3 Step 2 – Define the Entities
4 Step 3 – Identify the relevant Game State Entities and their properties
5 Step 4 – Training Dataset Design
6 Step 5 – Training Dataset Collection
7 Step 6 – Train Prediction Models
9 Step 8 – Using and Evaluating SPG Predictions
10 Step 9 – Simulate Disturbance
11 Step 10 – SPG Qualitative Assessment
1 Process Outline
The process is defined as a series of steps to follow, where the key steps needed to design and implement an MPAI-SPG model are described. The first 4 steps are required to outline the game setup to allow more informed decisions for the implementation of SPG.
- Select the game.
- Define the Entities (to enable parameters identification):
- Environment
- Human-controlled players (HPC) and Non-player characters (NPC)
- Define the Game State and relevant Entities.
- Design training dataset.
- Collect training dataset.
- Train prediction models:
- define viable architectures
- define the training parameters
- compare training results of different architectures
- Implement SPG.
- Evaluate SPG to select the model yielding the best predictions.
- Implement modules which simulate the disturbances.
- Evaluate the SPG enabled game experience with human players.
For each step, high level guidelines are provided to outline the actions required. In addition, for each step, an example of how the guidelines should be followed are described using a car racing game as a use case.
2 Step 1 – Select a Game
2.1 Guidelines
SPG can be applied to any kind of multiplayer online game with the sole requirement that the networking architecture is based on an authoritative server. To function properly, the server must be able to correctly interpret and process the predicted game states received from SPG. Therefore, the server logic must be accessible to the developer as changes to the source code are required.
2.2 Example Game
The example game is a 3D multiplayer car racing video game where both the client and the server logic have been developed from scratch. In the game, each client runs a local game instance which sends the Spatial Attitude (SA) of the controlled car to the server by means of Client Data (CD). The server then processes the CD from all connected clients and computes GSt+1, essentially an aggregate of the SAs of all vehicles.
3 Step 2 – Define the Entities
3.1 Guidelines
Entities are the building blocks of the game’s environment and gameplay mechanics. They include any object or character within the game world that can interact with other objects or characters. The objective of this step is to identify how Entities affect the Game State to single out which of them will benefit from predictions. This is done by analysing the selected game and identifying all the Entities that are part of the game design and environment.
3.2 Example Game
The racing videogame has two types of game Entities: the immutable ones which populate the environment, and the cars. They can be either Human Playable Characters (HPC) or Non-Playable Characters (NPCs).
Environment
The Environment is the virtual space where the game takes place. For the considered game, it corresponds to the racetracks where the cars drive. Racetracks are built by combining different predefined Tiles; thus, any racetrack can be seen as an array of tiles (Figure 5). Each Tile is characterised by the following properties:
- Tile’s type: specifies the shape of the Tile (i.e. turn right, straight)
- Tile’s rank: corresponds to the index of the racetrack array associated with the Tile (i.e. the first Tile has rank 0, the fourth Tile has rank 3, etc.).
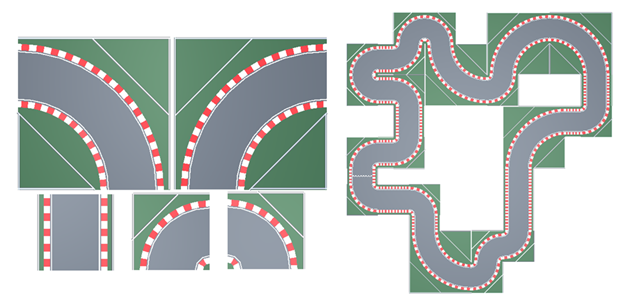 Figure 5 – Modular tiles and an example of a racetrack
Figure 5 – Modular tiles and an example of a racetrack
Racetracks contain multiple Checkpoints, i.e., a marked location on the track, arranged in an ordered sequence. Each car must pass through a Checkpoint to ensure they are following the correct path. To complete a lap, a car must pass through each Checkpoint in the right order.
HPC/NPC
In the considered game, cars are the only playable Entities. The player’s input is captured from a keyboard and controls the vehicle’s acceleration, brakes, and steering, ultimately updating its SA. The three inputs are integers values which can have the following values:
- Acceleration: 0 or 1
- Brakes: 0 or 1
- Turning: -1, 0, or 1
Cars can collide with other cars and with the walls of the racetrack. The physical simulation is allocated to the Game Server’s Physic Engine.
4 Step 3 – Identify the relevant Game State Entities and their properties
4.1 Guidelines
To make Predictions, it is required to identify the minimal set of Entities and their properties affecting the Game State. These Entities and properties should be carefully selected to achieve a balance between Prediction accuracy and Model complexity since the Model will be required to operate in real-time. This selection could result from an iterative process evaluating the outcomes validated during the following steps in the procedure.
4.2 Example Game
The Game State is affected by:
- The aggregation of the Spatial Attitudes of all cars.
- The next Checkpoint each car must traverse.
- Each car’s lap number.
The car’s Spatial Attitude was considered as the minimal required data to accurately predict the next Game State. In this context, the predicted data are only processed by the Behaviour Engine.
5 Step 4 – Training Dataset Design
5.1 Guidelines
In an ideal scenario, the entire Game State can be used as an input vector for predicting the desired properties defined in the previous step. However, the time required to compute a prediction (TC) can be affected by the number of parameters included in the input vector. Therefore, if TC exceeds the computational time available in a single game update cycle (16 ms in the best case), a subset of the entire Game State must be selected.
At this stage it is difficult to make an informed decision on the game state elements that should be retained in the subset. Therefore, the selection of game state elements should be extended to cover all those elements which could contribute to the Game State Prediction. Once these elements have been defined, a dataset is needed for training the Neural Network Model. Data may be obtained from already available datasets or should be produced. In the latter case, two approaches are possible: collect data from humans playing the game or rely on AI agents trained to imitate human player behaviour, including the fact that players have different abilities and styles.
The selection of the most effective GS subset must be assessed from the prediction accuracies evaluated in the next steps of the procedure. Therefore, the definition of the final GS subset may require an iterative process.
5.2 Example Game
The training data chosen to feed the prediction network includes the car’s Spatial Attitude and the surrounding environment. The environment data collected includes:
- The type of Tile the car is on.
- The Tile’s ranking relative to the other Tiles of the track (e.g. first, fourth or last tile of the track).
- The car’s position relative to the centre of the Tile.
Since the game was developed from scratch, no datasets were available. Therefore, to suitably train MPAI-SPG, a synthetic dataset was generated by simulating game sessions with autonomous agents using the ML-Agents toolkit, a ML framework for Unity. This approach overcomes the impracticality of collecting data through extensive gameplay sessions.
Autonomous agents, trained with a Curriculum Learning approach, are trained on tracks of increasing complexity, applying penalties for collisions with track walls or other players and for incorrect Checkpoint passages, and rewards for completing laps and correctly navigating through Checkpoints. Also, to emulate a variety of real-world driving styles, four distinct agent types governed by a unique set of rewards and penalties are used. Rewards were applied encouraging acceleration and optimal alignment to the next Checkpoint, and penalties for braking.
6 Step 5 – Training Dataset Collection
6.1 Guidelines
In the case no dataset is available, one must be produced by running actual gaming sessions, played by either real players or AI agents. When running these sessions, the following points should be kept in mind:
- Player’s abilities should have as wide a variety as possible. This guideline applies both to the case of real players and AI agents.
- To ensure variability, consider different starting conditions when running the gaming sessions.
- Define an adequate sampling frequency for the selected subset of the game state. Frequency selection is influenced by the game type: fast vs slow-paced style game, e.g., real time strategy games vs first person shooters.
Keeping in mind the considerations of Step 4, it is crucial to consider the need to maintain the complexity of the problem at a manageable level. For instance, it is important to find the right balance between having a large variety of game scenarios and finding the most representative ones.
The produced dataset must be divided into three sets: train, test and validation.
6.2 Example Game
To produce the dataset, the AI agents described in Step 4 raced over a single track in multiple game instances. The choice of collecting data over a single track is an example of balancing complexity over representativeness, as the selected track was the most complex one and included many possible scenarios already appearing in simpler tracks.
Each game was composed of three laps, during which the Game State subset (Step 4) was sampled every 0.02 seconds. At the end of this process, a dataset of 2 million records was collected. The dataset was divided into train, validation and test sets. The train set contains half of the initial dataset, while test and validation sets contain 25% each.
7 Step 6 – Train Prediction Models
7.1 Guidelines
In most cases, the game state evolution can be modelled as a time series. Therefore, a Neural Network architecture suitable for the task of predicting the Game State should be found. Possible candidates are LSTM, Transformer, and Diffusion Models.
Once a technology has been selected, a Model should be trained using different game state element subsets (see Step 5). Each subset is evaluated for performance against the validation set and a pool of the better subsets (e.g., three or four) is identified for use in the following Steps, where their performance will also be evaluated in the target game.
7.2 Example Game
MPAI-SPG’s Behaviour Engine AI is designed to predict the car’s SA. The Predictions are based on a temporal series of previous Game States using a deep LSTM. The model consists of a deep LSTM network connected to a multilayer perceptron (MLP). In the network, each LSTM is followed by a Batch Normalization layer, except the last one. The model is depicted in Figure 6.
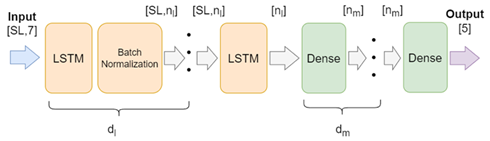
Figure 6 – Neural network architecture.
During training, the loss is measured by the Mean Square Error between the real and predicted car’s SA. The LSTM and MLP layers are initialized with the default values from the TensorFlow library. The optimiser leverages the Adam algorithm [7], with an initial learning rate (lr) of 0.001 halved every time the validation loss plateau is reached. The batch size is 512 samples. The Model is trained for 100 epochs with early stopping. After completing the training, the Model parameters that show the lowest validation loss are saved.
The Game State element subset which yielded the best results is composed of 7 elements:
- Tile Type the car is on (1 element),
- Tile Ranking relative to the other Tiles of the track (e.g. first, fourth or last Tile of the track) (1 element)
- Position of the car relative to the centre of the Tile (2 elements)
- Car’s velocity (2 elements),
- Car’s rotation (1 element).
Therefore, the input for the LSTM network is RSL×7, a matrix where SL stands for the length of the time sequence.
Table 6 lists the most impactful parameters during training and their suggested values.
Table 6 – Training parameters
| Property | Acronym | Min | Max |
| Numbers of LSTM layers | dl | 0 | 5 |
| The number of units in each LSTM layer | nl | 32 | 512 |
| Depth of the MLP | dm | 0 | 5 |
| Number of hidden units in the MLP | nm | 32 | 512 |
| Sequence Length | SL | 10 | 50 |
| Time between Predictions | Tp | 0.1 | 0.2 |
In the context of this game the Mean Absolute Error (MAE) quantifies the difference between the predicted and the real SA. Therefore, a subset of networks which produce the smallest MAE on the validation is selected. By analysing the number of Epochs, it is possible to understand if a network overfits; this information can be used to implement Early Stopping during training.
Table 6 reports the configurations and results of the four best Models trained. Each Model is identified by a unique ID, which will be used to reference them in the following. By comparing the minimum MAE achieved by the Models on the validation set, the ones with higher SL generally demonstrated better performance. Additionally, Models 2 and 4 share the same configuration apart from the SL, but Model 2 overfitted, stopping the training earlier. Among all models, Model 4 achieved the lowest error.
Table 3 – Trained models
| ID | dl | nl | dm | nm | SL | MAE | Epochs |
| 1 | 3 | 64 | 3 | 64 | 20 | 0.579 | 100 |
| 2 | 3 | 256 | 3 | 64 | 20 | 0.544 | 35 |
| 3 | 1 | 256 | 0 | 0 | 40 | 0.569 | 87 |
| 4 | 3 | 256 | 3 | 64 | 40 | 0.453 | 100 |
1.8 Step 7 – Implement SPG
1.8.1 Guidelines
Ideally, TC should be equal or smaller than the clock period, as this ensures that Predictions are computed before a new game state is evaluated. However, this condition is not guaranteed, in case the SPG Engines cannot keep up with the computational load. As shown in Figure 7, two strategies are possible. One is to wait until the server is ready to provide the latest available data, which happens at multiples of the game clock period (Tg). Alternatively, the Engines can start working on the input data as soon as the previous computation is completed. In the first case, the training can be done by keeping the Prediction time constant, Tp. The second option may be more effective but requires that Engine be trained to make Predictions on a variable time frame.
1.8.2 Example Game
In the game, SPG was required to predict only the car’s SA. Therefore, only the Behaviour Engine AI was developed. In this context, the Game State DMUX extracts, for each car, a game message containing the environment surrounding the car and its SA, sending it to the Behaviour Engine AI. The engine outputs a series of for each car, containing the predicted SA. These data are then combined by the Game State Assembler which outputs a predicted Game State (pGSt+1) which is forwarded to the Game Server. The first solution described above was implemented to account for the problem of TC exceeding the game clock period. The value of Tp is equal to 0.1 seconds. Therefore, the previous annotation changes in the following: and pGSt+Tp.
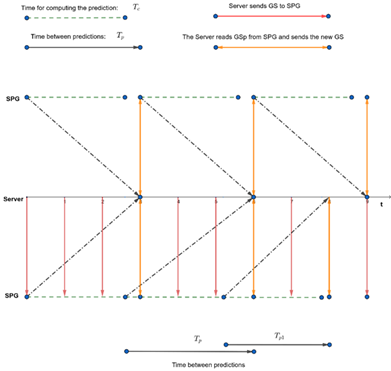 Figure 8 – Prediction alternatives when Tc is greater than Tp
Figure 8 – Prediction alternatives when Tc is greater than Tp
1.9 Step 8 – Using and Evaluating SPG Predictions
1.9.1 Guidelines
When using MPAI-SPG Predictions in a game environment, two possible issues may arise:
- The MAEs measured in the training environment may differ when Predictions are applied in the game because the models which give the best results during training (Step 6) may not be the best performing (i.e., prediction accuracy) in the game;
- The server may need to apply MPAI-SPG Predictions for several consecutive times. Whenever Predictions are used, they serve as input for the subsequent MPAI-SPG predictions. This causes error accumulating as time progresses. This behaviour will be referred in the following as Error Accumulation.
Therefore, a pool of Models with the best results obtained in Step 6 (i.e., training environment) should be evaluated in the game scenario and the best performing one selected for use in the game. To perform this evaluation, the outputs of two simulations should be compared for each Model, one where Predictions are not used (i.e., the human or agent player, is in control), and another where SPG is in control. Data should be collected from the simulations to calculate a comparison metric (e.g., MAE of the SA). The comparison metric can be used to decide which Model produces the best Predictions overall and by analysing the metric’s evolution over time, the level of Error Accumulation can be assessed. This analysis will verify which of the Models from Step 6 is the best choice for the game environment.
Also, it should be noted that if the Models have been trained with synthetic data (i.e., data collected from agent players), when asked to predict the Game State using human player data a domain shift issue could happen. Therefore, in this scenario, the same evaluation should be performed by comparing SPG Predictions with Entities controlled by human players.
1.9.2 Example Game
To identify which of the four models (trained in Step 6) has the lowest error accumulation, several games were run where a ghost car would invisibly run alongside an agent player’s car. The ghost car would normally replicate the player’s car SA and, at different intervals, it would be controlled by SPG predictions, applied for 1 consecutive second. During this interval the game saves the SA of the car controlled by the player and the car controlled by SPG predictions. The result of this process, repeated a few tens of times, was used to compute the MAE between position, velocity and orientation of the car controlled by the agent player and the car controlled by SPG predictions.
The MAEs between the SPG predictions and the car driven by the agent player is shown in Figure 8. The MAEs were normalized to the highest possible change in the position, velocity and orientation that a car can make in 0.2 seconds (Tp). The results reveal that Model 4 was the one with the highest error accumulation.
Model 4, the model with the lowest validation MAE during training (Step 6), achieved the worst overall prediction quality between all models. Contrary to our anticipation, the other three models (having sequence length of 20) emerged as the top performers. Between models 2 and 1, the former demonstrated higher quality in the initial prediction (0 seconds), whereas Model 1, starting from the second prediction (0.2 seconds), showed a lower error in velocity predictions. Despite Model 1 having the highest error in orientation, the impact is mitigated by the lower magnitude of the rotation error. In fact, Model 1 attains the lowest error on the position evaluation.
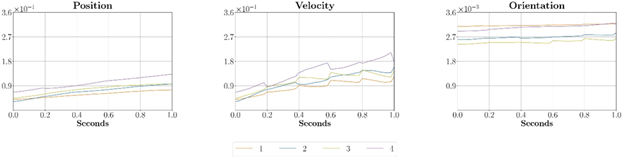 Figure 9: Normalized Position, Velocity and Orientation MAEs between the agent and the SPG predictions for the four models trained in Step 6.
Figure 9: Normalized Position, Velocity and Orientation MAEs between the agent and the SPG predictions for the four models trained in Step 6.
The second experiment was conducted keeping all conditions but replacing the agent player with human players, 12 of which played 2 laps and using only Model 1 to compute the SPG predictions. The objective was to assess how well SPG was able to predict missing data when the player was a human. Figure 9 shows that the accumulated error of the Position and Velocity after 1 second was about 1.5 times (blue line) the error of the agent player (green line). The performance of the Orientation on the human and agent players was about the same.
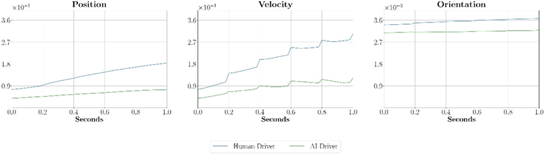
Figure 10 – Normalized Position, Velocity and Orientation MAEs between the human and the SPG predictions using Model 1.
1.10 Step 9 – Simulate Disturbance
1.10.1 Guidelines
The experiments in the previous step aimed at evaluating the prediction accuracy of the trained models to select the better performing one. Once identified, SPG should be evaluated (using the identified model) in an actual online multiplayer scenario. Since SPG activates in case of missing data due to network issues, this condition should be simulated. This simulation can be achieved at two levels:
- Application Level: the application (the game) purposely does not send data (client) or discards it (server).
- Network Level: actual network issues (latency or packet loss) are simulated outside the application environment.
1.10.2 Example Game
In the example game, network disturbance was simulated at the application level. This was achieved by developing a discard module, in charge of discarding client data on the server. This module was controlled by two parameters: discard length, the number of consecutive seconds where data is discarded, and discard interval, the seconds between discard sequences. Different values of these parameters establish three Discard Levels (DLs), summarized in Table 6.
Table 7 – Discard Level Parameters
| DL | Length (s) | Interval (s) |
| DL1 | 0 | 0 |
| DL2 | 0.3 | 10 +/- 2 |
| DL3 | 0.6 | 8 +/- 2 |
1.11 Step 10 – SPG Qualitative Assessment
1.11.1 Guidelines
As a final step the gaming experienced by human players must be assessed. Human players should play the game under two conditions: no network disturbances (i.e., no predictions are computed and used by SPG) and simulating disturbances with SPG active to compensate for missing data. Several game runs should be performed under both conditions and at the end of each condition players should be asked to fill out a questionnaire addressing the following key points:
- Perception of anomalous behaviour from player-controlled and game-controlled entities
- Perceived game responsiveness to players’ inputs
- Overall gaming experience
These key points apply to all games, but the questionnaire may address other game-dependent key points.
Depending on the availability of human players, the game may be played by some human and some agent players.
To further evaluate the impact of SPG, a third condition can be tested with simulated disturbances but without SPG correction.
1.11.2 Example Game
In the example game the qualitative assessment involved gaming sessions where:
- One human player raced against other 4 agent players.
- Each agent player was executed on a separate process instance and connected as client to the server
- Only the 4 agent players were affected by simulated network issues, using the discard module described in Step 9.
The human player completed several game sessions under two conditions: absence and presence of network issues. In the latter condition two Discard Levels (DL1 and DL2 from Table 6) were used. At the end of each game session the player filled a questionnaire composed of the following questions (aimed at addressing the key points described in the guidelines):
- Q1: How would you rate your gaming experience in this match?
- Q2: How would you rate the responsiveness of the inputs?
- Q3: How many anomalous behaviours did you encounter during the match?
The results summarised in Figure 10 show that between the no network issues (blue bar) case and network issues with DL1 level (orange bar) there is a very small difference for the Game Experience and Responsiveness scales, while for DL2 (green bar) the difference is more evident. On the other hand, the perception of odd behaviours (green bar) increases in DL1 and DL2, however remaining below 3 on a scale of 5.
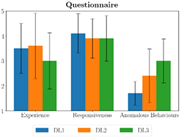
Figure 10 – Questionnaire results.