AI-Enhanced Video Coding (MPAI-EVC)
The goal of the group is to enhance EVC (Essential Video Coding) using AI-tools to reach at least 25% improvement over the baseline profile. The group is currently working on three coding tool: Intra prediction, Super Resolution, and in-loop filtering. For each tool, in the following we describe the proposed approach and the steps of database building, learning phase and inference.
Intra prediction tool
The group built a dataset of 32×32 intra prediction blocks with 1.5M patches and another for 16×16 prediction blocks with 5.5M patches from the AROD dataset.
Another dataset was put together for testing purposes extracting patches from the first frame of the JVET Class B sequences BasketballDrive, BQTerrace, Cactus, Kimono1, ParkScene
The approach consists in feeding the EVC intra predictor to an autoencoder inspired by the Contex Encoders architecture together with the relative causal context, recasting the problem as an inpainting task via masked convolutions.The autoencoder is trained offline over patches extracted from the AROD dataset to minimize the MSE between its output and the original image block to predict.
In the inference phase the EVC encoder sends, for each 32×32 and 16×16 CU, the 64×64 decoded context to the server for the mode 0 EVC intra predictor (DC). The server feeds the received 64×64 context into the trained autoencoder and returns to the EVC encoder the new 32×32 or 16×16 predictor, depending on the case. The EVC encoder finally replaces EVC DC intra predictor with the autoencoder-generated predictor and this predictor is then put into competition with the other 4 EVC intra predictors (modes 1-4) and encoding proceeds as usual. The generated bitstream remains fully decodable under the assumption that the autoencoder network is available at the decoder side.
More experiments were performed to improve the previous BD-rate. We added a random cropping strategy on the input pictures to avoid overfitting in the training phase. We trained the neural network over another dataset: BVI.
Table 1 shows the BD-rate gains of the DC-enhanced EVC encoder over the reference EVC encoder, with gains in the 1% to 2% range depending on the considered QP range.
Future plans include:
- extending the proposed approach also to 8×8 and 4×4 CUs
- experimenting with other network architectures than convolutional
- change the MSE during training
- enlarge the context to 128×128
| BD-rate variation [%] | ||
| Sequence | QPs 22-47 | QPs 32-47 |
| BasketballDrive | -2.54 | -4.19 |
| BQTerrace | -0.16 | -0.51 |
| Cactus | -1.31 | -1.90 |
| Kimono | -1.13 | -1.40 |
| ParkScene | -1.06 | -1.51 |
| AVG | -1.24 | -1.90 |
Table 1: BD-rate gains over the EVC baseline encoder where the 32×32 and 16×16 mode 0 (DC) Intra predictor is replaced by that generated by a convolutional autoencoder.
Super resolution tool
We built a dataset to train the super resolution network: 2000 pictures (KAGGLE DATASET 4K standard resolution images (2057 files) https://www.kaggle.com/evgeniumakov/images4k).
We have experimented with the performances of the trained network on 8 sequences of 500 frames each for the super resolution SD to HD, and on 3 sequences of 500 frames each for the super resolution HD 2 4K.
The group has worked on the computation of the BD-rate and the results so far obtained are described below.
The SD to HD testing phase has been finalized on all QPs (15,30,37 and 45), with activated
the in-loop filter, which is a deblocking filtering in EVC codec.
The following figures show the BD-rate curves for each sequence:
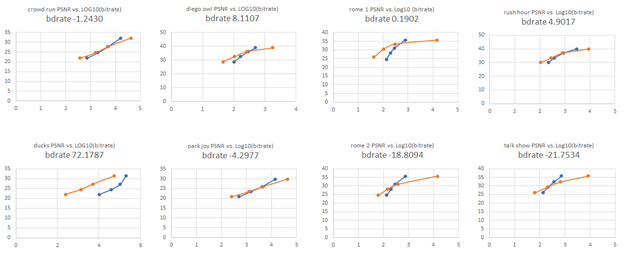
Figure 1: Orange curves represent reference HD data at QPs 15, 30, 37 and 45; the blue curves represent super-resolution upscaling of SD-sequences encoded at QPs 15, 30, 37 and 45.
| Sequence | BD-rate QP Averaged [%] |
| Rome_1 | 0.1902 |
| Rome_2 | -18.8094 |
| Talk_show | -21.7534 |
| Rush_hours | 4.9017 |
| Duck _take_off | 72.1787 |
| Diego_and_the_owl | 8.1107 |
| Crowd_run | -1.2430 |
| Parkjoy | -4.2977 |
| Average | 4.9097 |
Table 2: BD-rate variation (Bjontegaard) averaged over the QPs of Figure 1, for the EVC baseline encoder where the super resolution block is replaced by the deep-learning based super resolution with inloop filter activated.
| Sequence | BD-rate QP Averaged [%] |
| Rome_1 | 0.1902 |
| Rome_2 | -18.8094 |
| Talk_show | -21.7534 |
| Rush_hours | 4.9017 |
| Diego_and_the_owl | 8.1107 |
| Crowd_run | -1.2430 |
| Parkjoy | -4.2977 |
| Average | -4.701 |
Table 3: BD-rate variation (Bjontegaard) averaged over the QPs of Table 2, having eliminated the sequence Ducks take off, probably an outlier.
The HD to 4K BD-rate computation is still ongoing.
The next steps are:
| Tool | Date | Topic | Who |
| Intra prediction | 1 meeting cycle | More experiments to improve the BD-rate | Attilio, Alessandra, Roberto |
| 1 meeting cycle | Experiments on 8×8 block size | Attilio | |
| 2 meeting cycles | Measure the performances after training (BD-Rate) | Attilio | |
| x meeting cycles | Chose a common dataset and repeat the experiments | Attilio | |
| Super Resolution | 2 meeting cycles | More experiments to improve the BD-rate | Francesco, Antonio, Mattia and Alessandro |
| x meeting cycles | Chose a common dataset and repeat the experiments | Francesco, Antonio, Mattia and Alessandro | |
| Next candidate AI-tool | 2 meeting cycle | Evaluation of possible candidate (pros/cons in terms of open source, results..)
|
All |
Future plan
- motion compensation: improve the motion compensation using NN architecture
- inter prediction: use NN architectures to refine the quality of inter-predicted blocks; introduce new inter prediction mode which tries to predict a frame directly without the use of side information; leverage on Optical Flow algorithm for the motion estimation.
- quantization: uniform scalar quantization used in classical video codec standard does not conform to the characteristics of human visual system. It is possible to use a quantization strategy based on neural networks.
- arithmetic encoder: improve the CABAC performance by leveraging NN to directly predict the probability distribution of intra modes instead of the handcraft context models