<-Go to AI Workflows Go to ToC Text and Speech Translation->
| 1 Functions | 2 Reference Architecture | 3 I/O Data |
| 4 Functions of AI Modules | 5 I/O Data of AI Modules | 6 AIW, AIMs, and JSON Metadata |
| 7 Reference Software | 8 Conformance Texting | 9 Performance Assessment |
1 Functions
In a Question Answering (QA) System, a machine provides answers to a user’s question presented in natural language. Multimodal Question Answering improves current QA systems that are only able to deal with text or speech inputs by offering the requesting human the ability to present both speech or text and images. For example, users might ask “Where can I buy this tool?” while showing the picture of the tool, even without showing their faces. In the Multimodal Question Answering (MMC-MQA) Use Case, a machine responds to a question expressed by a user in text or speech while showing an object. The machine’s response may use text and synthetic speech.
2 Reference Model
Figure 1 gives the Multimodal Question Answering Reference Model including the input/output data, the AIMs, and the data exchanged between and among the AIMs.
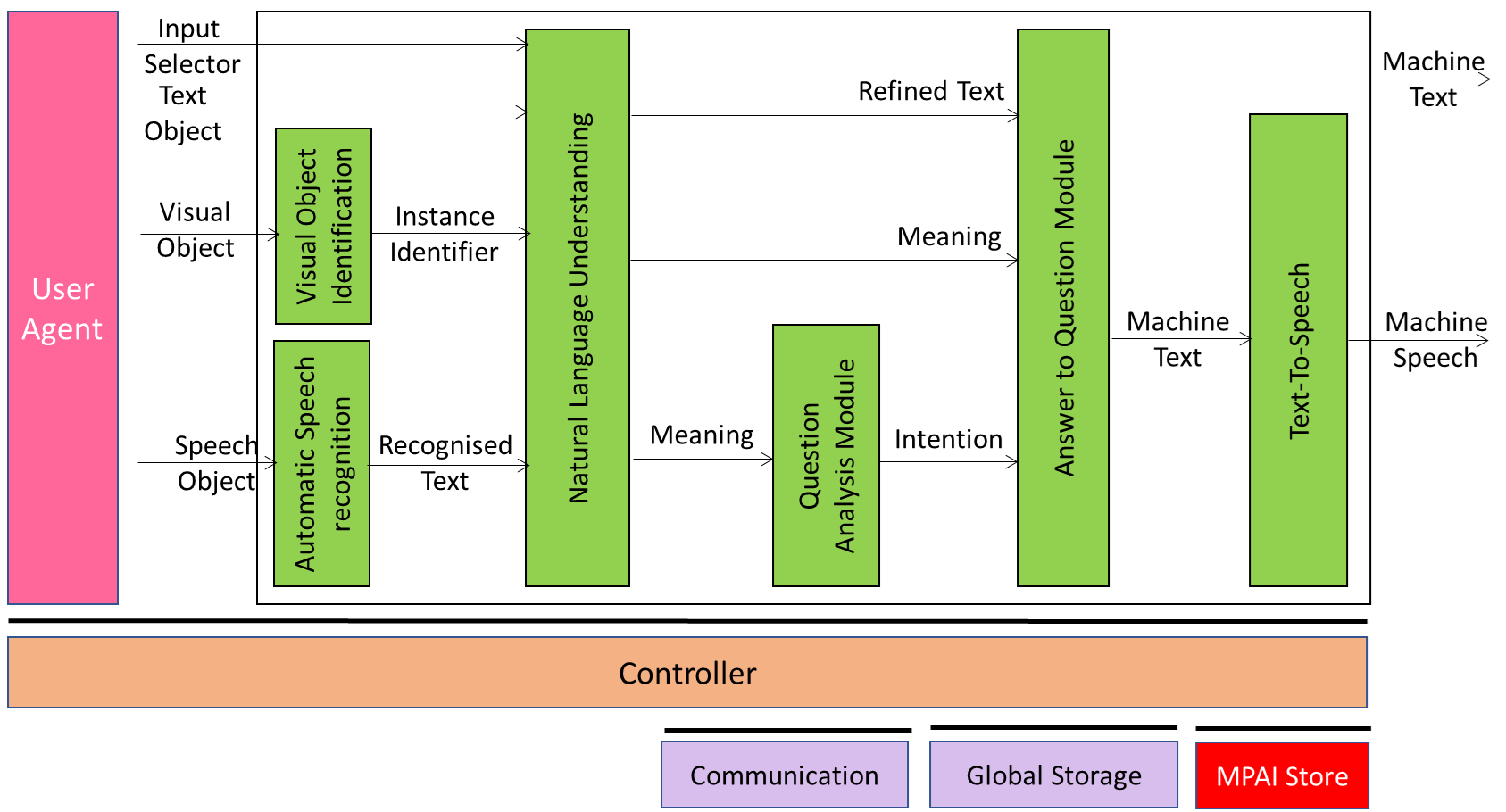 Figure 1 – Reference Model of Multimodal Question Answering
Figure 1 – Reference Model of Multimodal Question Answering
The operation of Multimodal Question Answering develops in the following way:
- Input Selector is used to inform the machine whether the human employs Text or Speech to query the machine.
- Depending on the value of Input Selector, Natural Language Understanding:
- Extracts the Meaning of the question from and refines Recognised Text.
- Extracts the Meaning of the question from Input Text.
- Visual Object Identification identifies the Visual Object.
- Question Analysis Module determines the Intention of the question.
- Module for Question Answering uses Intention and Meaning to produce the answer as Machine Text.
- Text-To-Speech produces Machine Speech from Machine Text.
3 I/O Data
The input and output data of the Multimodal Question Answering Use Case are:
Table 1 – I/O Data of Multimodal Question Answering
| Input | Descriptions |
| TextObject | Text typed by the human as a replacement for Input Speech. |
| Input Selector | Data determining the use of Speech or Text. |
| Visual Object | Video of the human showing an object held in hand. |
| Speech Object | Speech of the human asking a question the Machine. |
| Output | Descriptions |
| Machine Text | The Text generated by Machine in response to human input. |
| Machine Speech | The Speech generated by Machine in response to human input. |
4 Functions of AI Modules of Multimodal Question Answering
Table 2 provides the functions of the Multimodal Question Answering Use Case.
Table 2 – Functions of AI Modules of Multimodal Question Answering
| AIM | Function |
| Visual Object Identification | Identifies the Visual Object. |
| Automatic Speech Recognition | Recognises Speech. |
| Natural Language Understanding | Extracts Meaning and refines Text from Recognised Text. |
| Question Analysis Module | Extracts Intention from Text. |
| Answer to Question Module | Produces response of Machine to the query. |
| Text-to-Speech | Synthesises Speech from Text. |
5 I/O Data of AI Modules
The AI Modules of Multimodal Question Answering are given in Table 3.
Table 3 – AI Modules of Multimodal Question Answering
| AIM | Receives | Produces |
| Visual Object Identification | Visual Object | Instance Identifier |
| Automatic Speech Recognition | Speech Object | Recognised Text |
| Natural Language Understanding | Text Object or Recognised Text | Refined Text Meaning |
| Question Analysis Module | Meaning | Intention |
| Answer to Question Module | 1. Input or Recognised Text 2. Intention 3. Meaning |
Machine Text |
| Text-to-Speech | Machine Text | Machine Speech |
6 AIW, AIMs, and JSON Metadata
Table 4 provides the links to the AIW and AIM specifications and to the JSON syntaxes. AIMs/1 indicates that the column contains Composite AIMs and AIMs/2 indicates that the column contains their Basic AIMs.
Table 4 – AIW, AIMs, and JSON Metadata
| AIW | AIMs/1 | AIMs/2 | Name | JSON |
| MMC-MQA | Multimodal Question Answering | X | ||
| OSD-VOI | Visual Object Identification | X | ||
| OSD-VDI | Visual Direction Identification | X | ||
| OSD-VOE | Visual Object Extraction | X | ||
| OSD-VII | Visual Instance Identification | X | ||
| MMC-ASR | Automatic Speech Recognition | X | ||
| MMC-NLU | Natural Language Understanding | X | ||
| MMC-QAM | Question Analysis Module | X | ||
| MMC-AQM | Answer to Question Module | X | ||
| MMC-TTS | Text-to-Speech | X |
7 Reference Software
8 Conformance Testing
| Input Data | Data Type | Input Conformance Testing Data |
| Input Selector | Binary data | For Input Selector=0 and Input Selector=1 |
| Text Object | Unicode | All input Text files to be drawn from Text Files. |
| Speech Object | .wav | All input Speech files to be drawn from Audio Files. |
| Input Image | JPEG | All input Image files to be drawn from Images. |
| Output Data | Data Type | Input Conformance Testing Data |
| Machine Text | Unicode | All Text files produced shall conform with Text files. |
| Machine Speech | .wav | All Speech files produced shall conform with Speech files. |
9 Performance Assessment
<-Go to AI Workflows Go to ToC Text and Speech Translation->