1 Functions of Client Receiver
2 Reference Model of Client Receiver
4 Functions of Videoconference Client Receiver’s AI Modules
5 I/O Data of Videoconference Client Receiver’s AI Modules
6 AIW, AIM, and JSON Metadata of Videoconference Client Receiver
1 Functions of Client Receiver
The Function of the Receiving Client is to:
- Create the local Audio-Visual Scene by:
- Placing and animating the Avatar Models with their Spatial Attitudes.
- Adding Speech to Avatars’ Mouths.
- Render the Audio-Visual Scene as seen from the Participant-selected Point of View.
2 Reference Model of Client Receiver
Figure 6 depicts the Reference Model of the Videoconference Client Receiver. Red Text for Data received at the start. This is the operation:
- At the start
- Receives Portable Avatars containing:
- Audio-Visual Scene Descriptors
- Avatar Models
- Spatial Attitudes
- Creates the initial Audio-Visual Scene.
- Receives Portable Avatars containing:
- During the Videoconference:
- Receives the Avatar Models containing:
- Speech
- Body Descriptors
- Face Descriptors
- Creates the running Audio-Visual Scene using each Avatar’s:
- Body and Face Descriptors.
- Speech Objects.
- Receives the Avatar Models containing:
- Renders the Audio-Visual Scene based on the selected Point of View.
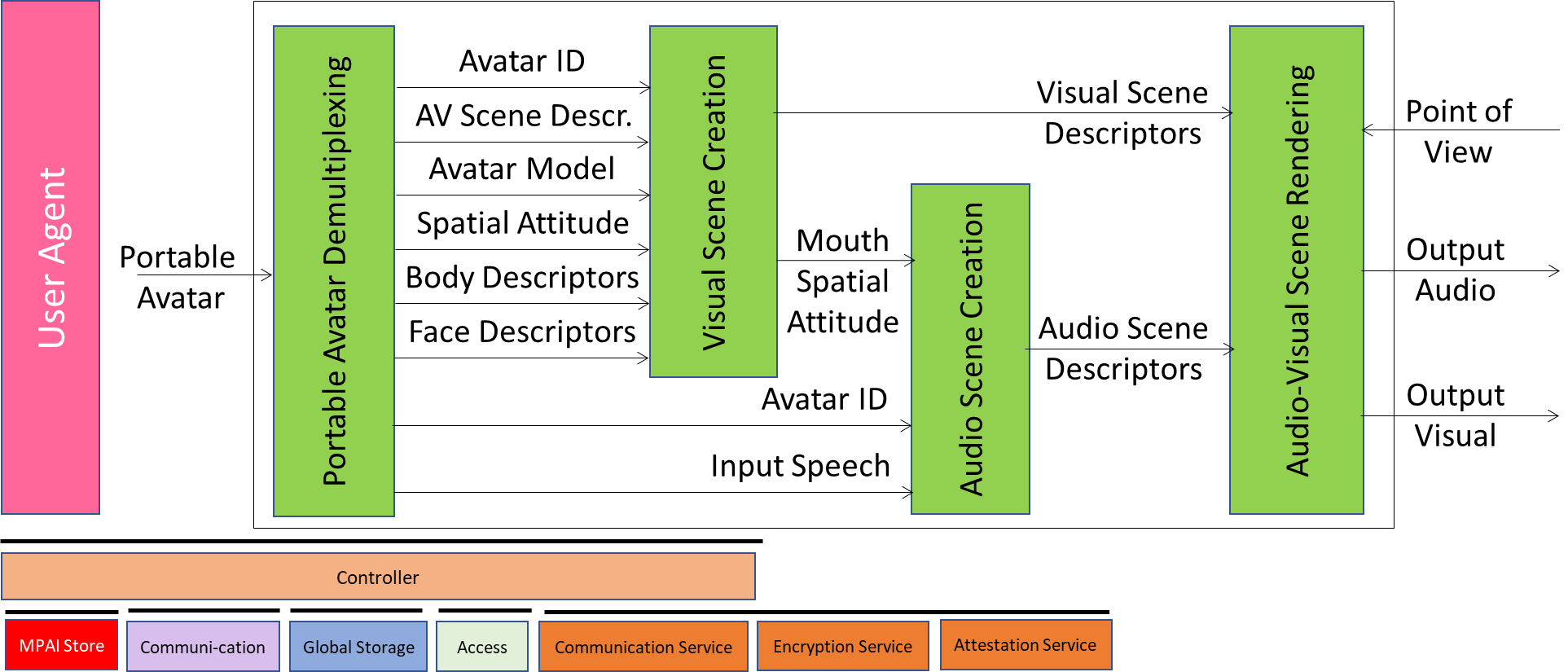
Figure 6 – Reference Model of Videoconference Client Receiver
3 I/O Data of Client Receiver
Table 14 gives the input and output data of Videoconference Client Receiver.
Table 14 – Input and Output Data of Videoconference Client Receiver AIW
| Input | Description |
| Point of View | Avatar-selected Position to see the Audio-Visual Scene. |
| Portable Avatars | Portable Avatars from Videoconference Avatar Server. |
| Output | Description |
| Output Audio | Rendered by Audio-Visual Scene Rendering. |
| Output Visual | Rendered by Audio-Visual Scene Rendering. |
4 Functions of Videoconference Client Receiver’s AI Modules
Table 15 gives the AI Modules of Videoconference Client Receiver AIW.
Table 15 – Functions of Videoconference Client Receivers’ AI Modules
| AIM | Input |
| Portable Avatar Demultiplexing | Extracts Avatar ID, Audio-Visual Scene Descriptors, Avatar Model, Spatial Attitude, Body Descriptors, Face Descriptors, and Input Speech from Portable Avatars. |
| Visual Scene Creation | Creates the Visual Scene and provides the Spatial Attitudes of the Mouths of all Avatars. |
| Audio Scene Creation | Creates the Audio Scene. |
| Audio-Visual Scene Rendering | Provides a ready-to-rendered Audio-Visual Scene. |
5 I/O Data of Videoconference Client Receiver’s AI Modules
Table 16 gives the AI Modules of Videoconference Receiving Client AIW.
Table 16 – I/O Data of Videoconference Client Receivers’ AI Modules
| AIM | Input | Output |
| Portable Avatar Demultiplexing | Portable Avatars | 1. Avatar ID
2. Audio-Visual Scene Descriptors 3. Avatar Model 4. Spatial Attitude 5. Body Descriptors 6. Face Descriptors 7. Input Speech |
| Visual Scene Creation | 1. Avatar ID
2. Audio-Visual Scene Descriptors 3. Avatar Model 4. Spatial Attitude 5. Body Descriptors 6. Face Descriptors |
1. Visual Scene Descriptors
2. Mouth Spatial Attitudes |
| Audio Scene Creation | 1. Avatar ID
2. Input Speech 3. Mouth Spatial Attitudes |
Audio Scene Descriptors |
| Audio-Visual Scene Rendering | 1. Audio Scene Descriptors
2. Visual Scene Descriptors 3. Point of View |
1. Output Audio
2. Output Visual |
6 AIW, AIM, and JSON Metadata of Videoconference Client Receiver
Table 17 – AIMs and JSON Metadata
| AIW | AIMs | Name | JSON |
| PAF-CRX | Videoconference Client Receiver | X | |
| – | PAF-PDX | Portable Avatar Demultiplexing | X |
| – | PAF-VSC | Visual Scene Creation | X |
| – | PAF-ASC | Audio Scene Creation | X |
| – | PAF-AVR | Audio-Visual Scene Rendering | X |