
The MPAI project called Multimodal Conversation (MPAI-MMC), one of the earliest MPAI projects, has the ambitious goal of using AI to enable forms of conversation between humans and machines that emulate the conversation between humans in completeness and intensity. An important element to achieving this goal is the leveraging of all modalities used by a human when talking to another human: speech, but also text, face, and gesture.
In the Conversation with Emotion use case standardised in Version 1 (V1) of MPAI-MMC, the machine activates different modules, that MPAI calls AI Modules (AIM) that produce data in response to the data generated by a human:
| AI Module | Produces | What data | From what data |
| Speech Recognition (Emotion) | Extracts | Text Human speech emotion |
Speech |
| Language Understanding | Produces | Refined text | Recognised text |
| Extracts | Meaning Text emotion |
Recognised text | |
| Video Analysis | Extracts | Face emotion | Face Object |
| Emotion Fusion | Produces | Fused emotion | Text Emotion Speech Emotion Face Emotion |
| Dialogue Processing | Produces | Machine text Machine emotion |
Meaning Refined Text Fused Emotion |
| Speech Synthesis (Emotion) | Produces | Machine speech with Emotion | Text Emotion |
| Lips Animation | Produces | Machine Face with Emotion | Speech Emotion |
This is graphically depicted in Figure 1 where the green blocks correspond to the AIMs.
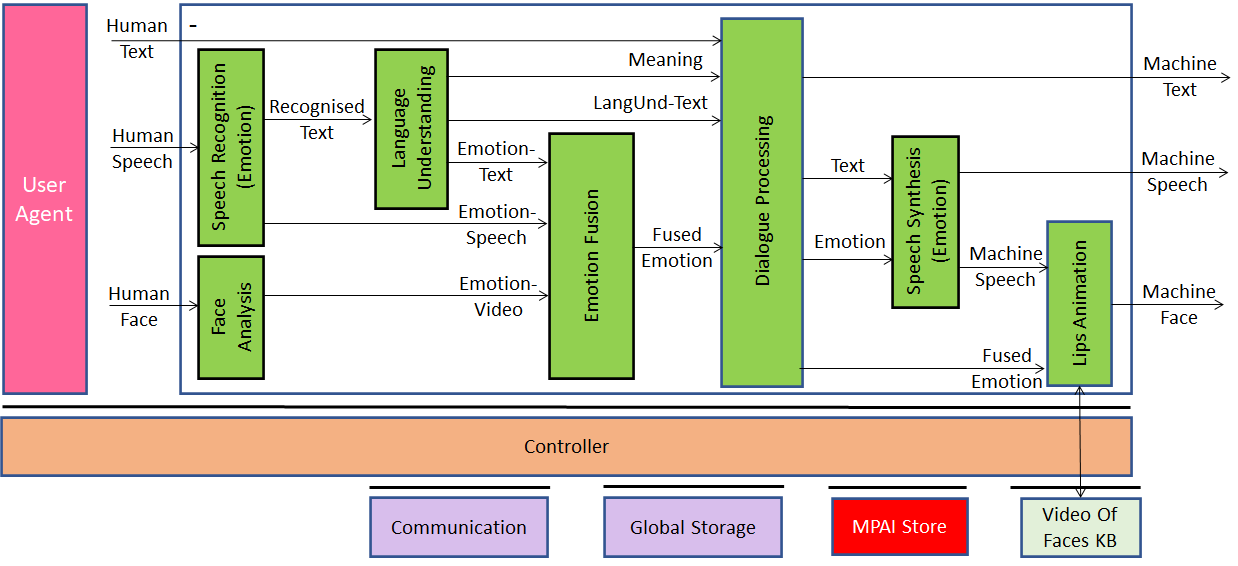
Figure 1 – Conversation with Emotion (V1)
Multimodal Conversation Version 2 (V2), for which a Call for Technologies is planned to be issued on 19 July 2022, intends to improve MPAI-MMC V1 by extending the notion of Emotion with the notion of Personal Status. This is the ensemble of personal information that includes Emotion, Cognitive State, and Attitude. The former two – Emotion and Cognitive State – result from the interaction with the environment, while the last – Attitude – is the stance that will be taken for new interactions based on the achievedEmotion and Cognitive State.
Figure 2 shows the composite AI Module introduced in MPAI-MMC V2: Personal Status Extraction (PSE). This contains specific AIMs that describe the individual text, speech, face and gesture modalities and interpret descriptors. PSE plays a fundamental role in the human-machine conversation as we will see soon.
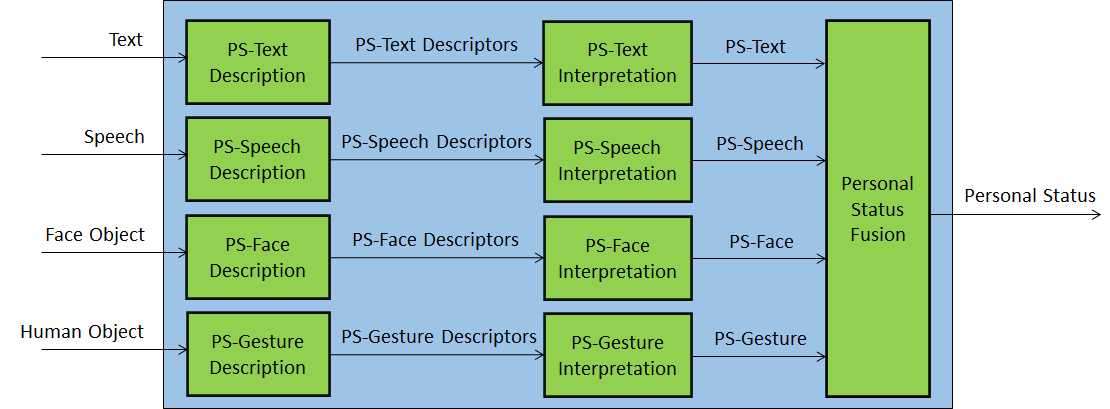
Figure 2 – Personal Status Extraction
A second fundamental component – Personal Status Display (PSD) – is depicted in Figure 3. Its role is to enable the machine to manifest itself to the party it is conversing with. The manifestation is driven by the words generated by the machine and by the Personal Status it intends to attach to its speech, face, and gesture.
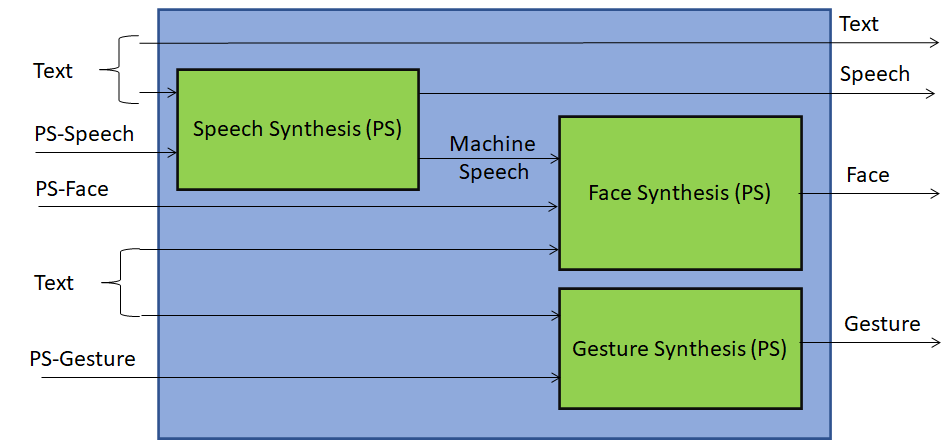
Figure 3 – Personal Status Display
Is there a reason why the word “party” has been used in lieu of “human”. Yes, there is. The Personal Status Display can be used to manifest a machine to a human, but potentially to another avatar. The same can be said of Personal Status Extraction which can extract the Personal Status of a human, but could do that on an avatar as well. MPAI-MMC V2 has examples of both.
Figure 4 shows how can we can leverage the Personal Status Extraction and Personal Status Display AIMs to enhance the performance of Conversation with Emotion – pardon – Conversation with Personal Status.
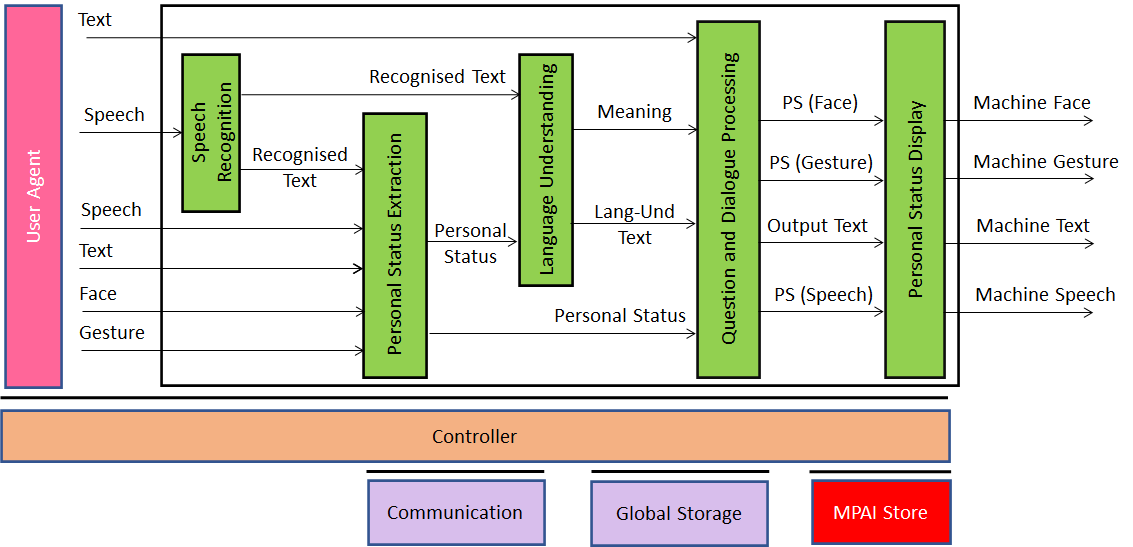
Figure 4 – Conversation with Personal Status V2.0
In Figure 4 speech recognition extracts the text from speech. Language Understanding Question and Dialogue Processing can do a better job because they have access to Personal Status. Finally, the Personal Status Display is a re-usable component that generates a speaking avatar from text and the Personal Status conveyed by the three speech, face, and gesture modalities.
Figure 4 assumes that the outside world provides clean speech, face and gesture. Most often, unfortunately, this is not the case. There is no single speech and, even if there is just one, it is embedded in all sorts of sounds surrounding us. The same can be said of face and gesture. There may be more than one person, and extracting the face or the head, arms, hands, and finger making up the gesture of a human is anything but simple. Figure 5 introduces two critical components Audio Scene Description (ASD) and Visual Scene Description (VSD).
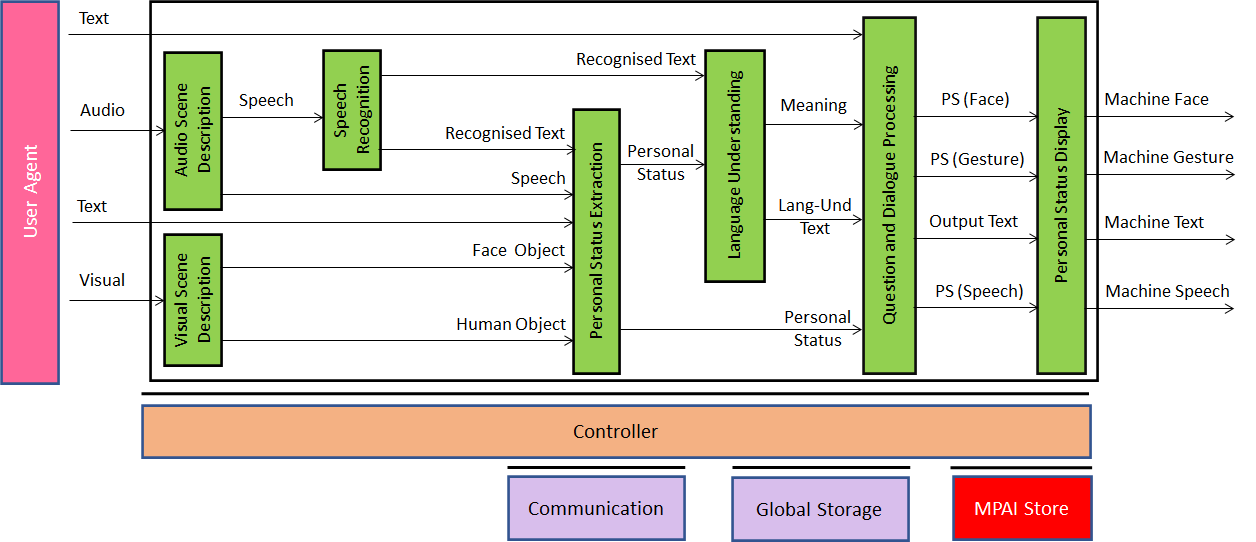
Figure 5 – Conversation with Personal Status and Audio-Visual Scene Description
The task of Audio-Visual Scene Description (AVSD) can be described as “digitally describe a portion of the world with a level of clarity and precision achievable by a human”. The goal expressed in this form can be both unattainable with today’s technology because description of “any” scene is too general. On the other hand, it can also be not sufficient for some purposes because very often the world can be described by using sensors a human does not have.
The scope of Multimodal Conversation V2, however, is currently limited to 3 use cases:
- A human has a conversation with a machine about the objects in a room.
- A group of humans has a conversation with a Connected Autonomous Vehicle (CAV) outside and inside it (in the cabin).
- Groups of humans have a videoconference where humans are individually represented by avatars having a high similarity with the humans they represent.
VSD should provide a description of the visual scene as composed of visual objects classified as human and generic objects. The human object should be decomposable in face, head, arm, hand, and finger objects and should have position and velocity information. The ASD should provide a description of the speech sources as audio objects with their position and velocity.
The first use case is well represented by Figure 6.
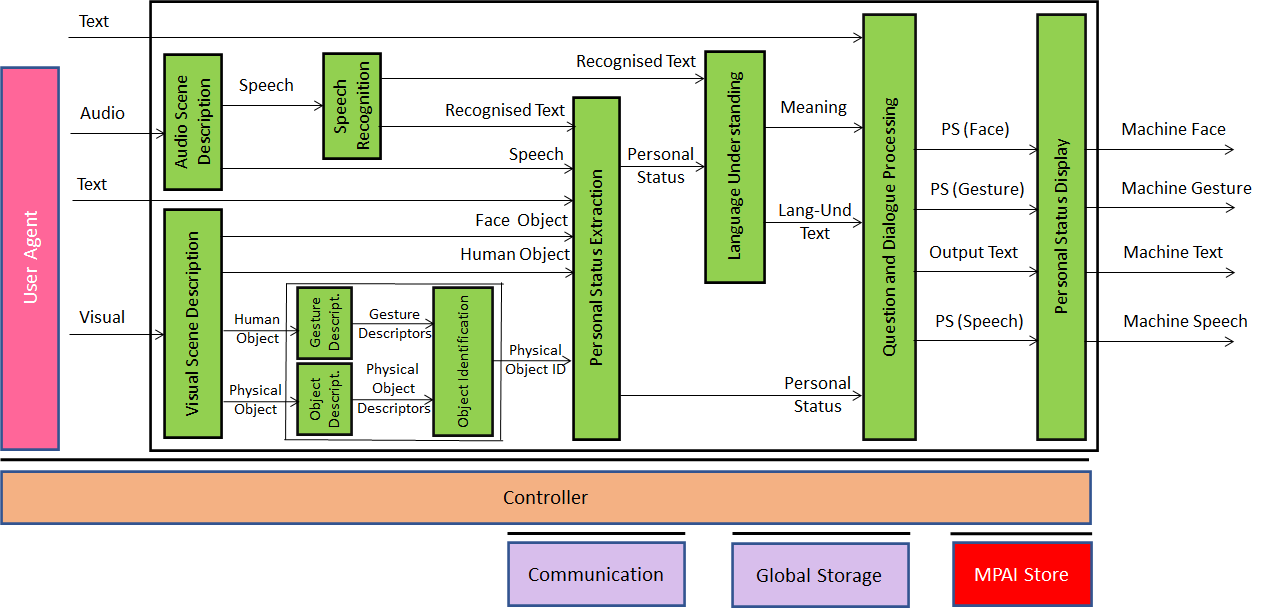
Figure 6 – Conversation About a Scene
The machine sees the human as a human object. The Object Identification ID uses the Gesture Descriptors to understand where the finger of the human points at. If at that position there is an object, the Object Identification AIM uses the Physical Object Descriptors to assign an ID to the object. The machine also feeds Face Object and Human Object into the Personal Status Extraction AIM to understand what the human’s Emotion, Cognitive State and Attitude in order is to enable the Question and Dialogue Processing AIM to fine tune its answer.
Is this all we have to say about Multimodal Conversation V2.0? Well, no, this is the beginning. So, stay tuned for more news or, better, attend the MPAI-MMC V2 online presentation on Tuesday 12 July 2022 at 14 UTC. Please register here to attend.