6 AIW, AIMs, and JSON Metadata
1 Functions
The Enhanced Audioconference Experience Use Case addresses the situation where one or more speakers are active in a noisy meeting room and are trying to communicate with one or more interlocutors using speech over a network. In this situation, the user experience is very often far from satisfactory due to multiple competing speakers, non-ideal acoustical properties of the physical spaces that the speakers occupy and/or background noise. These can lead to a reduction in intelligibility of speech resulting in participants not fully understanding what their interlocutors are saying, in addition to creating a distraction and eventually leading to what is known as audioconference fatigue. When microphone arrays are used to capture the speakers, most of the described problems can be resolved by appropriate processing of the captured signals. The speech signals from multiple speakers can be separated from each other, the non-ideal acoustics of the space can be reduced, and any background noise can be substantially suppressed.
CAE-EAE is concerned with extracting from microphone array recordings the speech signals from individual speakers as well as reducing the background noise and the reverberation that reduce speech intelligibility. CAE-EAE also extracts the Spatial Attitudes of the speakers with respect to the position of the microphone array to facilitate the spatial representation of the speech signals at the receiver side if necessary. These Spatial Attitudes are represented in the Audio Scene Geometry format and packaged in a format that is amenable to further processing for efficient delivery and further processing. Data reduction of the extracted speech signals as well as their reconstruction/representation at the receiver side are outside the scope of this Use Case.
CAE-EAE aims to provide a complete solution to process speech signals recorded by microphone arrays to provide clear speech signals substantially free from background noise and acoustics-related artefacts to improve the auditory quality of audioconference experience. Thus, CAE-EAE improves auditory experience in an audioconference, thereby reducing the effects of audioconference fatigue.
2 Reference Architecture
Figure 1 shows the Reference Model for the CAE-EAE.
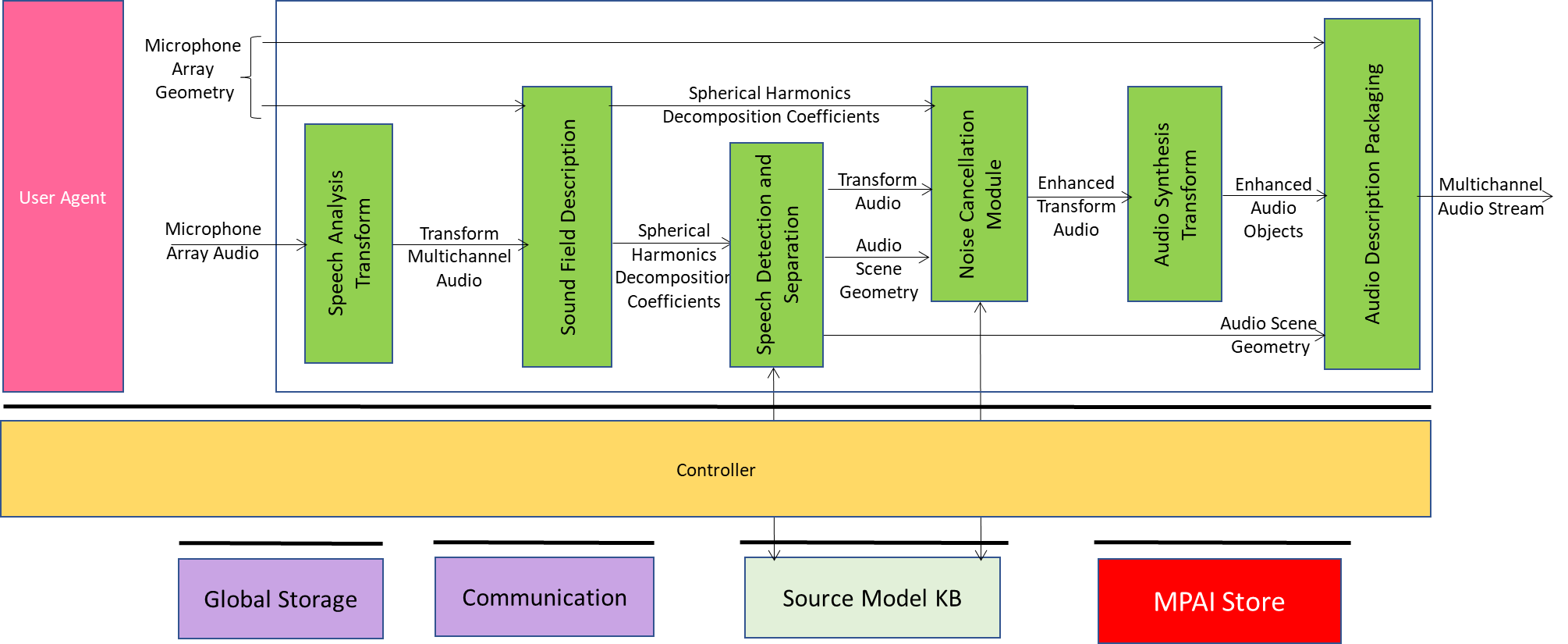
Figure 1 – Enhanced Audioconference Experience Reference Model
3 I/O data of AI Workflow
Table 1 shows the input and output data for the Enhanced Audioconference Experience workflow.
Table 14 – I/O data of Enhanced Audioconference Experience
| Inputs | Comments |
| Microphone Array Geometry | A Data Type representing the position of each microphone comprising a Microphone Array and specific characteristics such as microphone type, look directions, and the array type. |
| Microphone Array Audio | A Data Type whose structure contains between 4 and 256 time-aligned interleaved Audio Channels organised in blocks. |
| Outputs | Comments |
| Multichannel Audio Stream | Interleaved Multichannel Audio packaged with Time Code as specified in Multichannel Audio Stream. |
The Enhanced Audio Experience AIW:
- Receives:
- Microphone Array Geometry which describes the number, positioning, and configuration of the microphone(s). Using this information, the system can detect the relative directions of the active speakers according to the microphone array and separate relevant audioconference speech sources from each other and from other spurious sounds. Since audio conferencing is a real-time application scenario, the use case operates on Audio Blocks.
- Microphone Array Audio which is input to EAE as short Multichannel Audio Blocks comprising real valued time domain audio samples where the number of audio samples in each Audio Block is the same for all the microphones.
- Produces Multichannel Audio Stream.
4 Functions of AI Modules
The AIMs required by the Enhanced Audioconference Experience are given in Table 2.
Table 2 – AIMs of Enhanced Audioconference Experience
| AIM | Function |
| Audio Analysis Transform | Represents the input Multichannel Audio in a new form amenable to further processing by the subsequent AIMs in the architecture. |
| Sound Field Description | Produces Spherical Harmonic Decomposition Coefficients of the Transformed Multichannel Audio. |
| Speech Detection and Separation | Separates speech and non-speech signals in the Spherical Harmonic Decomposition producing Transform Speech and Audio Scene Geometry. |
| Noise Cancellation Module | Removes noise and/or suppresses reverberation in the Transform Speech producing Enhanced Transform Audio. |
| Audio Synthesis Transform | Effects inverse transform of Enhanced Transform Audio producing Enhanced Audio Objects ready for packaging. |
| Audio Description Packaging | Multiplexes Enhanced Audio Objects and the Audio Scene Geometry. |
The EAE use case receives Microphone Array Audio and Microphone Array Geometry which describes the number, positioning, and configuration of the microphone(s). Using this information, the system can detect the relative directions of the active speakers according to the microphone array and separate relevant audioconference speech sources from each other and from other spurious sounds. Since audio conferencing is a real-time application scenario, the use case operates on Audio Blocks.
The Multichannel Audio is input to EAE as short Multichannel Audio Blocks comprising real valued time domain audio samples where the number of audio samples in each audio block is the same for all the microphones.
The sequence of operations of the EAE use case is the following:
5 I/O Data of AI Modules
- Audio Analysis Transform transforms the Microphone Array Audio into frequency bands via a Fast Fourier Transform (FFT). The following operations are carried out in discrete frequency bands. When such a configuration is used a 50% overlap between subsequent audio blocks needs to be employed. The output is a data structure comprising complex valued audio samples in the frequency domain.
- Sound Field Description converts the output from the Speech Analysis Transform AIM into the spherical frequency domain [26]. If the microphone array used in capturing the scene is a spherical microphone array, Spherical Fourier Transform (SFT) can be used to obtain the Spherical Harmonic Decomposition (SHD) coefficients that represent the captured sound field in the spatial frequency domain. For other types of arrays, more elaborate processing might be necessary. The output of this AIM is (M × (N+1)2) complex valued data frame comprising the SHD coefficients up to an order which depends on the number of individual microphones in the array.
- Speech Detection and Separation receives the SHD coefficients of the sound field to detect directions of active sound sources and to separate them. Each separated source can either be a speech or a non-speech signal. Speech detection is carried out on an Audio Block basis by using on each separated source an appropriate voice activity detector (VAD) that is a part of this AIM. This AIM will output speech as an (M × S) Audio Block comprising transform domain speech signals and block-by-block Audio Scene Geometry comprising auxiliary information which contains a (M × 1) binary mask indicating the channels of the transform domain SHD coefficients that would be used by the Noise Cancellation AIM for denoising. Speech Detection and Separation AIM uses the Source Model KB which contains discrete-time and discrete-valued simple acoustic source models that are used in source separation.
- Noise Cancellation Module .
- Receives Transform Audio from Speech Detection and Separation AIM and Audio Scene Geometry which includes attributes pertaining to the Audio Block being processed for denoising, and SHD coefficients.
- Uses Source Model KB to produce Enhanced Transform Audio as an (M × S) complex-valued data structure which will in the next stage be processed through Audio Synthesis Transform AIM to obtain Enhanced Audio Objects.
- Audio Synthesis Transform receives Enhanced Transform Audio and outputs Enhanced Audio Objects (F × S) by applying the inverse of the analysis transform.
- Audio Description Packaging:
- Receives Microphone Array Geometry, Enhanced Audio Objects and Audio Scene Geometry.
- Packages Microphone Array Geometry, Enhanced Audio Object, and the Audio Scene Geometry.
- Produces one interleaved stream which contains Multichannel Speech Streams.
6 I/O Data of AI Modules
Table 3 – CAE-EAE AIMs and their data
| AIM | Input Data | Output Data |
| Audio Analysis Transform | Microphone Array Audio | Transform Multichannel Audio |
| Sound Field Description | Transform Multichannel Audio | Spherical Harmonic Decomposition Coefficients |
| Speech Detection and Separation | Spherical Harmonic Decomposition Coefficients | Transform Audio Audio Scene Geometry |
| Noise Cancellation Module | Spherical Harmonic Decomposition Coefficients Transform Audio Audio Scene Geometry |
Enhanced Transform Audio |
| Audio Synthesis Transform | Enhanced Transform Audio | Enhanced Audio Objects |
| Audio Description Packaging | Enhanced Audio Objects Audio Scene Geometry |
Multichannel Audio Stream |
1.1.6 AIW, AIMs, and JSON Metadata
Table 4 – AIW, AIMs, and JSON Metadata
| AIW | AIMs | Namex | JSON |
| CAE-EAE | Enhanced Audioconference Experience | File | |
| CAE-AAT | Audio Analysis Transform | File | |
| CAE-SFD | Sound Field Description | File | |
| CAE-SDS | Speech Detection and Separation | File | |
| CAE-NCM | Noise Cancellation Module | File | |
| CAE-AST | Audio Synthesis Transform | File | |
| CAE-ADP | Audio Description Packaging | File |