Highlights
- Why – if you are not already – you should become an MPAI member
- New standards in the making – Object and Scene Description
- Visiting MPAI standards – the Portable Avatar Format
- Meetings in the coming January meeting cycle
Why – if you are not already – you should become an MPAI member
In a world where technology changes your context overnight, how can you avoid being overwhelmed, stay in control, and exploit opportunities?
MPAI is the body that comes to your rescue:
- MPAI is about data, the fuel that keeps the engine of our society going.
- MPAI is about coding, the transformation that makes data exploitable.
- MPAI is about using Artificial Intelligence, the technology that is shaping our future.
- MPAI is about providing explainability, enabling humans to understand what machines do.
- MPAI is about making standards, the language for humans and machines to communicate.
- MPAI is about timeliness, twelve months from an idea to a standard.
- MPAI is about effectiveness, ten standards produced in three years.
- MPAI is about convergence, common technology serving many domains.
- MPAI is about collaboration, with other standards bodies such as the IEEE.
- MPAI is about ecosystem, supporting players from standards to products.
Join MPAI, share the fun, build the future!
With less than 500 € a year you can join MPAI, meet your peers, participate in the definition and development of MPAI standards.
With five times that you can participate in the definition of the strategic goals of MPAI.
Visit https://mpai.community/how-to-join/.
New standards in the making – Object and Scene Description
We perceive the objects in the world through our senses and we construct scenes by combining objects and the other way around. Object and scene recognition has been an active research field targeting the design of machines that understand and the creation of digital representation of objects and scenes. On the human side, research is still engaged in trying to discover how different parts of the brain cooperate in creating an understanding of a scene and its objects.
Most likely, many readers of this newsletter have assumed that “objects and scenes” were prefixed by the word “visual”. That, however, was not the intention. MPAI is interested in objects and scenes that are prefixed by the visual, by audio, and by audio-visual adjectives. MPAI is especially interested in the description of visual, audio, and audio-visual objects and scenes, because it is dealing with a variety of use cases that share the use of this technology.
A Connected Autonomous Vehicle has to create a rich description of the audio-visual scene around it to achieve its goal of autonomously reaching a destination. In the MPAI Connected Autonomous Vehicle (MPAI-CAV) – Architecture standard, the audio-visual scene and its object components may be produced by different technologies that share an entity called Basic Environment Representation (BER) based on an Object and Scene Description technology shared by different Environment Sensing Technologies (EST).
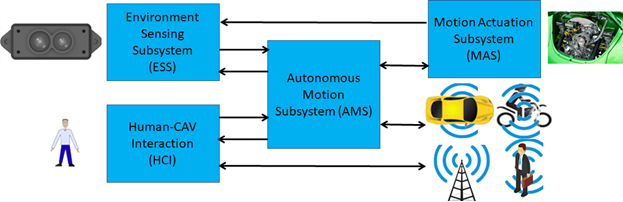
Figure 1 – Reference Model of Connected Autonomous Vehicle
The Environment Sensing Subsystem combines the Scene Descriptions from specific ESTs to produce the best BER achievable with the ESTs available in the CAV. The Autonomous Motion Subsystem exchanges pieces of its own BER with other CAVs within range, and obtains the Full Environment Representation (FER), the best digital representation of the Environment based on its own understanding and that of other collaborating CAVs.
It is possible for a CAV to develop the operation described above if there is a standard representation of the potentially complex audio-visual scenes around it.
In the Avatar-Based Videoconference (PAF-ABV) use case, humans send their avatar models to a server whose task is to select a meeting room, assign places to the avatars participating in the virtual meeting, and broadcast this information to all participating clients so that they can recreate the same 3D scene.
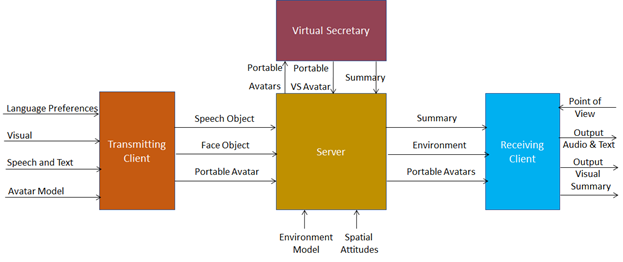
Figure 2 – Reference Model of the Avatar-Based Videoconference
While in the CAV – Architecture standard, the audio information plays a relatively important role, in the PAF-ABV use case, audio is vitally important for a proper user experience. Therefore, each client should “attach” the appropriate speech to the mouth of each avatar so that the speech has a direction perpendicular to the face of the avatar. Then, each avatar (i.e., each human driving it) can be in a sound field that is the sum of the speech signals from all avatar mouths and their reflections. When an avatar turns its face to the avatar it intends to speak to, and it will hear the correct mix of sounds.
In Version 2 of its Context-based Audio Enhancement (MPAI-CAE) standard, MPAI has developed an initial version of the Audio Scene Description (CAE-ASD) technology whose basic structure is composed by a series of Descriptors explained in the following.
- Header: CAE-ASD-x.y where x and y are the version and subversion (currently 2 and 1).
- ASDID: Identifier of a collection of individual ASDs describing a snapshot of the Scene and expressed by 16 byte UUID.
- Time: includes a bit defining the type of start time: for relative time, i.e., from an arbitrary 0 time and for absolute time, i.e., from 1970/01/01T00:00 (Unix time). It also includes a Start Time and End Time provided as microseconds from the start time and at end time, respectively, of the current Audio Scene Descriptors.
- Block Size: indicates the number of bytes comprising the current Audio Scene Descriptors.
- Audio Objects Count: represents the total number of Objects in the current Audio Scene Descriptors.
Finally, we have the set of audio data from each Audio Object:
- Audio Object Identifier
- Audio sampling frequency (from 8 to 192 kHz).
- Number of bits per sample (from 16 to 64 bits).
- Spatial Attitude.
- Data of the specific Audio Object.
Spatial Attitude is an entity specified by the Object and Scene Description (MPAI-OSD) standard. It is a data structure that includes:
- CoordType, for Cartesian and Spherical.
- ObjectType, for Digital Human and Generic Object.
- MediaType, signalling the Audio, Visual, Haptic, Smell, RADAR, LiDAR, and Ultrasound media types.
- Spatial Attitude Mask specifies the values of the last 3 sets of variables in the Spatial Attitude related to Cartesian or Spherical Position, and Orientation, and their velocities and acceleration.
The Audio Object field is agnostic of the data format used. It simply provides:
- Identifier of the Audio Object data format.
- Number of bytes used to represent the Audio Object.
- The Audio Object Data.
The MPAI-OSD standard has borrowed the main notions of CAE-ASD to develop the Visual and Audio-Visual Scene Descriptions (OSD-VSD and OSD-AVD, respectively).
Some elements of the two Scene Descriptions that are different, but the general structure is the same. For this reason, the MPAI Audio-Visual Scene Description is a general structure able to describe a Scene that is composed by an arbitrary number of Audio, Visual, and Audio-Visual Objects. Note that the scope of the MPAI-OSD standard is to specify Data Formats that enable the description and localisation of uni- and multi-modal Objects and Scenes in a Virtual Space for uniform use across MPAI Technical Specifications.
Both MPAI-OSD V1 and MPAI-CAE V2.1 are published with requests for comments. Anybody is invited to read the standards at the OSD and CAE web pages and provide comments by the 17th (OSD) and 23rd (for CAE) of January 2024.
Visiting MPAI standards – the Portable Avatar Format
The Portable Avatar Format (MPAI-PAF) standard,, published in early October, specifies:
- The Portable Avatar Format and related Data Types allowing a sender to enable a receiver to decode and render an Avatar as intended by the sender.
- The Personal Status Display Composite AI Module allowing the conversion of a Text and a Personal Status to a Portable Avatar.
- The AI Framework (MPAI-AIF)-conforming AI Workflows and AI Modules [4] composing the Avatar-Based Videoconference Use Case also using Data Types from other MPAI Technical Specifications.
Let’s analyse the first of the three scopes of the specification, namely, enabling a sender to communicate an avatar to a receiver with all surrounding information so that the receiver can use the avatar as intended by the sender.
The key point in the text above is in the words “use” and “intended”. We will explain it by describing the data types that compose the Portable Avatar Format (PAF).
- ID is the identifier of the Portable Avatar. This is used to enable the sender the reference a specific Avatar.
- Time type includes a bit defining the type of start of time: 0 for relative time, i.e., from an arbitrary 0 time and 1 for absolute time, i.e., from 1970/01/01T00:00 (Unix time).
- Start Time is the time from the start of the Portable Avatar. There is no End Time. When a new Portable Avatar with a new Start Time is received, the new Portable Avatar replaces the preceding one.
- Spatial Attitude is position and orientation (and possibly velocity and acceleration) in the Audio-Visual Scene Descriptors where the Avatar should be placed.
- Model is the Avatar Model.
- Body Descriptors and Face Descriptors enable the receiver to animate body and face of the Avatar Model as intended by the sender.
- Language preference is the language used by the avatar.
- Speech Type and Speech Object identify the speech compression algorithm and the actual Speech Object, respectively.
- Text is any text that may accompany the avatar.
- Personal Status is a data format specified by Multimodal Conversation (MPAI-MMC) V2. It contains a description of the (fictitious) Personal Status of the Avatar expressed by three data types: Cognitive State (how much the Avatar understands the context where it operates), Emotion, and Social Attitude (the positioning on the Avatar vis-à-vis the context).
There is much more that needs to be said about Personal Status. This will come in a future newsletter together with the other two scopes of the Portable Avatar Format.
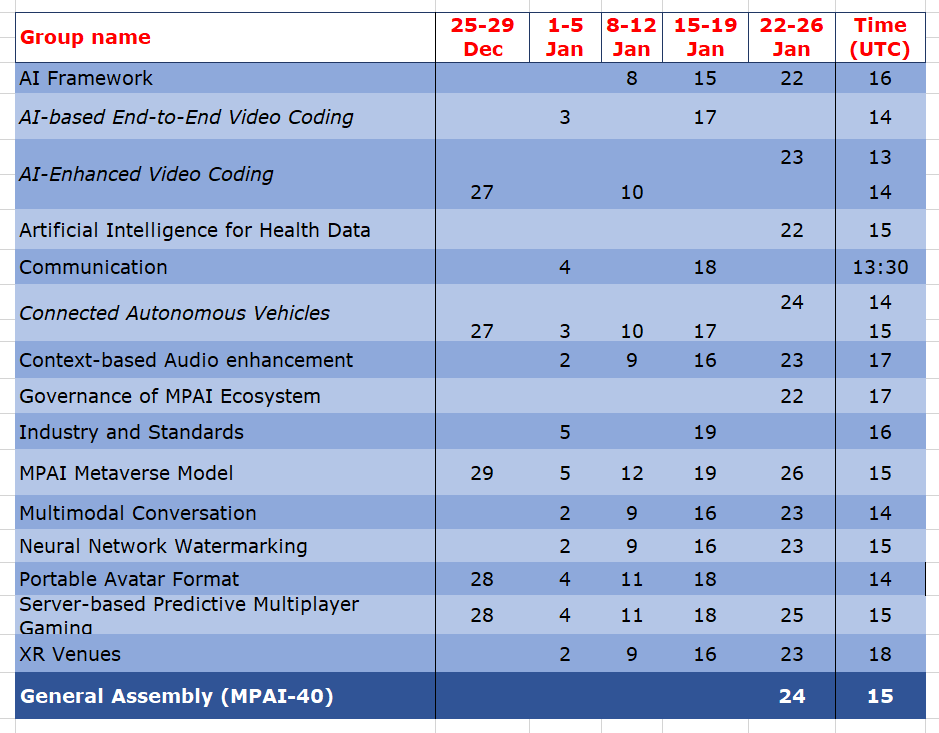
Meetings in the coming December-January meeting cycle
Participation in meetings indicated in normal font are open to MPAI members only. Legal entities and representatives of academic departments supporting the MPAI mission and able to contribute to the development of standards for the efficient use of data can become MPAI members.
Meetings in italic are open to non-members. If you wish to attend, send an email to secretariat@mpai.community.
This newsletter serves the purpose of keeping the expanding diverse MPAI community connected.
We are keen to hear from you, so don’t hesitate to give us your feedback.