The MPAI project called Multimodal Conversation (MPAI-MMC) has the ambitious goal to use AI to enable forms of human-machine conversation that emulate human-human conversation in completeness and intensity. This means that MMC will leverage all modalities that a human uses when talking to another human: of course, speech, but also text, face and gesture.
In the Conversation with Emotion use case of MMC V1 the machine activates different modules (in italic) to produce data (underlined) in response to a human:
- Speech Recognition (Emotion) extracts text and speech emotion.
- Language Understanding produces refined text, and extracts meaning and text emotion.
- Video Analysis extracts face emotion.
- Emotion Fusion fuses the 3 emotions into fused emotion.
- Dialogue Processing produces machine text and machine emotion.
- Speech Synthesis (Emotion) produces speech with machine emotion.
- Lips Animation produces machine face (an avatar) with facial emotion and lips in sync with speech.
This is depicted in Figure 1.
Multimodal Conversation Version 2 (V2) intends to substantially improve MPAI-MMC V2 by adding Personal Cognitive State and Attitude to Emotion. The combination of the three is called Personal Status, the ensemble of information internal to a person. Emotion and Cognitive State are the result of an interaction with the environment, while Attitude is the stance for new interactions.
Figure 1 shows one component – Personal Status Extraction (PSE) – identified for MPAI-MMC V2. PSE, a Composite AIM containong other specific AIMs that describe modalities and interpret derscriptors, plays a fundamental role in human-machine conversation
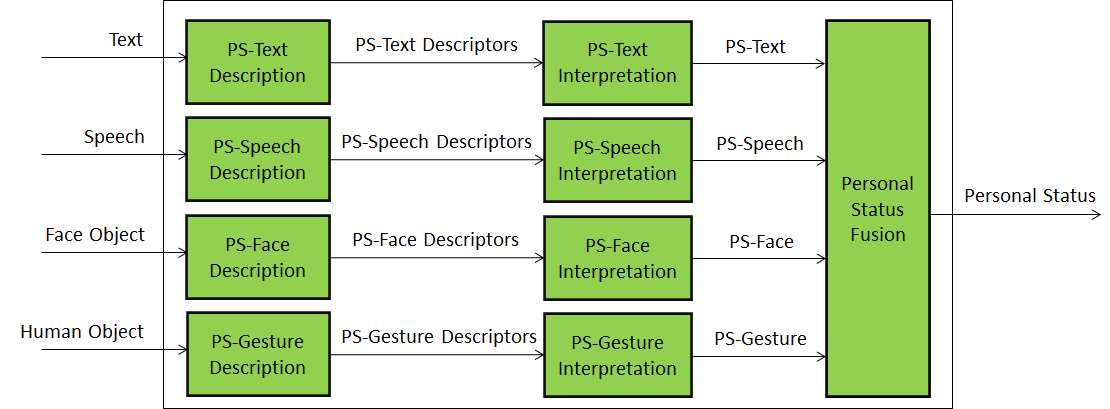
Figure 1 – Personal Status Extraction
A second fundamental component – Personal Status Display – is depicted in Figure 2.
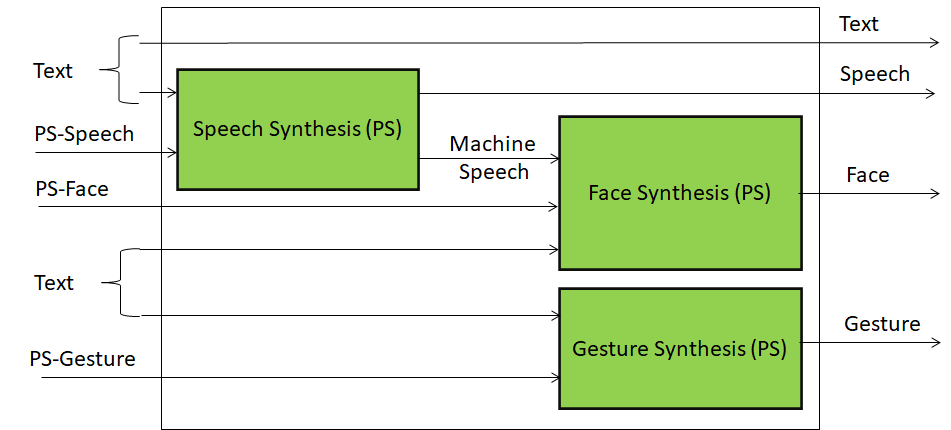
Figure 2 – Personal Status Description