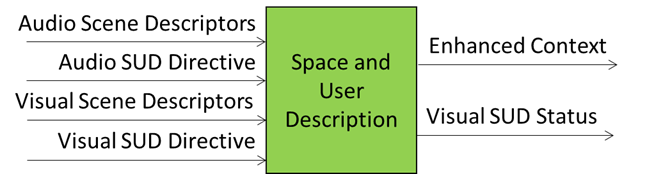
Figure 1 – Reference Model of Space and User Description (PGM-SUD)
3. Input/Output Data
Table 1 specifies the Input and Output Data of Space and User Description (PGM-SUD).
| Input | Description |
|---|---|
| Audio Scene Descriptors (ASD) | Perceptual description of the audio scene produced by Context Capture. |
| Visual Scene Descriptors (VSD) | Perceptual description of the visual scene produced by Context Capture. |
| SUD Directives | Control directives specifying scope, depth, or policy constraints for SUD processing. |
| Domain Information (optional) | Domain‑specific knowledge obtained through Domain Access. |
| Output | Description |
| Enhanced Audio Scene Descriptors | Audio Scene Descriptors augmented with derived and semantic properties produced by SUD. |
| Enhanced Visual Scene Descriptors | Visual Scene Descriptors augmented with derived and semantic properties produced by SUD. |
| Audio‑Visual Scene Geometry | Cross‑modal representation describing correspondence and spatial relations between audio and visual objects. |
| User / Entity Evidence and State | Descriptions derived from enhanced descriptors and alignment, including User Entity State. |
| Enhanced Context | Aggregated result combining enhanced scene descriptors and User‑related outputs. |
| SUD Status | Status information describing the execution and outcome of SUD processing. |
4. SubAIMs
The SUD operation includes the following SuAIMs.:
- Modal Scene Enhancement
- Independent enhancement of Audio Scene Descriptors and Visual Scene Descriptors.
- Extraction of derived properties such as salience, interaction potential, object type, depth, occlusion, and acoustic or visual profiles.
- Optional interaction with Domain Access for domain‑specific enrichment.
- Audio–Visual Alignment
- Cross‑modal association between Audio Objects and Visual Objects referring to the same source or entity.
- Production of Audio‑Visual Scene Geometry expressing correspondence and spatial relations.
- User Description
- Interpretation of enhanced descriptors and alignment evidence with respect to the User or other entities.
- Derivation of User‑centric evidence and state descriptions under the control of directives (User Entity State).
- Aggregation
- Consolidation of enhanced scene descriptors and User‑related outputs into a coherent Enhanced Context.
- Generation of status information describing the outcome of SUD processing.
The reference model explicitly separates capture, modal enhancement, cross‑modal alignment, and user/entity interpretation, ensuring modularity, traceability, and reuse.
This is depicted in Figure 2.
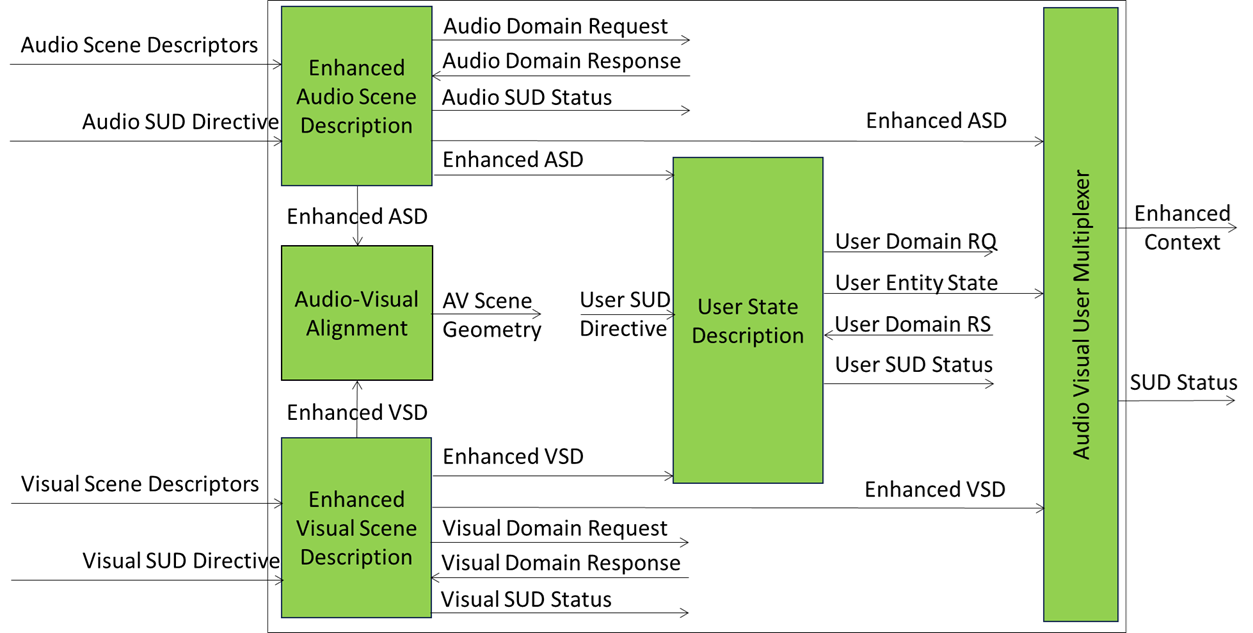
Figure 2 – Reference Model of the Space and User Description (PGM-SUD) AIM
Table 2 give the Input and Output Data of Space and User Description (PGM-SUD) SubAIMs.
Table 2 – Input and Output Data of Space and User Description (PGM-SUD) SubAIMs
| SubAIM | Input Data | Output Data |
|---|---|---|
| Audio Descriptor Parsing | Audio Scene Descriptors Audio SUD Directive |
Parsed Audio Objects Spatial Attitudes Audio SUD Status |
| Enhanced Audio Scene Description | Parsed Audio Objects Spatial Attitudes Audio SUD Directive Audio Domain Information |
Enhanced Audio Scene Descriptors Audio SUD Status |
| Visual Descriptor Parsing | Visual Scene Descriptors (VSD) Visual SUD Directive |
Parsed Visual Objects Spatial Attitudes Visual SUD Status |
| Enhanced Visual Scene Description | Parsed Visual Objects Spatial Attitudes Visual SUD Directive Visual Domain Information |
Enhanced Visual Scene Descriptors Visual SUD Status |
| Audio–Visual Alignment | Enhanced Audio Scene Descriptors Enhanced Visual Scene Descriptors |
Audio‑Visual Scene Geometry |
| User State Description | Enhanced Audio Scene Descriptors Enhanced Visual Scene Descriptors Audio‑Visual Scene Geometry User SUD Directive User Domain Information |
User Entity Evidence User Entity State User SUD Status |
| Audio Visual User Multiplexer | Enhanced Audio Scene Descriptors Enhanced Visual Scene Descriptors User Entity State |
Enhanced Context SUD Status |
5. JSON Metadata
https://schemas.mpai.community/PGM1/V1.0/AIMs/ContextCapture.json
6. Profiles
7. Reference Software
8. Conformance Testing
9. Performance Assessment