1 Version
V2.1
2 Functions
Multimodal Question Answering (MMC-MQA):
- Receives
- Selector – communicating use of Text or Speech.
- Input Text – replacing Speech, where appropriate.
- Input Visual – the object for which a question is asked
- Input Speech – the question asked.
- Produces Text or Speech conveying the answer.
3 Reference Module
Figure 1 depicts the Reference Module of the Multimodal Question Answering AIW.
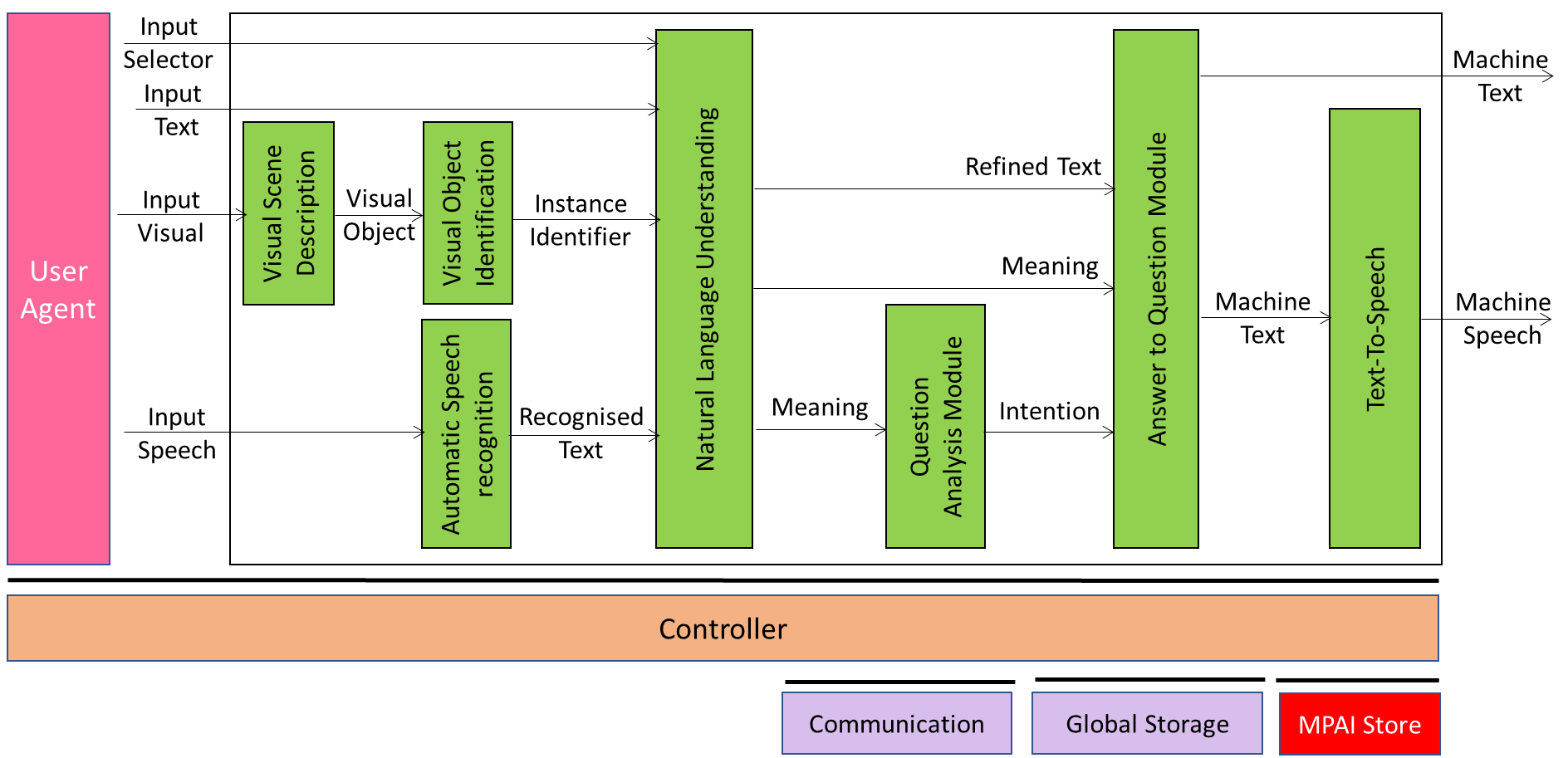
Figure 1 – The Multimodal Question Answering AIW
4 I/O Data
Table 1 specifies the Input and Output Data of the Multimodal Question Answering AIW.
Table 1 – I/O Data of Multimodal Question Answering
| Input | Descriptions |
| Input Text | Text typed by the human as a replacement for Input Speech. |
| Input Selector | Data determining the use of Speech or Text. |
| Input Visual | Video of the human showing an object held in hand. |
| Input Speech | Speech of the human asking a question the Machine. |
| Output | Descriptions |
| Machine Text | The Text generated by Machine in response to human input. |
| Machine Speech | The Speech generated by Machine in response to human input. |
5 SubAIMs
| Visual Scene Description |
| Visual Object Identification |
| Automatic Speech Recognition |
| Natural Language Understanding |
| Question Analysis Module |
| Answer to Question Module Answering |
| Text-to-Speech |
6 JSON Metadata
https://schemas.mpai.community/MMC/V2.1/AIMs/MultimodalQuestionAnswering.json