
Standards for audio exist: MPEG-1 Audio layer II and layer III (so called MP3) and a slate of AAC standards serving all tastes offer efficient ways to store and transmit different types of mono, stereo and multichannel audio . MPEG-H offers ways to transmit and present 3D audio experiences.
Never before, if not at the level of company products, however, was there a standard whose goal is not to preserve audio quality at low bitrates, but to improve it or, as the name of the standard – “Context-based Audio Enhancement”, acronym MPAI-CAE – says, enhance it.
Of course there are probably as many ways to enhance audio as there are target users, so what does audio enhancement mean and how can a standard be produced for such a goal?
The magic word that changes the perspective is the word “context”. The MPAI-CAE standard identifies contexts in which audio can be enhanced. The next clarification comes from the fact that the standard is not monolithic, in other words, it identifies several contexts to which the standard can be applied.
Context #1: imagine that you have a sentence that you would like to be able to pronounce with a particular emotional charge: say, happy, or sad, or cheerful etc. or as if it were pronounced with the colour of a specific model utterance. If we were in a traditional encoder-decoder setting, there would be little to standardise. If you have the know how, you do it. If you don’t, you ask someone who has that know how to do it for you.
So, why should there be a standard for context #1?
To answer the question, I need to go back to a definition that I found years ago in the Encyclopaedia Britannica:
Standardisation, in industry: setting of guidelines that permit large production runs of component parts that are readily fitted to other parts without adjustment.
In practice the definition means that if there is a standard for nuts and bolts, and you have a standard nut, you can find someone who has the bolt to which your nut fits.
MPAI-CAE Context #1 is a straightforward application of the Encyclopaedia Britannica definition because it defines the components that can be assembled to make a system that lets you do one of the following:
- It receives your vocal utterance without colour and pronounces it using the speech features of the model utterance
- It receives your vocal utterance without colour, the indication of one or more emotions, the indication of a language and pronounces it with the particular emotion(s) and the “intonation” of the specified language.
There is one point that I must make clear. I said that the standard “defines the components” of the system, but I should have said that the “defines the interfaces of the components”. This is no different than the “nuts and bolts standard”. That standard defines neither the nuts nor the bolts. It defines the threading, i.e., the “interface” between the nut and the bolts.
Lets now go to a block diagram
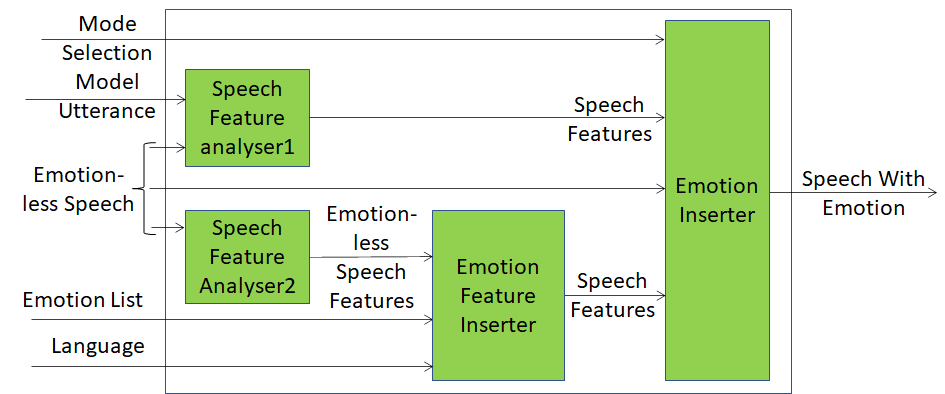
Figure 1 – Reference Model of Emotion Enhanced Speech
Here we see how the MPAI standardisation model works.
- Speech Feature Analyser2 is a very sophisticated technology component that must be able to extract your speech features which are very specific of you and embedded deeply in your vocal utterances.
- Emotion Feature Inserter is an even more sophisticated technology component because it must be able to take the Features of your Emotionless Speech, the Emotion, say, “cheerful” (whose semantics is defined by MPAI-CAE standard), and the Language, and generate Speech Features that convey your personal speech features, the cheerful Emotion, and the specifics of the selected language.
- The Emotion Inserter, another very sophisticated component, receives the Speech Features from the Emotion Feature Inserter together with your Emotionless Speech and produces an emotionally charged vocal utterance according to your wishes.
A similar process unfolds for the upper branch of the diagram where is used. a model utterance.
In principle, each of the identified components – that MPAI calls AI Modules (AIM) – can be re-used in other context. We will see how that is done because this is just the first MPAI-CAE context. There will be soon opportunities to introduce other contexts,