Video coding in MPAI
In the last 40 years, many efforts have been made to reduce the bitrate required to store and transmit a video signal of ever-growing quality in terms of resolution, dynamic range and colour. These results have been obtained using traditional data processing technologies. However, the advent of Artificial Intelligence (AI) technologies promises to reach even more ambitious targets.
Therefore, it should not be unexpected that one of the first MPAI activities has been the efficient representation of video information using AI technologies and that today MPAI has not one but two video coding groups. Both seek to improve compression: the first – called AI-Enhanced Video Coding (MPAI-EVC) – adds AI technologies to a traditional video compression scheme, and the second – called End-to-End Video Coding (MPAI-EEV) – seeks to optimise a fully AI-based scheme.
This MPAI Newsletter describes the activities of the two groups, their approaches, the results obtained so far, but is also a proof that the MPAI process of defining not just the functional, but also the commercial requirements before the start of the standardisation process is not just a nice idea but also one that can be implemented in practice.
It is important to note that MPAI opens the early phases of its projects – currently fully online – to non-members. If you wish to join one or both projects, please send an email to the MPAI Secretariat.
AI- Enhanced Video Coding – MPAI-EVC
Existing video coding standards rely on a clever combination of multiple encoding tools, each bringing its own contribution to the overall codec performance. The Enhanced Video Coding project (EVC) aims to leverage recent advances in the field of AI to replace or enhance specific video coding tools. The MPEG-5 EVC codec has been chosen as the starting point since its baseline profile includes only technologies dated from more than 20 years ago. So far, two tools have been investigated, namely the intra prediction and the super-resolution tools, as shown in the figure.
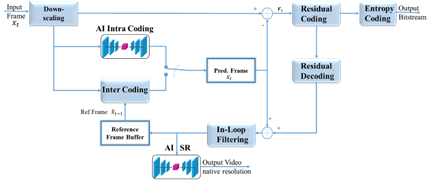
Traditional hybrid coding scheme with two AI tools.
The first tool investigated is the intra prediction tool integrated as a learnable “intra predictor” into the EVC encoder. The MPEG-5 EVC base profile offers 5 intra prediction modes: DC, horizontal, vertical and two diagonal modes. The problem of predicting a Coding Unit (CU) content from its context is addressed as an image inpainting problem, i.e., the recovery of image pixels that are unavailable such as occluded pixels. The learned predictor was implemented in the EVC baseline encoder by replacing the DC predictor with the learned predictor, thus ensuring that the bitstream stays decodable. Experiments over the standard JVET sequences show BD-Rate savings in excess of 10% and BD-PSNR improvements above 0.5 dB for some video sequences, and BD-Rate savings in excess of 5% and BD-PSNR improvements above 0.3 dB over the JVET classes from A to F. A visual inspection of the decoded sequences shows that the learned intra predictor causes no perceivable artefacts. Further gains would be possible if, rather than replacing the DC mode, the learned intra-predictor is put in competition with the other 5 modes. Moreover, the addition of smaller images and computer-generated pictures to the training set would boost the performance of these classes of content.
The second tool investigated is a super-resolution tool as a learned up-sampling filter outside the encoding loop. The Densely Residual Laplacian Network (DRLN) was selected among several state-of-the-art learning-based super-resolution approaches because it provided the best performance. The network was trained over a dataset where the initial 2000 4K images from the Kaggle dataset were resized to HD (1920×1080) and SD (960×540) resolutions. The training consisted in recovering the original full-resolution images. Tests were performed by first encoding the 4K sequences (Crowd Run, Ducks Take Off and Park Joy) over their down-sampled HD and SD counterparts, then by encoding the HD sequences (Rush Hour and four proprietary sequences Diego and the Owl, Rome 1, Rome 2 and Talk Show) over their SD counterparts. The decoded sequences were then up-sampled back to their original resolution and proper BD-Rate and BD-PSNR numbers were calculated. The results of the experiments showed an average BD-rate gain of -3.14% for the test sequences.
In conclusion:
- Good results have been obtained from the learnable intra-predictor and further gains can be expected when it is put into competition with the other 5 EVC intra predictors and if the network is trained to also account for contents below 720p and computer-generated pictures.
- The SR tool has shown good overall performance in BD-rate terms over the standard baseline EVC decoding for the SD to HD task. The model for the task HD to 4K is currently being trained and its preliminary results are also encouraging.
- More can obviously be gained from combining these two learnable tools
You are welcome to contact the MPAI-EVC group via the MPAI Secretariat and join the end-to-end video coding research and discussion. Any suggestions are appreciated.
More details on this activity can be found here.
End-to-End Video Coding – MPAI-EEV
AI-based End-to-End Video Coding (MPAI-EEV) is an MPAI project seeking to compress video by exploiting AI-based data coding technologies without the constraints of past applications of traditional data processing to video coding.
The overall flowchart of the MPAI-EEV scheme is depicted in the figure below. Videos to be compressed are sequentially partitioned into -frame fixed-length group-of-pictures (GOPs), and each GOP is individually compressed. Within each GOP, the first image is compressed using the existing high-performance image codec while the remaining frames are inter predictively encoded.
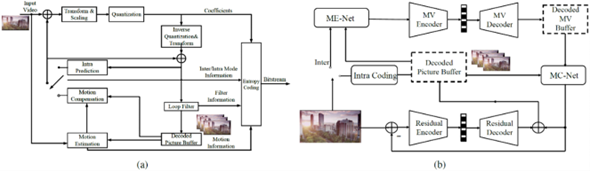
The block diagrams of two representative video compression paradigms, (a) conventional block-based hybrid compression framework; (b) end-to-end optimized neural video compression.
Intra Frame Coding. The very first image of each GOP is the intra-frame. An existing image coding intra-compression method is adopted. Specifically, the same settings as OpenDVC are maintained to utilize the widely accepted deep learning-based still image codec proposed in [1], where the loss function is the multiscale similarity structure (MS-SSIM).
Motion Estimation. The ME-Net generates the MV field, then the coarse prediction frame is obtained using the reference frame and encoded MV. Subsequently, the reference frame and the coarse prediction are concatenated and used as input to the Motion Compensation Net (MC-Net). This blended spatiotemporal information is jointly processed by an encoder-decoder structure with full convolution networks, leveraging the hierarchical feature fusion and adaptive aggregation of the rich contextual information. The design of the U-net convolutional neural network is adopted using a skip shortcut connection between the corresponding layers in the encoder and decoder of the MC-Net to guide the feature fusion. The ongoing work of the EEV group is to enhance the output of the MC-Net using a denoising network.
Motion Compensation. The coarse prediction frame can be obtained using the reference frame and encoded MV generated by the ME-Net. Subsequently, the reference frame and the coarse prediction are concatenated and used as input to the MC-Net. This spatial-temporal blended information is jointly processed by an encoder-decoder structure with fully convolution networks, leveraging the hierarchical feature fusion and adaptive aggregation of the rich contextual information. A design of the U-net structure is adopted using a skip shortcut connection between the corresponding layers in the encoder and decoder of the MC-Net to guide the feature fusion. The output of the MC-Net is then enhanced using a denoising network, which is the ongoing work of the EEV group.
MV and Residual Coding. As mentioned above, the MVs obtained in the ME process should be compressed and signaled to ensure that the encoder and decoder are aligned. MV is a two-channel tensor with the same spatial resolution as the input image. To make the entire framework end-to-end trainable, the existing learned codec [2] is adopted to compress the MVs. The MV encoding subnet is jointly optimized with other trainable components, as shown in the right-hand side of the figure.
Moreover, the prediction residual can be considered as an image and is encoded as such.
Current State of MPAI-EEV Software. The first version of the software is based on OpenDVC [2], and the official model and codebase have been open-sourced in GitLab. The next model version with enhanced motion compensation is under development.
You are welcome to contact the MPAI-EEV group via the MPAI Secretariat and join the end-to-end video coding research and discussion. Any suggestions are appreciated.
More details on the activity of this group can be found here.
[1] Jooyoung Lee, Seunghyun Cho, and Seung-Kwon Beack. Context-adaptive entropy model for end-to-end optimized image compression. arXiv preprint arXiv:1809.10452, 2018.
[2] Ren Yang, Luc Van Gool, and Radu Timofte. Opendvc: An open source implementation of the dvc video compression method. arXiv preprint arXiv:2006.15862, 2020.
MPAI releases four standards to the market
For standardisation veterans, the traditional standard development is mostly an exciting technical adventure going through the three steps of an idea that can be realised, call for the technologies required to achieve the goal, and assembly and optimization of technologies. In the background, the organisation makes sure that technology submitters promise to license them at fair and reasonable terms, and under non-discriminatory conditions (FRAND). When the standard is developed, some other technically rewarding activities are guaranteed to them while the market wrangles with the unenforceable promises made in FRAND declarations.
The MPAI process retains – actually, augments – the technical fun, but adds a “market responsibility” step: before a call is made for technologies satisfying the agreed technical requirements, MPAI Principal Members define a framework licence, i.e., a licence “without numbers”. Those proposing technologies in response to the call agree to licence the proposed technologies according to the framework licence.
When the standard is done, patent holders select a patent pool administrator.
Well, believe it or not, this process has been fully completed for four MPAI standards: AI Framework (MPAI-AIF), Context-Based Audio Enhancement (MPAI-CAE), Compression and Understanding of Industrial Data (MPAI-CUI) and Multimodal Conversation (MPAI-MMC).
Look here for more information.
Meetings in the coming May-June meeting cycle
| Group name | 23-27 May | 30 May -3 Jun |
6-10 Jun | 13-17 June | 20-24 June | Time (UTC) |
|||||||
| AI Framework | 23 | 30 | 6 | 13 | 20 | 15 | |||||||
| Governance of MPAI Ecosystem | 23 | 30 | 6 | 13 | 20 | 16 | |||||||
| Mixed-reality Collaborative Spaces | 23 | 30 | 6 | 13 | 20 | 17 | |||||||
| Multimodal Conversation | 24 | 31 | 7 | 14 | 21 | 14 | |||||||
| Neural Network Watermaking | 24 | 31 | 7 | 14 | 21 | 15 | |||||||
| Context-based Audio enhancement | 24 | 31 | 7 | 14 | 21 | 16 | |||||||
| Connected Autonomous Vehicles | 25 | 1 | 8 | 15 | 22 | 12 | |||||||
| AI-Enhanced Video Coding | 21 | 13 | |||||||||||
| 25 | 8 | 14 | |||||||||||
| AI-based End-to-End Video Coding | 1 | 15 | 14 | ||||||||||
| Avatar Representation and Animation | 26 | 2 | 9 | 16 | 13:30 | ||||||||
| Server-based Predictive Multiplayer Gaming | 26 | 2 | 9 | 16 | 14:30 | ||||||||
| Communication | 26 | 9 | 15 | ||||||||||
| Health | 27 | 17 | 14 | ||||||||||
| Industry and Standards | 3 | 17 | 16 | ||||||||||
| General Assembly 21 | 22 | 15 |