| CAE | CAV | HMC | MMC | OSD | PAF |
| AI Workflows | AI Modules |
1 AI Workflows
1.1 Audio Recording Preservation
USC-ARP is a PAAI restores an open reel audio tape by detecting the audio and visual irregularities.
USC-ARP is composed of a set of collaborating PAAIs:
| Audio Analysis for Preservation | – Receives Video Analysis for Preservation’s Video Irregularity File. – Detects irregularities. – Extracts Audio files of each detected/received Audio Irregularity – Sends Irregularity Audio File & Audio Irregularity File for each irregularity to Tape Irregularity Classification. |
| Video Analysis for Preservation | – Receives: Audio Analysis for Preservation’s Audio Irregularity File and offset between Preservation Audio File and Preservation Audio-Visual File. – Detects irregularities. – Extracts Images of each detected/received Video Irregularity. – Sends Irregularity Image & Video Irregularity File of each irregularity to TIC |
| Tape Audio Restoration | Produces the Restored Audio Files and the Editing List used to restore portions of the Preservation Audio File using the Irregularity Files. |
| Tape Irregularity Classification | – Produces Irregularity Files from: – Irregularity Files of the Audio component and corresponding Irregularity Audio Files. – Irregularity Files of the Video component and corresponding Irregularity Images. |
| Tape Audio Restoration | Produces the Restored Audio Files and the Editing List used to restore portions of the Preservation Audio File using the Irregularity Files. |
| Packaging for Audio Preservation | Assembles the output files. |
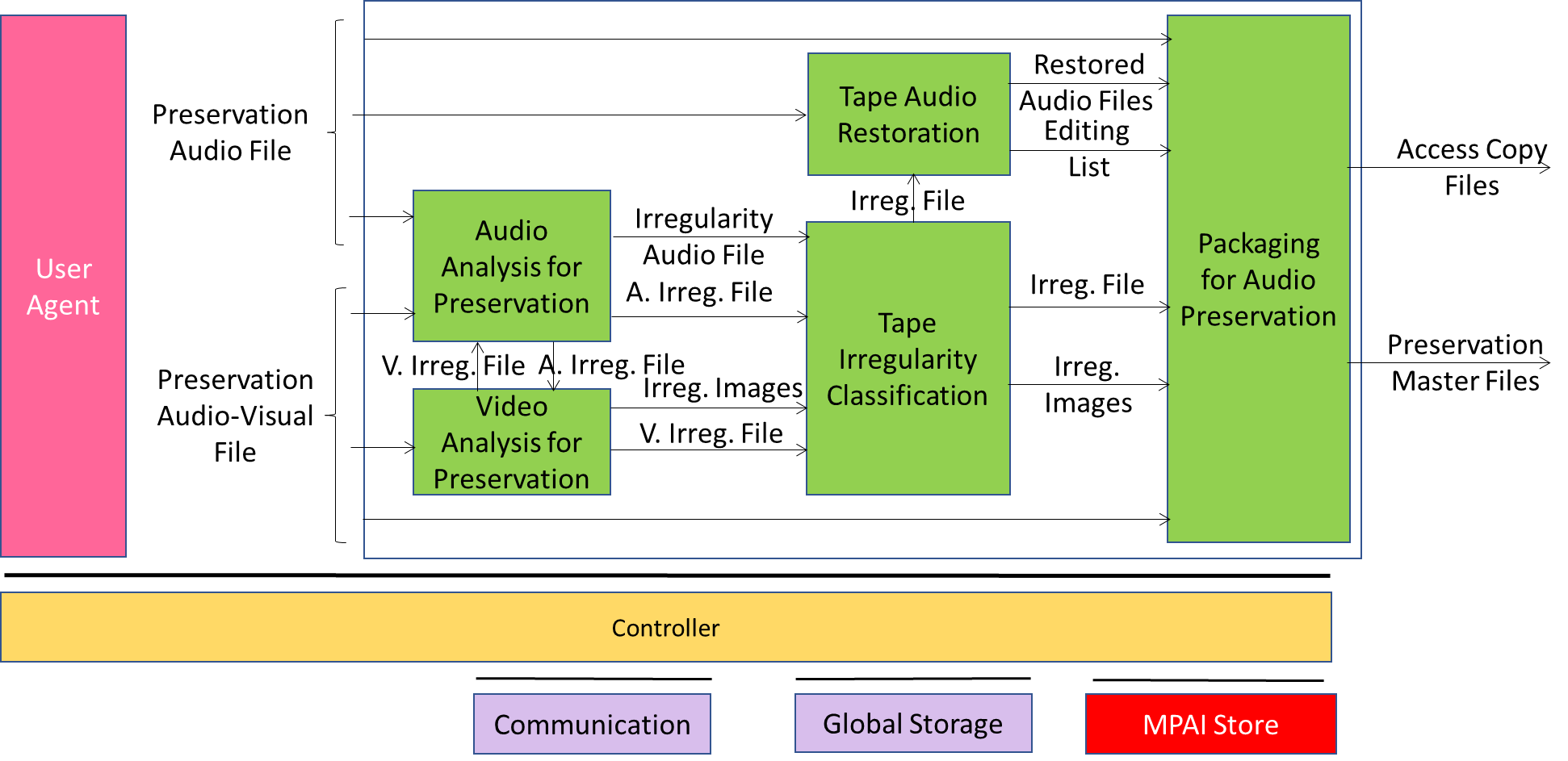
Figure 8 – Reference Model of USC-ARP
The following links analyse the AI Modules:
Audio Analysis for Preservation
Packaging for Audio Preservation
Tape Audio Restoration
Tape Irregularity Classification
Video Analysis for Preservation
1.2 Emotion-Enhanced Speech
USC-EES is a PAAI that inserts a prescribed emotion into an Emotionless Speech includes two PAAIs in two configurations that use different collaborating PAAIs:
| #1 | Speech Feature Analysis1 | Extracts Prosodic Speech Features from a Model Utterance. |
| Prosodic Emotion Insertion | Adds the Prosodic Speech Features to an Emotionless Speech with an Emotion whose type is indicated by a user. | |
| #2 | Speech Feature Analysis1 | Extracts Emotionless Speech Features from an Emotionless Speech segment. |
| Emotion Features Production | Extracts Neural Speech Features from the Emotionless Speech Features based on an Emotion List and an indication of the language. | |
| Neural Speech Insertion | Adds Neural Speech Features to the Emotionless Speech. |
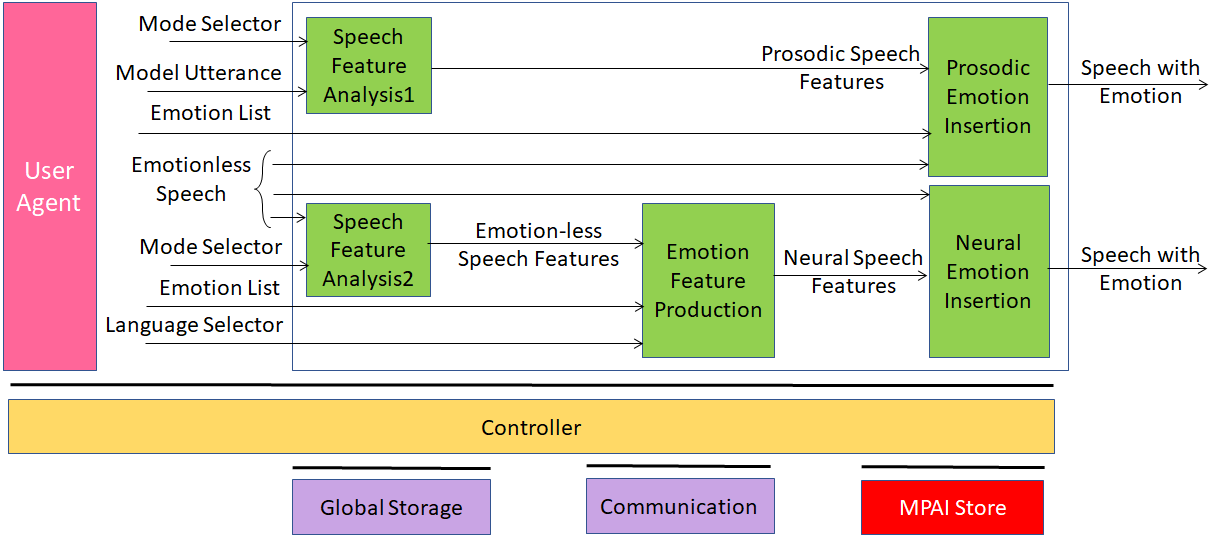 Figure 9 – Reference Model of USC-EES
Figure 9 – Reference Model of USC-EES
The following links analyse the AI Modules:
Speech Feature Analysis 1
Speech Feature Analysis 2
1.3 Enhanced Audioconference Experience
USC-EAE is a PAAI that produces a Multichannel Audio Stream acting on an input Microphone Array Audio.
USC-EAE is composed of the following PAAIs:
| Audio Analysis Transform | Represents the input Multichannel Audio in a new form amenable to further processing by the subsequent PAAIss in the architecture. |
| Sound Field Description | Produces Spherical Harmonic Decomposition Coefficients of the Transformed Multichannel Audio. |
| Speech Detection and Separation | Separates speech and non-speech signals in the Spherical Harmonic Decomposition producing Transform Speech and Audio Scene Geometry. |
| Noise Cancellation Module | Removes noise and/or suppresses reverberation in the Transform Speech producing Enhanced Transform Audio. |
| Audio Synthesis Transform | Effects inverse transform of Enhanced Transform Audio producing Enhanced Audio Objects ready for packaging. |
| Audio Description Packaging | Multiplexes Enhanced Audio Objects and the Audio Scene Geometry. |
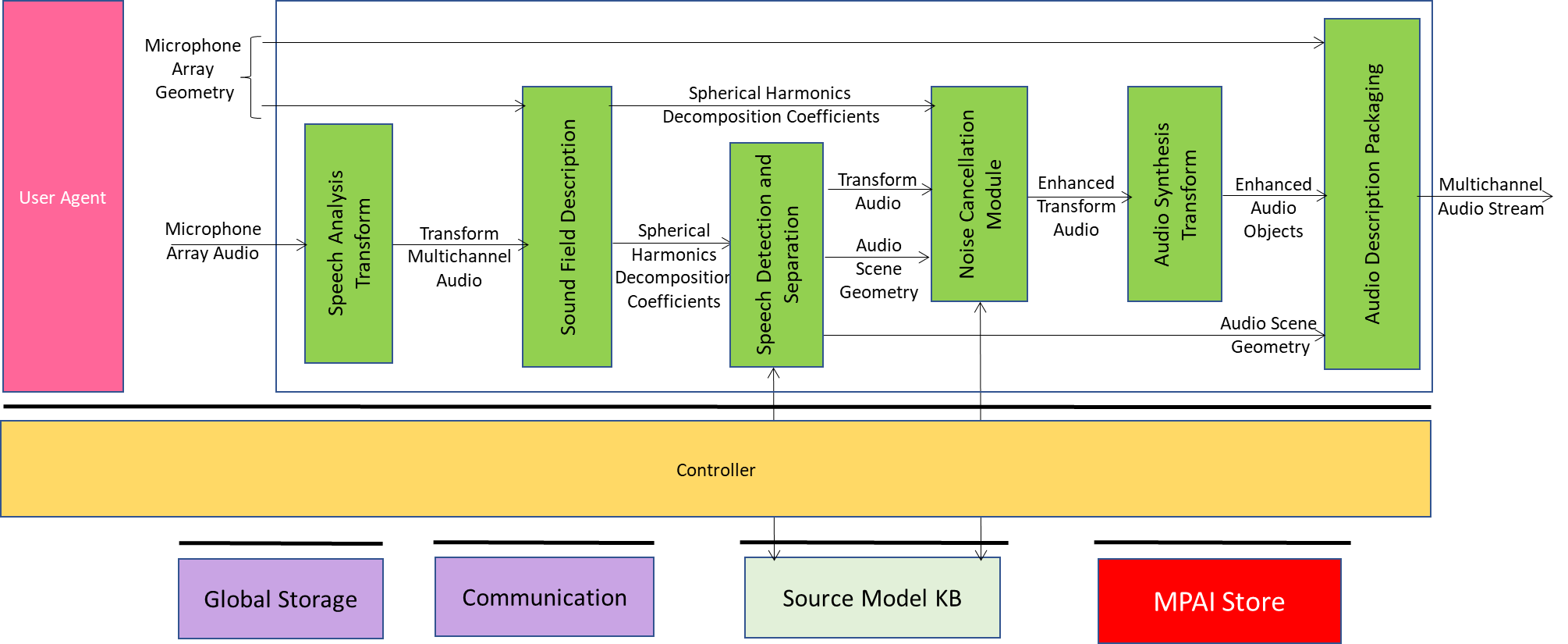 Figure 10 – Reference Model of USC-EAE
Figure 10 – Reference Model of USC-EAE
Audio Description Packaging
Audio Synthesis Transform
Noise Cancellation Module
Speech Analysis Transform
Sound Field Description
Speech Detection and Separation
1.4 Speech Restoration System
CAE-SRS is a PAAI collecting speech segments of a particular speaker, training a Neural Network Model to synthesise Speech with the so-trained Neural Network Speech Model form Text and use the synthesised Speech to replaced damaged Speech Segments.
CAE-SRS is composed of three collaborating PAAIs:
| Speech Model Creation | Trains a Neural Network Model with Speech Segments. |
| Speech Synthesis for Restoration | Uses the Neural Network Speech Model to synthesise a Speech Object from a Text Object. |
| Speech Restoration Assembly | Replaces a Damaged Segmented indexed by a Damaged List with the Synthesised Speech. |
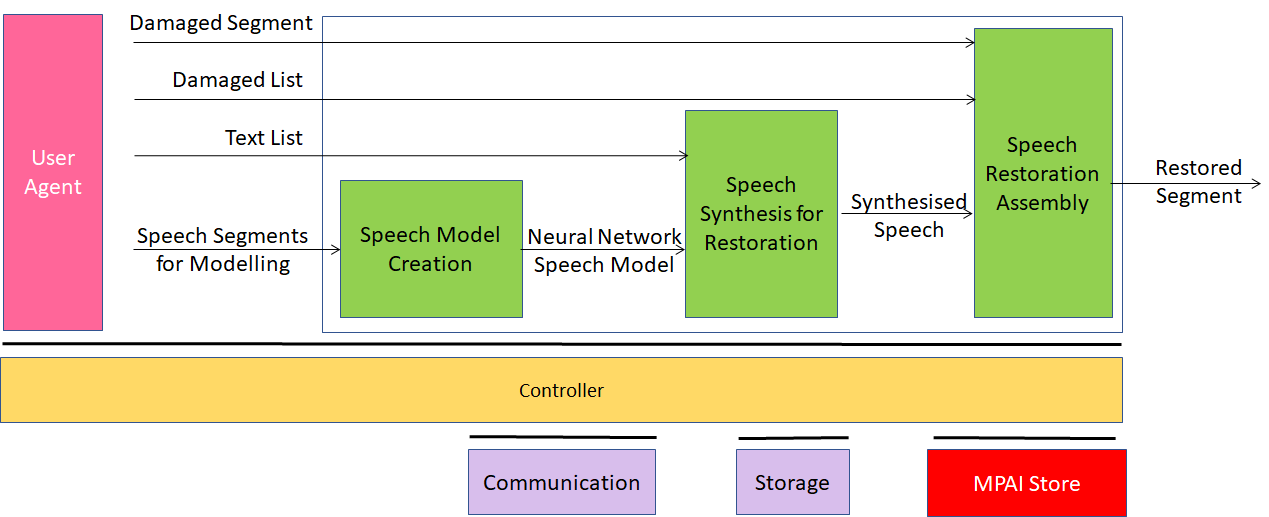 Figure 11 – Reference Model of CAE-SRS
Figure 11 – Reference Model of CAE-SRS
Speech Synthesis for Restoration trains a Neural Network but this is done before the restoration process begins, not while restoring the Speech.
The following links analyse the AI Modules:
Speech Restoration Assembly
Speech Synthesis for Restoration
2 AI Modules
2.1 Audio Analysis for Preservation
CAE-AAP is a PAAI
| Receives | Preservation Audio File | From Preservation Audio File |
| Preservation Audio-Visual File | From Preservation Audio-Visual File | |
| Video Irregularity File | From Video Analysis for Preservation | |
| Produces | Audio Irregularity File | To Tape Irregularity Classification |
| Irregularity Audio File | To Tape Irregularity Classification |
CAE-AAP detects irregularities in the Preservation Audio File weighing them against the Video Irregularity received from CAE-VAP. This process may be performed with regular data processing techniques or with a Neural Network trained with a sufficiently large training dataset.
CAE-AAP performs Descriptors-Interpretation Level Operation.
2.2 Emotion Feature Production
CAE-EFP is a PAAI that:
| Receives | Emotionless Speech Features | From Speech Feature Analysis2 |
| Emotion List | Emotion that the Neural Speech Features should convey. | |
| Language Selector | Language of the Emotionless Speech. | |
| Produces | Neural Speech Features | To feed Neural Emotion Insertion |
CAE-EFP is implemented as a Neural Network trained to extract Speech Features from an Emotionless Speech.
CAE-EFPP performs Descriptors Level Operations.
2.3 Neural Emotion Insertion
CAE-NEI is a PAAI that:
| Receives | Emotionless Speech | |
| Neural Speech Features | From CAE-EFP | |
| Produces | Speech With Emotion | Adding Neural Speech Features to Emotionless Speech |
CAE-NEI is implemented as a Neural Network cognizant of the semantics of the Neural Speech Features it receives for insertion into the Emotionless Speech so that it carries the desired Emotion.
CAE-NEI performs Data Processing Level Operations.
2.4 Prosodic Emotion Insertion
CAE-PEI is a PAAI
| Receiving | Prosodic Speech Features | From Speech Feature Analysis2 |
| Emotion List | Emotion that the Neural Speech Features should convey. | |
| Emotionless Speech | Input to be made emotional. | |
| Producing | Speech with Emotion | The resulting Emotion-carrying Speech. |
CAE-PEI must be cognizant of the semantics of the Prosodic Speech Features so that it can add Emotion to the Emotionless Speech.
CAE-PEI performs Data Processing Level Operations.
2.5 Speech Feature Analysis 1
CAE-SF1 is a PAAI that:
| Receives | Model Utterance | containing emotion. |
| Extracts | Speech Features1 | from the Model Utterance. |
| Produces | Prosodic Speech Features. | for insertion into Emotionless Speech. |
CAE-SF1 can be implemented with data processing techniques to or with a Neural Network trained to extract Prosodic Speech Features from Emotion-carrying utterances.
CAE-SFI performs Descriptors Level Operations.
2.6 Speech Feature Analysis 2
CAE-SF2 is a PAAI:
| Receiving | Emotionless Speech | to be made Emotion-carrying. |
| Extracting | Emotionless Speech Features | from Emotionless Speech |
| Producing | Emotionless Speech Features | for insertion into Emotionless Speech. |
CAE-SF2 is implemented as a Neural Network trained to extract Speech Features.
CAE-SF2 performs Descriptors Level Operations.
2.7 Speech Model Creation
CAE-SMC is a PAAI
| Collecting | Speech Segments | in sufficient number for NN training |
| Producing | Neural Network Speech Model | for text-to-speech synthesis. |
CAE-SMC can only be implemented with a Neural Network training set up.
CAE-SMC performs Training Level Operations.
2.8 Tape Irregularity Classification
CAE-TIC is a PAAI that:
| Receives | Audio Irregularity Files |
| Irregularity Audio Files | |
| Video Irregularity Files | |
| Irregularity Images | |
| Irregularity Files | |
| Irregularity Images | |
| Produces | Irregularity File |
CAE-TIC is implemented as a Neural Network trained to confirm as an Irregularity an Audio and/or Visual Irregularity with the corresponding Audio or Image Irregularity
CAE-TIC performs Reasoning-Level Operations.
2.9 Video Analysis for Preservation
CAE-VAPAP is a PAAI that:
| Receives | Preservation Audio-Visual File | Input to the CAE-ARP. |
| Audio Irregularity File | From Audio Analysis for Preservation | |
| Producing | Audio Irregularity File | To Tape Irregularity Classification |
| Irregularity Image | To Tape Irregularity Classification |
CAE-VAP detects irregularities in the Preservation Audio-Visual File weighing them against the corresponding Audio Irregularity received from CAE-VAP.
This process may be performed with regular data processing techniques or with a Neural Network trained with a sufficiently large training dataset.
CAE-AAP performs Descriptors-Interpretation Level Operation.