<– Functionality Profiles Go to ToC ANNEX 2->
| General | AI Framework | Personal Status | Connected Autonomous Vehicles |
| Governance of the MPAI Ecosystem | Audio-Visual Scene Description | Human-Machine dialogue |
1 General
In recent years, Artificial Intelligence (AI) and related technologies have been introduced in a broad range of applications affecting the life of millions of people and are expected to do so much more in the future. As digital media standards have positively influenced industry and billions of people, so AI-based data coding standards are expected to have a similar positive impact. In addition, some AI technologies may carry inherent risks, e.g., in terms of bias toward some classes of users making the need for standardisation more important and urgent than ever.
The above considerations have prompted the establishment of the international, unaffiliated, not-for-profit Moving Picture, Audio and Data Coding by Artificial Intelligence (MPAI) organisation with the mission to develop AI-enabled data coding standards to enable the development of AI-based products, applications, and services.
As a rule, MPAI standards include four documents: Technical Specification, Reference Software Specifications, Conformance Testing Specifications, and Performance Assessment Specifications.
The last – and new in standardisation – type of Specification includes standard operating procedures that enable users of MPAI Implementations to make informed decision about their applicability based on the notion of Performance, defined as a set of attributes characterising a reliable and trustworthy implementation.
2 Governance of the MPAI Ecosystem
The technical foundations of the MPAI Ecosystem are currently provided by the following documents developed and maintained by MPAI:
- Technical Specification.
- Reference Software Specification.
- Conformance Testing.
- Performance Assessment.
- Technical Report
An MPAI Standard is a collection of a variable number of the 5 document types.
Figure 4 depicts the MPAI ecosystem operation for conforming MPAI implementations.
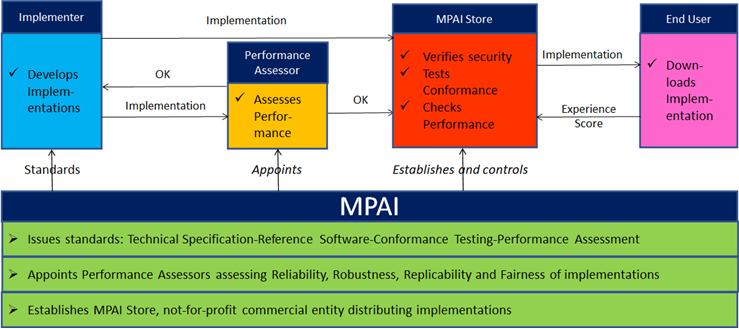
Figure 4 – The MPAI ecosystem operation
Technical Specification: Governance of the MPAI Ecosystem [1] identifies the following roles in the MPAI Ecosystem:
Table 31 – Roles in the MPAI Ecosystem
| MPAI | Publishes Standards.
Establishes the not-for-profit MPAI Store. Appoints Performance Assessors. |
| Implementers | Submit Implementations to Performance Assessors. |
| Performance Assessors | Inform Implementation submitters and the MPAI Store if Implementation Performance is acceptable. |
| Implementers | Submit Implementations to the MPAI Store. |
| MPAI Store | Assign unique ImplementerIDs (IID) to Implementers in its capacity as ImplementerID Registration Authority (IIDRA)[1].
Verifies security and Tests Implementation Conformance. |
| Users | Download Implementations and report their experience to MPAI. |
3 AI Framework
In general, MPAI Application Standards are defined as aggregations – called AI Workflows (AIW) – of processing elements – called AI Modules (AIM) – executed in an AI Framework (AIF). MPAI defines Interoperability as the ability to replace an AIW or an AIM Implementation with a functionally equivalent Implementation.
Figure 5 depicts the MPAI-AIF Reference Model under which Implementations of MPAI Application Standards and user-defined MPAI-AIF Conforming applications operate [5].
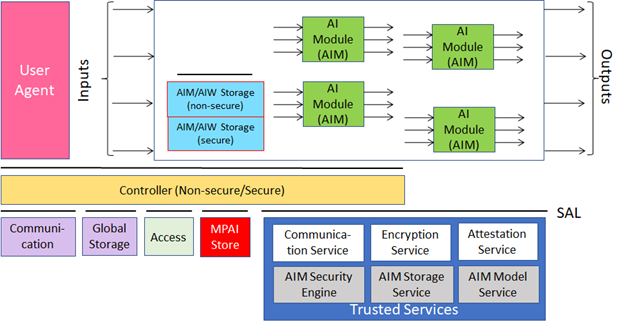
Figure 5 – The AI Framework (AIF) Reference Model
MPAI Application Standards normatively specify the Syntax and Semantics of the input and output data and the Function of the AIW and the AIMs, and the Connections between and among the AIMs of an AIW.
An AIW is defined by its Function and input/output Data and by its AIM topology. Likewise, an AIM is defined by its Function and input/output Data. MPAI standard are silent on the technology used to implement the AIM which may be based on AI or data processing, and implemented in software, hardware or hybrid software and hardware technologies.
MPAI also defines 3 Interoperability Levels of an AIF that executes an AIW. The AIW and its AIMs may have 3 Levels:
Table 32 – MPAI Interoperability Levels
| Level | AIW | AIMs |
| 1 | An implementation of a use case | Implementations able to call the MPAI-AIF APIs. |
| 2 | An Implementation of an MPAI Use Case | Implementations of the MPAI Use Case |
| 3 | An Implementation of an MPAI Use Case certified by a Performance Assessor | Implementations of the MPAI Use Case certified by Performance Assessors |
4 Audio-Visual Scene Description
The ability to describe (i.e., digitally represent) an audio-visual scene is a key requirement of several MPAI Technical Specifications and Use Cases. MPAI has developed Technical Specification: Context-based Audio Enhancement (MPAI-CAE) [6] that includes Audio Scene Descriptors and uses a subset of Graphics Language Transmission Format (glTF) [12] to describe a visual scene.
4.1 Audio Scene Descriptors
Audio Scene Description is a Composite AI Module (AIM) specified by Technical Specification: Context-based Audio Enhancement (MPAI-CAE) [6]. The position of an Audio Object is defined by Azimuth, Elevation, Distance, and Distance Flag.
The Audio Scene Description Composite AIM and its AIMs are depicted in Figure 12.
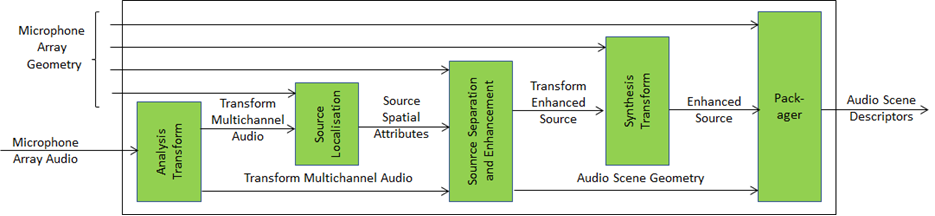
Figure 6 – The Audio Scene Description Composite AIM
5 Personal Status
5.1 General
Personal Status is the set of internal characteristics of a human and a machine making a conversation. Technical Specification: Multimodal Conversation (MPAI-MMC) [8] identifies three Factors of the internal state:
- Cognitive State is a typically rational result from the interaction of a human/avatar with the Environment (e.g., “Confused”, “Dubious”, “Convinced”).
- Emotion is typically a less rational result from the interaction of a human/avatar with the Environment (e.g., “Angry”, “Sad”, “Determined”).
- Social Attitude is the stance taken by a human/avatar who has an Emotional and a Cognitive State (e.g., “Respectful”, “Confrontational”, “Soothing”).
The Personal Status of a human can be displayed in one of the following Modalities: Text, Speech, Face, or Gesture. More Modalities are possible, e.g., the body itself as in body language, dance, song, etc. The Personal Status may be shown only by one of the four Modalities or by two, three or all four simultaneously.
5.2 Personal Status Extraction
Personal Status Extraction (PSE) is a composite AIM that analyses the Personal Status conveyed by Text, Speech, Face, and Gesture – of a human or an avatar – and provides an estimate of the Personal Status in three steps:
- Data Capture (e.g., characters and words, a digitised speech segment, the digital video containing the hand of a person, etc.).
- Descriptor Extraction (e.g., pitch and intonation of the speech segment, thumb of the hand raised, the right eye winking, etc.).
- Personal Status Interpretation (i.e., at least one of Emotion, Cognitive State, and Attitude).
Figure 7 depicts the Personal Status estimation process:
- Descriptors are extracted from Text, Speech, Face Object, and Body Object. Depending on the value of Selection, Descriptors can be provided by an AIM upstream.
- Descriptors are interpreted and the specific indicators of the Personal Status in the Text, Speech, Face, and Gesture Modalities are derived.
- Personal Status is obtained by combining the estimates of different Modalities of the Personal Status.
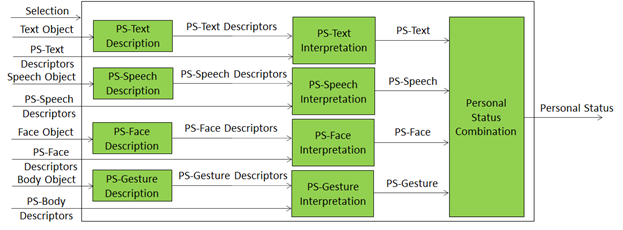
Figure 7 – Reference Model of Personal Status Extraction
An implementation can combine, e.g., the PS-Gesture Description and PS-Gesture Interpretation AIMs into one AIM, and directly provide PS-Gesture from a Body Object without exposing PS-Gesture Descriptors.
5.3 Personal Status Display
A Personal Status Display (PSD) is a Composite AIM receiving Text and Personal Status and generating an avatar producing Text and uttering Speech with the intended Personal Status while the avatar’s Face and Gesture show the intended Personal Status. Instead of a ready-to-render avatar, the output can be provided as Compressed Avatar Descriptors. The Personal Status driving the avatar can be extracted from a human or can be synthetically generated by a machine as a result of its conversation with a human or another avatar. Reference Architecture.
Figure 8 represents the AIMs required to implement Personal Status Display.
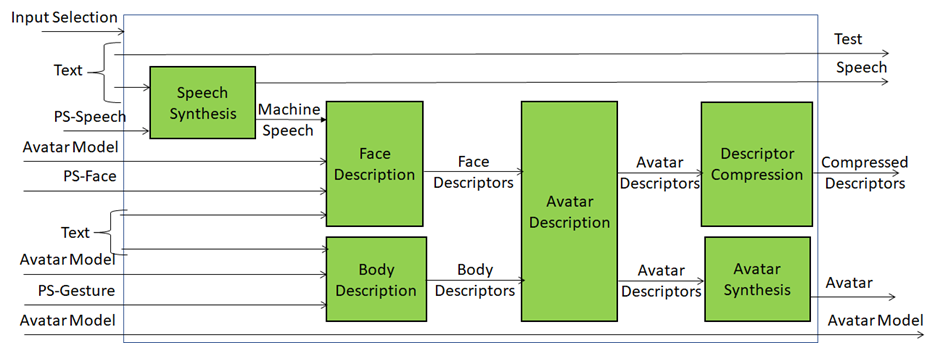
Figure 8 – Reference Model of Personal Status Display
The Personal Status Display operates as follows:
- Selection determines the type of avatar output – ready-to-render avatar or compressed avatar descriptors.
- Text is passed as output and synthesised as Speech using the Personal Status provided by PS (Speech).
- Machine Speech and PS (Face) are used to produce the Face Descriptors.
- PS (Gesture) and Text are used for Body Descriptors using the Avatar Model.
- Avatar Description produces a complete set of Avatar Descriptors.
- Descriptor Compression produces Compressed Avatar Descriptors.
- Avatar Synthesis produces a ready-to-render Avatar.
6 Human-Machine dialogue
Figure 9 depicts the model of the MPAI Personal-Status-based human-machine dialogue.
Audio Scene Description and Visual Scene Description are two front-end AIMs. The former produces 1) Physical Objects, Face and Body Descriptors of the humans, and Visual Scene Geometry; the latter produces Audio Objects and Audio Scene Geometry.
Body Descriptors, Physical Objects and Visual Scene Geometry are used by the Spatial Object Identification AIM. This provides the identifier of the Physical Object the human body is indicating by using the Body Descriptors and the Scene Geometry. The Speech extracted from the Audio Scene Descriptor is recognised and passed to the Language Understanding AIM together with the Physical Object ID. The AIM provided a refined text (Text (Language Understanding)) and Meaning (semantic, syntactic, and structural information extracted from input data).
Face and Body Descriptors, Meaning and Speech are used by Personal Status Extraction to extract the Personal Status of the human. Dialogue Processing produces a textual response with an associated machine Personal Status that is congruent with the input Text (Language Understanding) and human Personal Status. The Personal Status Display AIM produces a synthetic Speech and an avatar representing the machine.
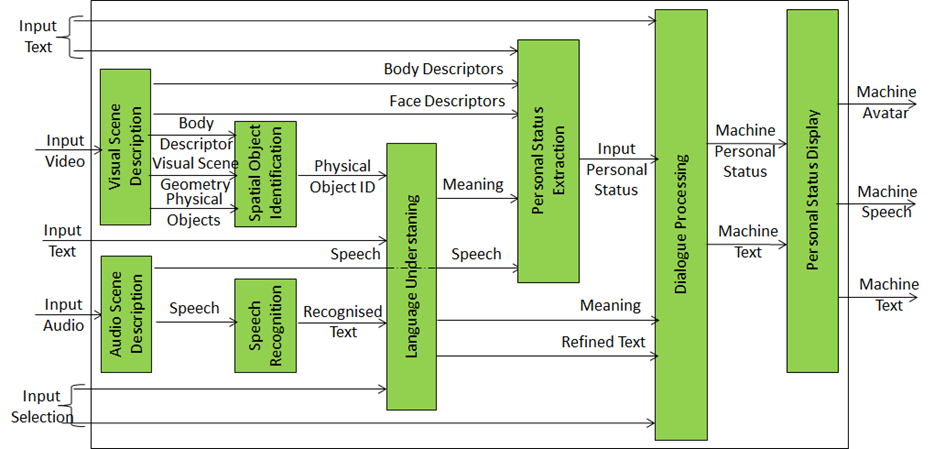
Figure 9 – Personal Status-based Human-Machine dialogue
7 Connected Autonomous Vehicles
MPAI defines a Connected Autonomous Vehicle (CAV), as a physical system that:
- Converses with humans by understanding their utterances, e.g., a request to be taken to a destination.
- Acquires information with a variety of sensors on the physical environment where it is located or traverses like the one depicted in Figure 10.
- Plans a Route enabling the CAV to reach the requested destination.
- Autonomously reaches the destination by:
- Moving in the physical environment.
- Building Digital Representations of the Environment.
- Exchanging elements of such Representations with other CAVs and CAV-aware entities.
- Making decisions about how to execute the Route.
- Acting on the CAV motion actuation to implement the decisions.
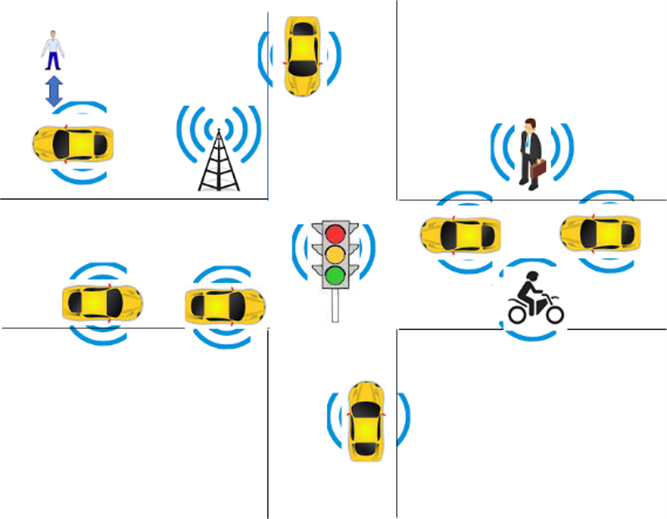 |
 |
| Figure 10 – An environment of CAV operation | Figure 11 – The MPAI-CAV subsystems |
MPAI believes in the capability of standards to accelerate the creation of a global competitive CAV market and has published Technical Specification:f Connected Autonomous Vehicle (MPAI-CAV) – Architecture that includes (see Figure 11):
- A CAV Reference Model broken down into four Subsystems.
- The Functions of each Subsystem.
- The Data exchanged between Subsystems.
- A breakdown of each Subsystem in Components of which the following is specified:
- The Functions of the Components.
- The Data exchanged between Components.
- The Topology of Components and their Connections.
- Subsequently, Functional Requirements of the Data exchanged.
- Eventually, standard technologies for the Data exchanged.
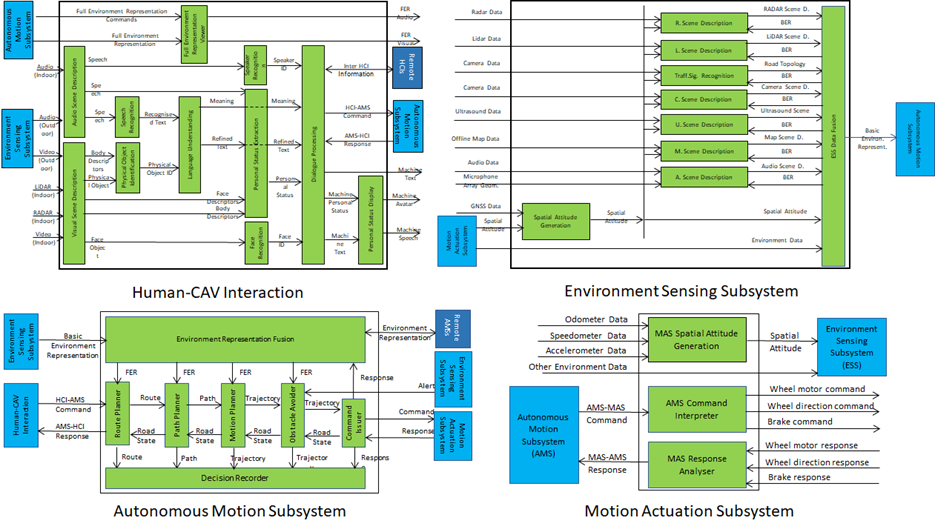
Figure 12 – The MPAI-CAV Subsystems with their Components
Subsystems are implemented as AI Workflows and Components as AI Modules according to Technical Specification: AI Framework (MPAI-AIF) [5].
The Processes of a CAV generate a persistent M-Instance resulting from the integration of:
- The Environment Representation generated by the Environment Sensing Subsystem by UM-Capturing the U-Location being traversed by the CAV.
- The M-Locations of the M-Instances produced by other CAVs in range CAV that reproduce the U-Locations being traversed by such CAVs to improve the accuracy of the Ego CAV’s M-Locations.
- Relevant Experiences of the Autonomous Motion Subsystem at the M-Location.
Some operations of an implementation of MPAI-CAV can be represented according to the MPAI-MMM – Architecture [9] as shown in Section 11.11 Drive a Connected Autonomous Vehicle.
[1] At the time of publication of this Technical Report, the MPAI Store was assigned as the IIDRA.
<– Functionality Profiles Go to ToC ANNEX 2->