<-Go to AI Workflows Go to ToC Enhanced Audioconference Experience->
| 1 Functions | 2 Reference Model | 3 I/O Data |
| 4 Functions of AI Modules | 5 I/O Data of AI Modules | 6 AIW, AIMs and JSON Metadata |
1 Functions
Speech Restoration System restores a Damaged Segment of an Audio Segment containing only speech from a single speaker. The damage may affect the entire segment, or only part of it.
Restoration will not involve filtering or signal processing. Instead, replacements for the damaged vocal elements will be synthesised using a speech model. The latter is a component or set of components, normally including one or more neural networks, which accepts text and possibly other specifications, and delivers audible speech in a specified format – here, the speech of the required replacement or replacements. If the damage affects the entire segment, an entirely new segment is synthesized; if only parts are affected, corresponding segments will be synthesized individually to enable later integration into the undamaged parts of the Damaged Segment, with reference to appropriate Time Labels.
The speech segments necessary for the creation of the speech model can be flexibly resourced from undamaged parts of the input segment or from other recording sources that are consistent with the original segment’s acoustic environment.
Restoration is carried out by synthesising replacements for the damaged vocal elements as follows:
The Speech Segments for Modelling – Audio Segments necessary for the creation of the Neural Network Speech Model – may be obtained from any undamaged parts of the input speech segment; however, other Audio Segments consistent with the original segment’s sound environment can also be used.
2 Reference Model
Figure 1 gives the Reference Model of the Speech Restoration System.
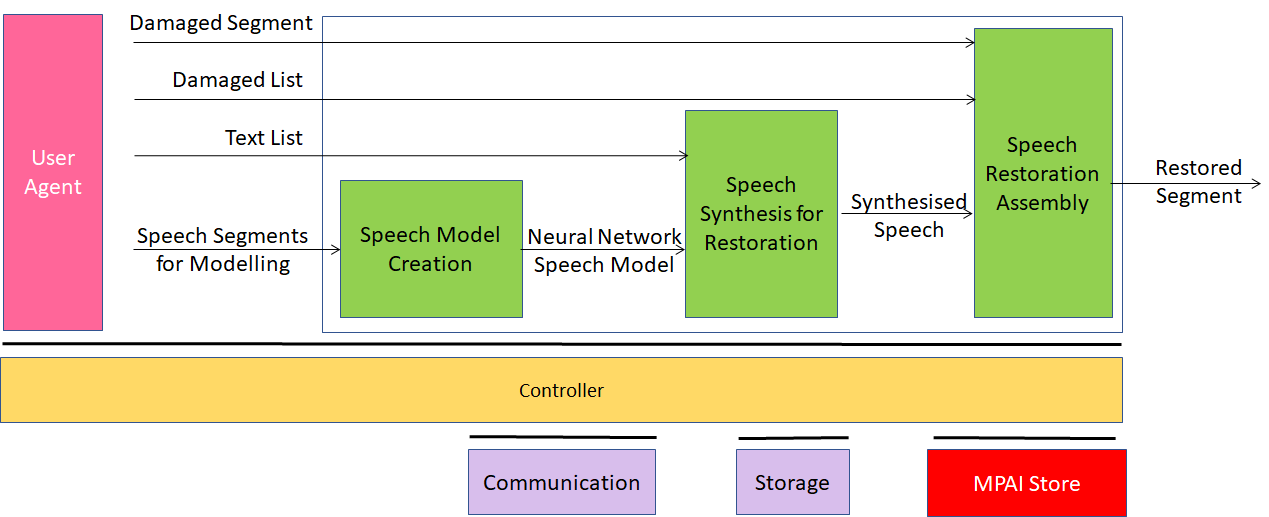
Figure 1 – Speech Restoration System (SRS) Reference Model
In the SRS use case, the entire Damaged Segment can be replaced by a synthesised segment, or parts within it can be synthesized to enable integration of the replaced segments.
3 I/O Data of AI Workflow
Table 1 gives the input and output data of Speech Restoration System.
Table 1 – I/O data of Audio Recording Preservation
| Input | Comments |
| Speech Segments for Modelling | A set of Audio Files containing speech segments used to train the Neural Network Speech Model. |
| Text List | List of texts to be converted into speech by the Speech Synthesis for Restoration AIM. |
| Damaged List | A list of strings of Texts corresponding to the Damaged Segments (if any) requiring replacement with synthetic segments. |
| Damaged Segment | An Audio Segment containing only speech (and not containing music or other sounds) which is either damaged in its entirety or contains one or more Damaged Sections specified in the Damaged List. |
| Output | Comments |
| Restored Speech Segment | An Audio Segment in which the entire segment has been replaced by a synthetic speech segment, or in which each Damaged Segment has been replaced by a synthetic speech segment. |
4 Functions of AI Modules
The AIMs required by the Speech Restoration System Use Case are described in Table 2.
Table 2 – AI Modules of Speech Recording System
| AIM | Function |
| Speech Model Creation | 1. Receives in separate files the Audio Segments for Modelling, adequate for model creation. 2. Creates the current Neural Network Speech Model. 3. Sends that Neural Network Speech Model to the Speech Synthesis for Restoration. |
| Speech Synthesis for Restoration | 1. Receives 1.1. The current Neural Network Speech Model. 1.2. Damaged List as a data structure: 1.2.1. Containing one element if Damaged Segment is damaged throughout or 1.2.2. Representing a list in which each element specifies via Time Labels the start and end of a damaged section within Damaged Segment. 2. Synthesizes each Damaged Section in Damaged List. 3. Sends the newly synthesised segments to the Speech Restoration Assembly as an ordered list. |
| Speech Restoration Assembly | 1. Receives the Damaged Segment. 2. Receives the ordered list of synthetic segments. 3. Receives Damaged List Time Labels, indicating where the synthesized segments should be inserted in left-to-right order. In case Damaged Segment as a whole was damaged, the list contains one entry. 4. Assembles the final version of the Restored Segment. |
5 I/O Data of AI Modules
Table 3 – CAE-SRS AIMs and their I/O Data
| AIM | Input Data | Output Data |
| Speech Model Creation | Speech Segments for Modelling | Neural Network Speech Model |
| Speech Synthesis for Restoration | Text List Neural Network Speech Model |
Synthesised Speech |
| Speech Restoration Assembly | Damaged Segments Damaged List |
Restored Segment |
6 AIW, AIMs and JSON Metadata
Table 4 – AIMs and JSON Metadata
| AIW | AIMs | Names | JSON |
| CAE-SRS | Speech Restoration System | File | |
| CAE-SMC | Speech Model Creation | File | |
| CAE-SSR | Speech Synthesis for Restoration | File | |
| CAE-SRA | Speech Restoration Assembly | File |
<-Go to AI Workflows Go to ToC Enhanced Audioconference Experience->