<- Use Case Go to ToC Data Types ->
The Entity and Context Understanding Composite AIM is specified in the following six sections.
1 Functions
The functions of Entity and Context Understanding (HMC-ECU) allow a Machine to achieve understanding the information conveyed by an Entity and its Context in order to enable the Entity Dialogue Processing AIM to produce a pertinent communication.
Therefore, Entity and Context Understanding (HMC-ECC)::
- Receives the Audio-Visual Scene Descriptors.
- Separates the components of the Audio-Visual Scene Descriptors.
- Performs
- Recognition of Entity’s Speech.
- Recognition of Audio Object and Visual Object.
- Understanding of Entity’s Natural Language expressed as Text in the Context of the Audio and Visual Instance.
- Extraction of the Entity’s Personal Status.
- Translation of the Entity’s Text.
- Produces:
- Audio-Visual Scene Geometry
- Entity ID
- Audio Instance ID
- Visual Instance ID
- Personal Status
- Translated and Refined Text
- Meaning.
2 Reference Model of Entity Context Understanding
Figure 1 depicts the Reference Architecture of the Entity and Context Understanding Composite AIM.
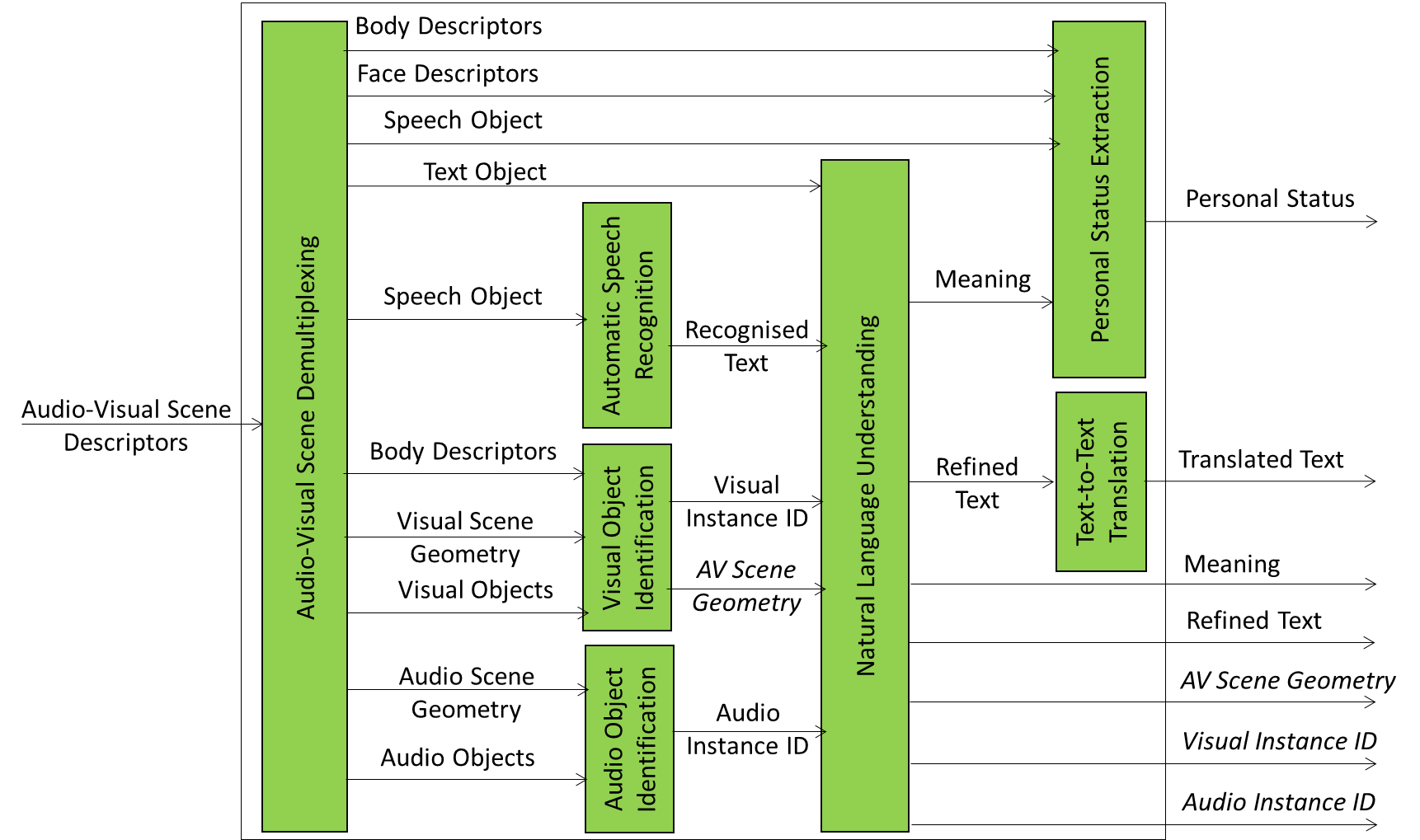
Figure 1 – The Entity and Context Understanding Composite AIM
Note that Output Data in italic are passed directly from the homonymous Input Data.
3 I/O Data of Entity Context Understanding
Table 1 specifies the Input and Output Data of the of the Entity Context Understanding AIM.
Table 1 – I/O Data of the Entity Context Understanding Composite AIM
| Input | Description |
| Body Descriptors | The Descriptors of the Body Objects of Entities in the Visual Scene. |
| Face Descriptors | The Descriptors of the Face Objects of Entities in the Visual Scene. |
| Speech Object | The digital representation of the speech emitted by the Entity. |
| Audio-Visual Scene Geometry | The digital representation of the spatial arrangement of the Audio, Visual, and Audio-Visual Objects of the Scene. |
| Visual Objects | The Visual Objects of the Scene. |
| Audio Objects | The Audio Objects of the Scene. |
| Text Object | Text of Entity with Entity ID. |
| Output | Description |
| Personal Status | Personal Status of Entity having the Entity ID. |
| Translated Text | Translated Text of Text Object or of Text conveyed by Speech Object. |
| Refined Text | Refined Text of Speech Object. |
| Meaning | Other name for Refined Text Descriptors. |
| Visual Instance ID | The Identifier of the specific Visual Object belonging to a level in the taxonomy. |
| Audio-Visual Scene Geometry | As in Input |
| Audio Instance ID | The Identifier of the specific Audio Object belonging to a level in the taxonomy. |
4 Functions
Table 2 gives the functions of the AI Modules of the Avatar Videoconference Server AIW.
Table 2 – AI Modules of Avatar Videoconference Server AIW
| AIM | Functions |
| Audio-Visual Scene Demultiplexing | Makes available Body and Face Descriptors, Speech and Text Object, Audio and Visual Scene Geometry, Audio and Visual Object to the AIMs of the Composite AIM. |
| Automatic Speech Recognition | Produces Recognised Text |
| Visual Object Identification | Identifies the Visual Object. |
| Audio Object Identification | Identifies the Audio Object. |
| Natural Language Understanding | Understand the text and speech information of the Entity |
| Personal Status Extraction | Extracts the Personal Status of the Entity. |
| Text-to-Text Translation | Translates the text to another language. |
5 Input/Output Data
Table 3 gives the Input/Output Data of the AI Modules of the Avatar Videoconference Server AIW.
Table 3 – AI Modules of Avatar Videoconference Server AIW
| AIM | Input | Output |
| Audio-Visual Scene Demultiplexing | Audio-Visual Scene Descriptors | Body Descriptors Face Descriptors Speech Object Text ObjectAudio Scene Geometry Visual Scene Geometry Audio Objects Visual Objects |
| Automatic Speech Recognition | Speech Object | Recognised Text |
| Visual Object Identification | Body Descriptors Visual Scene Geometry Visual Objects |
Visual Instance Identifier |
| Audio Object Identification | Audio Scene Geometry Audio Objects |
Audio Instance Identifier |
| Natural Language Understanding | Recognised Text Visual Instance Identifier Visual Scene Geometry Visual Instance Identifier Audio Instance Identifier Audio Scene Geometry |
Meaning Refined Text Visual Scene Geometry Visual Instance Identifier Audio Instance Identifier Audio Scene Geometry |
| Personal Status Extraction | Body Descriptors Face Descriptors Speech Object Text Object Meaning |
Personal Status |
| Text-to-Text Translation | Refined Text | Translated Text |
6 AIW, AIMs and JSON Metadata
Table 4 – AIW, AIMs, and JSON Metadata
| AIW/AIMs | Name | JSON | |
| HMC-ECU | Entity Context Understanding | X | |
| – | OSD-SDX | Audio-Visual Scene Demultiplexing | X |
| – | MMC-ASR | Automatic Speech Recognition | X |
| – | OSD-VOI | Visual Object Identification | X |
| – | CAE-AOI | Audio Object Identification | X |
| – | MMC-NLU | Natural Language Understanding | X |
| – | MMC-PSE | Personal Status Extraction | X |
| – | MMC-TTT | Text-to-Text Translation | X |
7 Profiles
The Profiles of Entity and Context Understanding Composite AIM are specified