1 Version
V2.1
2 Functions
Speech Restoration System restore a Damaged Segment of an Audio Segment containing only speech from a single speaker. The damage may affect the entire segment, or only part of it.
The Restoration process replaces the damaged vocal elements with synthesised vocal elements using a speech model.
If the damage affects the entire segment, an entirely new segment is synthesised; if only parts are affected, corresponding segments will be synthesised individually to enable later integration into the undamaged parts of the Damaged Segment, with reference to appropriate Time Labels.
The speech segments necessary for the creation of the speech model can be resourced from undamaged parts of the input segment or from other recording sources that are consistent with the original segment’s acoustic environment.
3 Reference Model
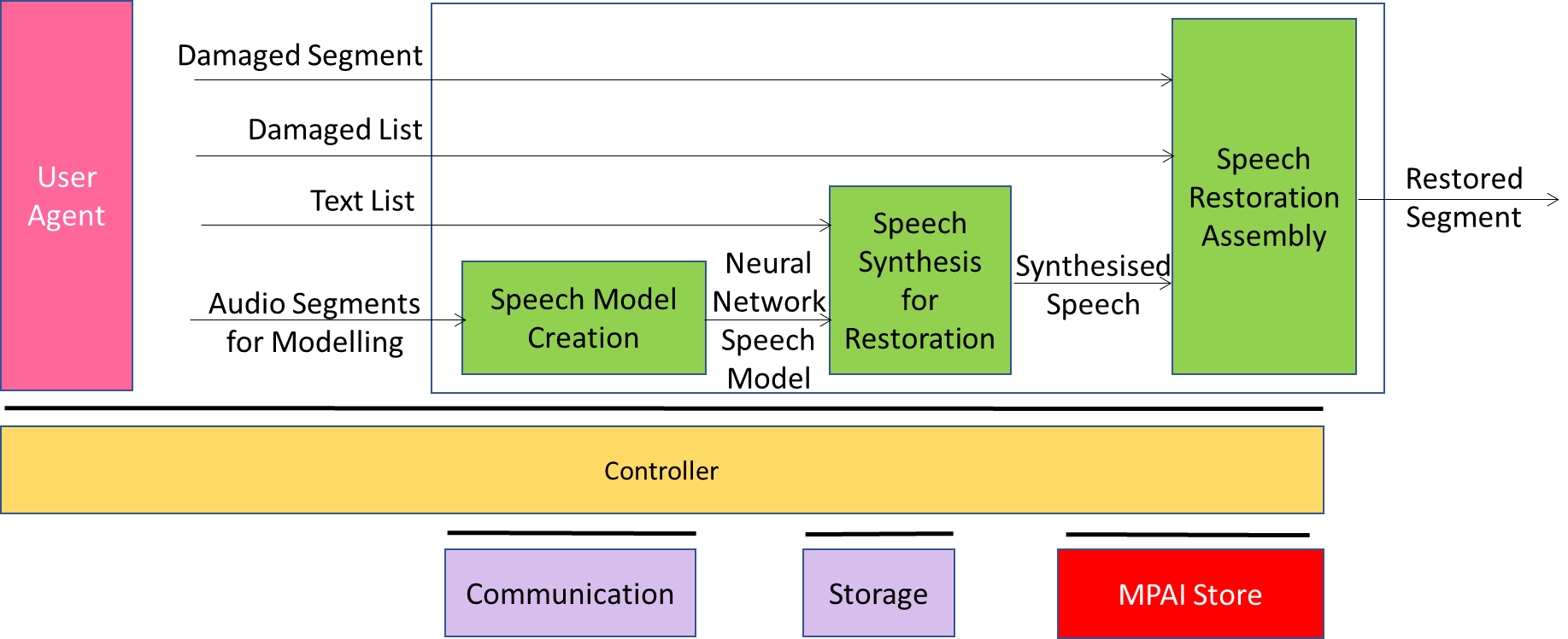
Figure 1 – Speech Restoration System (CAE-SRS) AIW
The description of the Reference Model operation unfolds as follows:
- Speech Model Creation receives Audio Segments for Modelling, a set of recordings composing a corpus that will be used to train a Neural Network Speech Model in Speech Model Creation.
- That Neural Network Speech Model is passed to the Speech Synthesis for Restoration AIM, which also receives a Text List as input. Each element of Text List is a string specifying the text of a damaged section of Damaged Segment (or of Damaged Segment as a whole). Speech Synthesis for Restoration produces synthetic replacements for each damaged section (or for Damaged Segment as a whole) and passes the replacement(s) to Speech Restoration Assembly.
- Speech Restoration Assembly receives as input the entire Damaged Segment, plus Damaged List, a list indicating the locations of any damaged sections within Damaged Segment. The list will be null if Damaged Segment in its entirety was replaced.
- Speech Restoration Assembly produces as output Restored Segment, in which any repaired sections have been replaced by synthetic sections, or in which the entire Damaged Segment has been replaced.
4 Input/Output Data
Table 1 – Input/Output Data of CAE-SRS AIW
| Input | Comments |
| Speech Segments for Modelling | A set of Audio Files containing speech segments used to train the Neural Network Speech Model. |
| Text List | |
| Damaged List | A list of strings of Texts corresponding to the Damaged Segments (if any) requiring replacement with synthetic segments. |
| Damaged Segment | An Audio Segment containing only speech (and not containing music or other sounds) which is either damaged in its entirety or contains one or more Damaged Sections specified in the Damaged List. |
| Output data | Comments |
| Restored Segment |
5 SubAIMs
The AIMs required by the Speech Restoration System AIW are described in Table 1
Table 11 – AI Modules of of CAE-SRS AIW
| AIW | AIMs | Name | JSON |
| CAE-SRS | Speech Restoration System | ||
| CAE-SMC | Speech Model Creation | X | |
| CAE-SSR | Speech Synthesis for Restoration | X | |
| CAE-SRA | Speech Restoration Assembly | X |
6 JSON Metadata
https://schemas.mpai.community/CAE/V2.1/AIWs/SpeechRestorationSystem.json