| <–A renewed life for the patent system | Conclusions–> |
| 19.1 | AI-enhanced video coding |
| 19.2 | End-to-end video coding |
| 19.3 | Server-based predictive multiplayer gaming |
| 19.4 | Connected autonomous vehicles |
| 19.5 | Conversation about a scene |
| 19.6 | Mixed-reality collaborative spaces |
| 19.7 | Audio on the go |
19.1 AI-enhanced video coding
Video Coding research focuses on radical changes to the classic block-based hybrid coding framework to face the challenges of offering more efficient video compression solutions. AI can play an important role in achieving this goal.
According to a survey of the recent literature on AI-based video coding, performance improvements up to 30% are expected. Therefore, MPAI is investigating whether it is possible to improve the performance of the MPEG-5 Essential Video Coding (EVC) modified by enhancing/replacing existing video coding tools with AI tools keeping complexity increase to an acceptable level.
The AI-Enhanced Video Coding (MPAI-EVC) Evidence Project is extend-ing/enhancing MPEG-5 EVC with the goal of improving its performance by up to 25%. The EVC Baseline Profile has been selected because it is made up with 20+ years old technologies and has a compression performance close to HEVC, and the performance of its Main Profile exceeds that of HEVC by about 36 %. Additionally, some patent holders have announced that they would publish their licence within 2 years after approval of the EVC standard.
Once the MPAI-EVC Evidence Project will demonstrate that AI tools can improve the MPEG-5 EVC efficiency by at least 25%, MPAI will be in a position to initiate work on the MPAI-EVC standard by issuing a Call for Technologies.
Currently, two tools are being considered: Intra Prediction and Super Resolution.
Intra prediction takes advantage of the spatial redundancy within video frames to predict blocks of pixels from their surrounding pixels and thus allowing to transmit the prediction errors instead of the pixel values themselves. Because the prediction errors are of smaller values than the pixels themselves, compression of the video stream to be achieved. Traditional video coding standards leverage intra-frame pixel value dependencies to perform prediction at the encoder end and transfer only residual errors to the decoder. Multiple “Modes” are used, which are various linear combinations of neighbours pixels of the macro blocks being considered. EVC has 5 prediction modes (Figure 28):
- DC: the luminance values of pixels of the current block are predicted by computing average of the luminance values of pixels from upper and left neighbours
- Horizontal prediction: the same mechanism but using only the left neighbours
- Vertical prediction: in this case only the upper neighbours are used
- Diagonal Left and Diagonal Right: linear combination of upper and left neighbours are used
Super Resolution creates a single image with two or more times the linear resolution e.g., the enhanced image will have twice the width and twice the height of the original image, or four times the total pixel count.
For each tool being investigated there are three phases: database building (of blocks of pixels, and subsampled and full-resolution pictures, respectively), learning phase and inference phase.
For the Intra prediction track, two training datasets have been built: one of 32×32 and 16×16 intra prediction blocks. A new EVC predictor, leveraging a CNN-based autoencoder is generated.
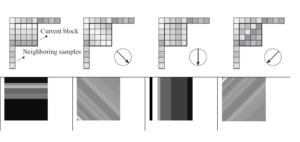
Figure 28 – Upper row: intra prediction examples (Horizontal, Diagonal right, Vertical, Diagonal Left); bottom row: some EVC intra predictors
In the training phase the autoencoder is trained on a dataset by minimizing the Means Square Error (MSE) between its output and the original image block. A communication channel based on a web socket between the EVC code (written in C language) and the autoencoder (written in python) is used to overcome the incompatibilities of different programming frameworks.
In the inference phase the autoencoder is fed with blocks neighbouring the block being predicted. In this way the problem becomes one of reconstructing the missing regions in an image. The encoder sends the 64-by-64 decoded neighbouring the block of each 32-by-32 Coding Unit (CU) and 16-by-16 CU to the autoencoder and returns the new 32-by-32 or 16-by-16 predictor, depending on the case, to the EVC encoder (Figure 29). The EVC codeword used to signal the EVC mode zero (DC) is replaced to signal the new AI-based prediction mode to the decoder.
The generated bitstream is fully decodable under the assumption that the autoencoder network is also available at the decoder side.
The next steps in this investigation include extending the proposed approach also to 8×8 and 4×4 CUs; experimenting with other network architectures than convolutional; changing the MSE during training, enlarging the context to 128-by-128 and replace all the EVC predictors with the autoencoder-generated predic-tor.
For the Super Resolution track a state-of-the-art neural network (Densely Residual Laplacian Super Resolution) was selected because it introduces a new type of architecture based on cascading over residual, which can assist in training deep networks.

Figure 29 – Left: current block, right: autoencoder generated predictor
A dataset to train the super resolution network has been selected and 3 resolutions (4k, HD, and SD), 4 values of picture quality, two coding tool sets (deblocking enabled, deblocking disabled) for a total of 170 GB dataset.
The super resolution step was added as a post processing tool. The picture before encoding with EVC baseline profile was downscaled and then the super resolution network was applied to the decoded picture to get the native resolution.
Many experiments have been performed to find the right procedure to select a region in the picture (crop), i.e., an objective metric to choose one or more crops inside the input picture in such a way that a trade-off between GPU memory and compression performance is achieved.
The next steps include experiments with other network architectures.
Additional tools considered for further experiments are:
-
in-loop filtering: reduce the blockiness effect by filtering out some high frequencies caused by coded blocks.
-
motion compensation: use Deep Learning architectures to improve the motion compensation.
-
inter prediction: estimate the motion using Deep Learning architectures to refine the quality of inter-predicted blocks; introduce new inter prediction mode to predict a frame avoiding the use of side information.
-
quantization: use a neural network-based quantization strategy to improve the uniform scalar quantization used in classical video coding because it does match the characteristics of the human visual system.
-
arithmetic encoder: use neural networks to better predict the probability distribution of coding modes.
19.2 End-to-end video coding
There is consensus in the video coding research community – and some papers make claims grounded on results – that so-called End-to-End (E2E) video coding schemes can yield significantly high performance. However, many issues need to be examined, e.g., how such schemes can be adapted to a standard-based codec. End-to-End Video Coding promises AI-based video coding standard with significantly higher performance in the longer term.
As a technical body unconstrained by IP legacy and with the mission to provide efficient and usable data coding standards, MPAI has initiated the End-to-End Video Coding (MPAI-EEV) project. This decision is an answer to the needs of the many who need not only environments where academic knowledge is promoted but also a body that develops common understanding, models and eventually standards-oriented End-to-End video coding.
Regarding the future research in this field, two major directions are envisioned to ensure that end-to-end video coding is general, robust and applicable. The compression efficiency has the highest priority and enhanced coding methods are expected to be proposed and incorporated into the reference model including high efficiency neural intra coding methods, neural predictive coding tools such as reference frame generation, dynamic inter-prediction structure, and long-term reference frames. The other aspect is the optimization techniques in end-to-end video coding, including neural rate control methods using reinforcement learning, imitation learning, parallel encoding framework, error concealment methods, and interface designation for the down-stream analysis tasks. Moreover, the high-level syntax as well as model-updating mechanism should also be considered in the future.
19.3 Server-based predictive multiplayer gaming
The general issues addressed by Server-based Predictive multiplayer Gaming (MPAI-SPG) are two of the problems affecting online video gaming. The basic idea is to record all behaviours of online games simulated by BOTs or played by humans, to create a large archive with an agent that can support the online game server in case of missing information (network problem) or alert it when a game situation does not resemble a usual game situation (cheating problem).
MPAI-SPG works by comparing the “atomic” unit of an online game, i.e., the game state and the data structure identifying the state of the whole system in a time unit. The agents will be the neural networks that learn to predict, using the data of the games that have taken place up to that moment. As depicted in the right-hand side of Figure 30, the online game server is a generic game engine composed of a unit that creates the game state (Game State Engine) and a set of simpler engines that deal with physics (Physics Engine), the management of inputs and the control of the different game entities (Behaviour Engine) and the game rules and events engine (Rules Engine). This model can be extended by adding other engines as required by the specific game.
MPAI-SPG is implemented by a neural network that interfaces to the game server, acting like a Digital Twin. The server passes the relative information of the current game state and the controller data of the clients that it has received up to that moment to MPAI-SPG. MPAI-SPG’s neural networks verify and calculate a predicted game state according to the information that has been received. Usually, the game state information generated by MPAI-SPG will be identical to the game server information. In case of missing packets and information, MPAI-SPG will act to fill the missing information according to all the behaviours recorded in situations like what is happening in the game system up to that moment; it will send its “proposal” to the Game State Engine which will use it to arrive at a decision.
In case of cheating, the game server will process a state that contains anomalies compared to the state predicted by MPAI-SPG. The detection of these anomalies will allow the game server to understand where the malicious information came from, generating a warning on the guilty client. It will then be up to the game state engine to manage this warning.
After defining the architecture and studying the final form that MPAI-SPG will take (a plug-in to be used within game engines), a prototype of Pong with an authoritative server has been developed. This is being used to test and build the first example of a MPAI-SPG. A neural network is being trained to respond to the needs of these scenarios and then define the standard that will enable external producers to develop their own solutions.
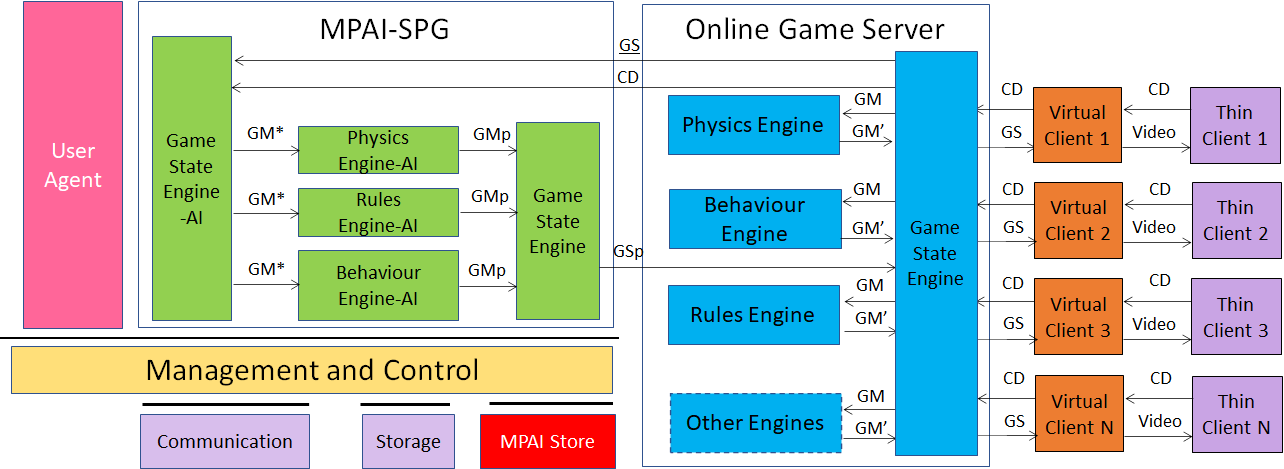
Figure 30 – Server-based Predictive Multiplayer Gaming Reference Model
19.4 Connected autonomous vehicles
Standardisation of Connected Autonomous Vehicles (CAV) components is required because of the different nature of the interacting technologies in a CAV, the sheer size of the future CAV market in the order of T$ p.a. and the need for users and regulators alike to be assured of CAV safety, reliability and explain-ability.
At this point in time, a traditional approach to standardisation might consider CAV standards as premature and some affected industries may not even be ready yet to consider them. CAVs, however, at best belong to an industry still being formed, that is expected to target the production of economic affordable units in the hundreds of millions p.a., with components to be produced by disparate sources. A competitive market of standard components can reduce costs and make CAV confirm their promise to have a major positive impact on environment and society.
Connected Autonomous Vehicles (MPAI-CAV) is an MPAI standard project that seeks to identify and define the CAV components target of standardisation. It is based on a reference model comprising the 5 Subsystems depicted in Figure 31, identifying components and their interfaces and specifying their requirements:
-
Human-CAV interaction (HCI) handles human-CAV interactions.
-
Environment Sensing Subsystem (ESS) acquires information from the Environment via a range of sensors.
-
Autonomous Motion Subsystem (AMS) issues commands to drive the CAV to the intended destination.
-
Motion Actuation Subsystem (MAS) provides environment information and receives/actuates motion commands in the environment.
The Figure depicts the 5 subsystems and their interactions.
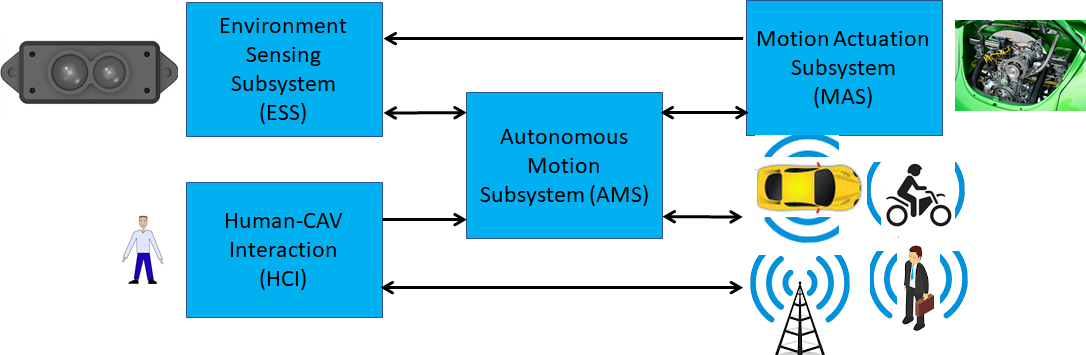
Figure 31 – The CAV subsystems
Human-CAV Interaction operates based on the principle that the CAV is impersonated by an avatar, selected, or produced by the CAV rights-holder. The visible features of the avatar are head face and torso, and the audible feature is speech embedding an emotion like it would be displayed by a human driver. This subsystem’s reference model reuses several of the AIMs already developed or being developed by MPAI in addition to a few that are CAV-specific.
The purpose of the Environment Sensing Subsystem, depicted in Figure 32, is to acquire all sorts of electromagnetic, acoustic, mechanical and other data directly from its sensors and other physical data of the Environment (e.g., temperature, pressure, humidity etc.) and of the CAV (Pose, Velocity, Acceleration) from Motion Actuation Subsystem. The main goal is to create the Basic World Representation, the best guess of the environment using the available data. This is achieved by:
- Acquiring available offline maps of the CAV current Pose:
- Fusing Visual, Lidar, Radar and Ultrasound data.
- Updating the Offline maps with static and moving objects, and all traffic signalisations.
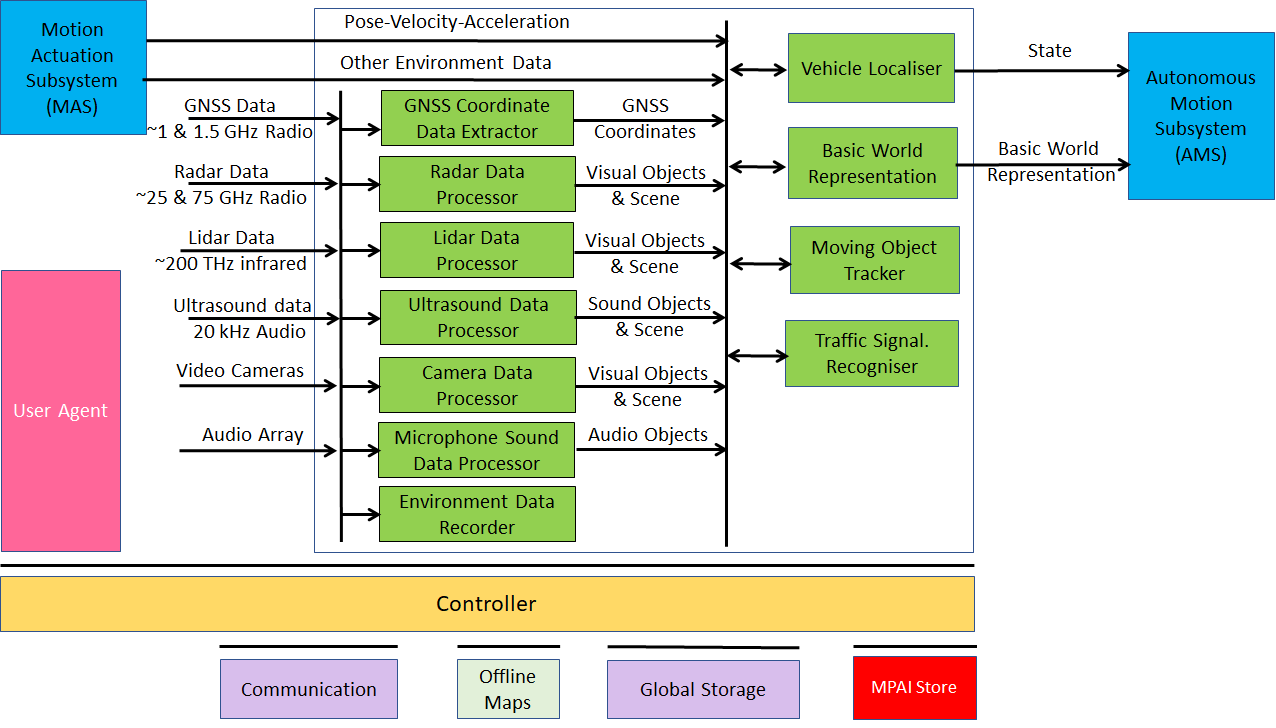
Figure 32 – Environment Sensing Subsystem Reference Model
A CAV exchanges information via radio with other entities, e.g., CAVs in range and other CAV-like communicating devices such as roadside units and Traffic Lights, thereby improving its Environment perception capabilities. Multicast mode is typically used for heavy data types (e.g., Basic World Representation). CAVs in range are important not just as sources of valuable information, but also because, by communicating with them, each CAV can minimise interference with other CAVs while pursuing its own goals.
The Autonomous Motion Subsystem is the core of the CAV operation.
-
Human-CAV Interaction requests Autonomous Motion Subsystem to plan and move the CAV to the human-selected Pose. Dialogue may follow.
-
Computes the Route satisfying the human’s request.
-
Receives the current Basic World Representation (BWR) from Environment Sensing Subsystem.
-
Transmits to and receives from other CAVs BWRs and fuses all BWRs to produces the Full World Representation (FWR).
-
Plans a Path connecting Poses.
-
Selects behaviour to reach intermediate Goals acting on information about the Goals other CAVs in range intend to reach.
-
Defines a trajectory, complying with traffic rules, preserving passenger comfort and refining the trajectory to avoid obstacles.
-
Sends Commands to the Motion Actuation Subsystem to take the CAV to the next Goal.
The Figure depicts the architecture of the Motion Actuation Subsystem.
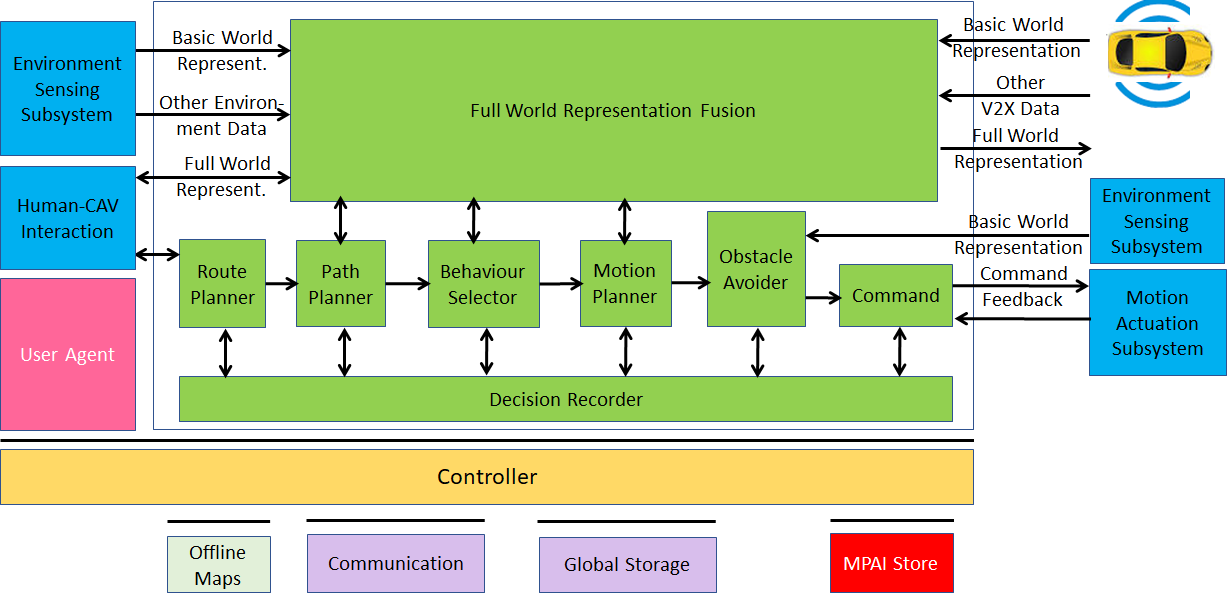
Figure 33 – Autonomous Motion Subsystem Reference Model
19.5 Conversation about a scene
In this standard project, a machine watches a human and the scene around it, hears what the human is saying, and gets the human’s emotional state and meaning via audio (speech) and video (face, and gesture).
The human talks to the machine about the objects in the scene indicating one with their hand/arm. The machine understands the object the Human points at by placing the direction of the Human hand/arm from the position occupied by the Human representation of the scene and is capable to make a pertinent response uttered via synthetic speech accompanied by its avatar face.
Figure 34 depicts the solution being investigated, its AIMs, the connections and the data exchanged. It is an extension of the Multimodal Question Answering use case where the machine creates an internal scene representation by using the Video Analysis3 AIM, spatially locates and recognises the objects in the scene, and combines gesture and scene descriptors to understand which object the Human is looking or pointing at.
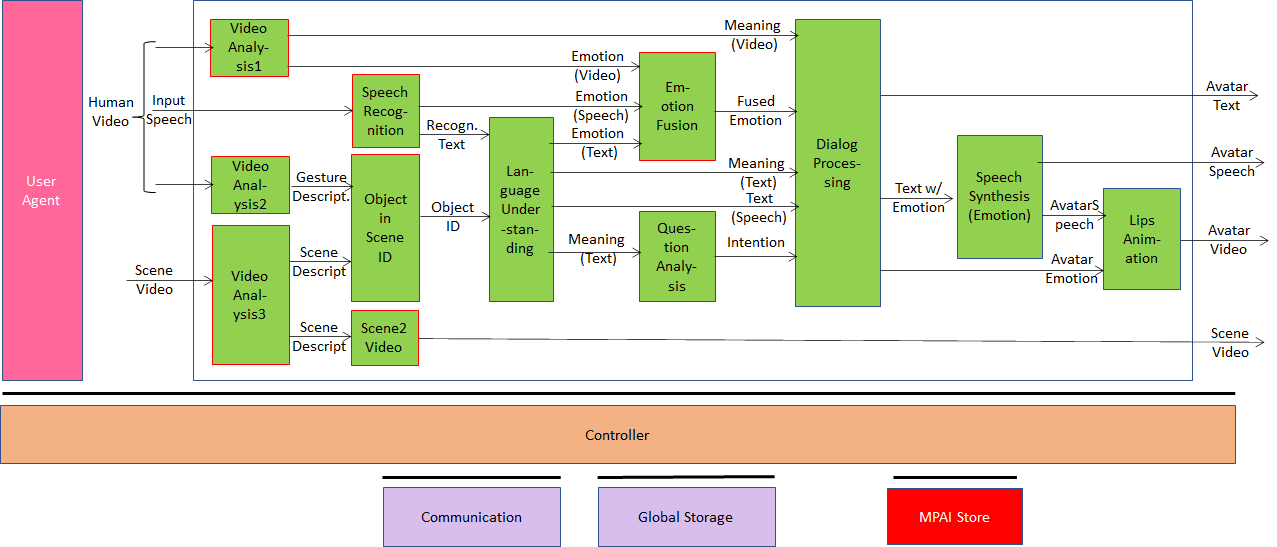
Figure 34 – Conversation about a scene
19.6 Mixed-reality collaborative spaces
Mixed-reality Collaborative Spaces (MPAI-MCS) is an MPAI standard project containing use cases, and functional requirements for AI Workflows, AI Modules, and Data Formats applicable to scenarios where geographically separated humans collaborate in real time by means of speaking avatars in virtual reality spaces called ambients to achieve goals generally defined by the use case and specifically carried out by humans and avatars.
Examples of applications target of the MPAI-MCS standard are:
-
Local Avatar Videoconference where realistic virtual twins (avatars) of physical twins (humans) sit around a table holding a conference. In this case, as many functions as practically possible should be clients because of security issues, e.g., participant identity and no clear text information sent to the server.
-
Virtual eLearning where there may be less concerns about identity and information transmitted to the server.
MCSs can be embodied in a variety of configurations. In two extreme configurations each MCS participant:
-
Creates the MCS in its own client using information generated by the client and received from other clients without necessarily relying on a server.
-
Generates media information and commands, and consumes information packaged by a server where the MCS is created, populated, and managed based on information received from clients.
In between these two extreme configurations, there is a variety of combinations where different splitting of functions between clients and servers are possible.
The Figure illustrates case #1 where most of the intelligence is concentrated in the transmission part of the client. We note Speech Separation, extracting speech from the participant’s location, participant identification via speech and face, extraction of participant’s emotion and meaning from speech, face and gesture and creation of avatar description.
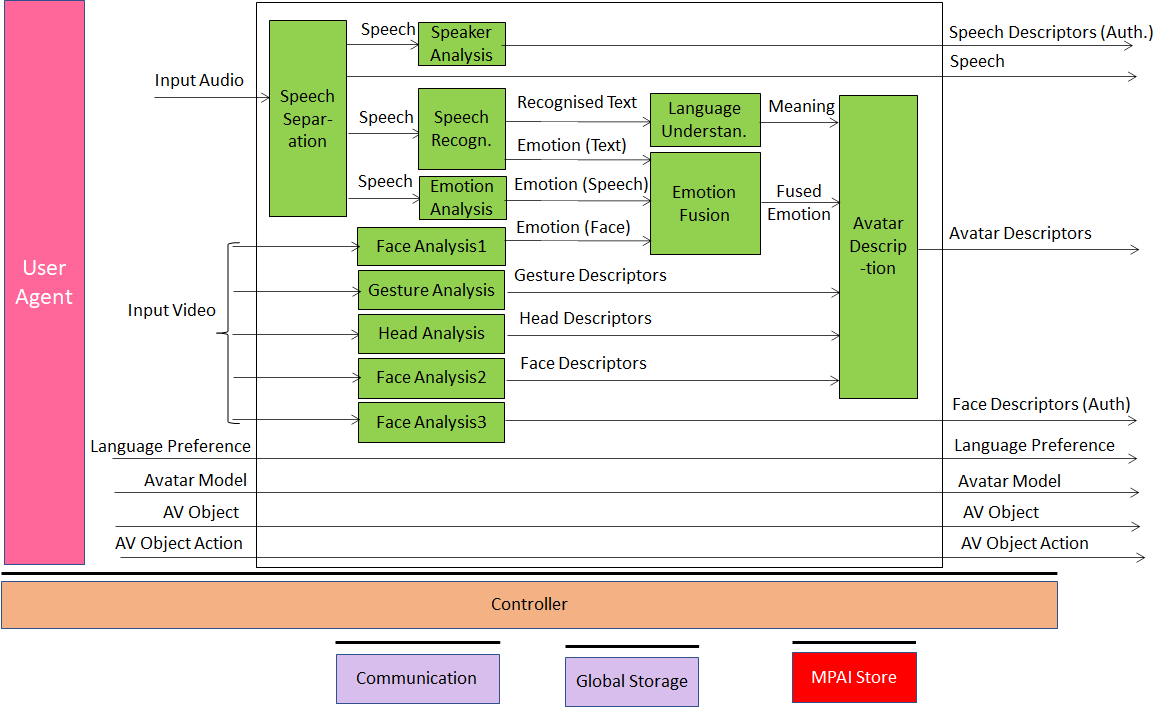
Figure 35 – Client-Based Ambient TX Client Reference Model
It is easy to see that a few AIMs can be reused from other MPAI standards. The server – not represented – contains a Translation AIM, again a derived from the MPAI-MMC standard and the participant identification.
19.7 Audio on the go
The Audio-On-the-Go (AOG) use case addresses the situation where musical content is consumed in a variety of different contexts: while biking in the traffic, at home with a dedicated stereo setup or in a car while driving.
The use case allows the reproduction of material to react dynamically to environmental conditions and perform a Dynamic Equalization based, at least initially, on a small set of environmental variables (such as time of the day or Ambient Noise) and adjust the playback to the specific hearing profile of the listener.
As an example, while biking in the traffic, the system receives as input the audio stream of the music playing app, performs an active equalization to compress the dynamic range of the stream (to allow user to experience an optimal sound despite the surrounding noise) then equalizes the stream again adapting to the user hearing profile. Eventually, it delivers the resulting sound to the headphones via Bluetooth.
Another example encompasses a home-listening situation, where a user listens a high-quality audio stream, the system performs an active equalization, accounting for the specific user hearing-profile, tailoring the listening experience to the specific listening abilities of the user.
All the above is obtained by chaining several AIMs: (1) the sound data stream is piped into a “Digital Audio Ingestion” AIM, which captures and normalizes the playback input signal and can be via standard signal processing tecniques; (2) the “Dynamic Signal Equalization” AIM uses an ML algorithm based on RNN that operates dynamically on a given number of bands to adapt dynamically the input signal to optimize the user audio experience and performs noise reduction and environment adaptation; (3) the “Delivery” AIM delivers the resulting stream to available and selected endpoints in the same network, automatically selecting the most suitable protocol.
| <–A renewed life for the patent system | Conclusions–> |