1 Introduction
Established in September 2020 with its mission defined by the MPAI Statutes as promotion of efficient data use by developing AI-enabled data coding standards and bridging the gap between MPAI standards and their practical use through Intellectual Property Rights Guidelines, MPAI has developed nine Technical Specifications. Purpose of this document is to provide a short overview of the nine Technical Specifications.
1 Introduction
2 AI Framework (MPAI-AIF)
2.1 Version 1
2.2 Version 2
3 Avatar Representation and Animation (MPAI-ARA
4 Context-based Audio Enhancement (MPAI-CAE)
4.1 Version 1
4.2 Version 2
5 Connected Autonomous Vehicle (MPAI-CAV)
6 Compression and understanding of industrial data (MPAI-CUI)
7 Governance of the MPAI Ecosystem (MPAI-GME)
8 Multimodal Conversation (MPAI-MMC)
8.1 Version 1
8.2 Version 2
9 MPAI Metaverse Model (MPAI-MMM) – Architecture
10 Neural Network Watermarking (MPAI-NNW)
2 AI Framework (MPAI-AIF)
MPAI believes that its standards should enable humans to select machines whose internal operation they understand to some degree, rather than machines that are “black boxes” resulting from unknown training with unknown data. Thus, an implemented MPAI standard breaks up monolithic AI applications, yielding a set of interacting components (AI Modules) with identified data. AIMs are combined in workflows (AIW), and exchange data with a known semantics to the extent possible, improving explainability of AI applications but also promoting a competitive market of components with standard interfaces, possibly with improved performance compared to other implementations.
Artificial Intelligence Framework (MPAI-AIF) is the standard that implements this vision by enabling creation and automation of mixed Artificial Intelligence – Machine Learning – Data Processing workflows.
2.1 Version 1
Figure 1 shows the MPAI-AIF V1 Reference Model.
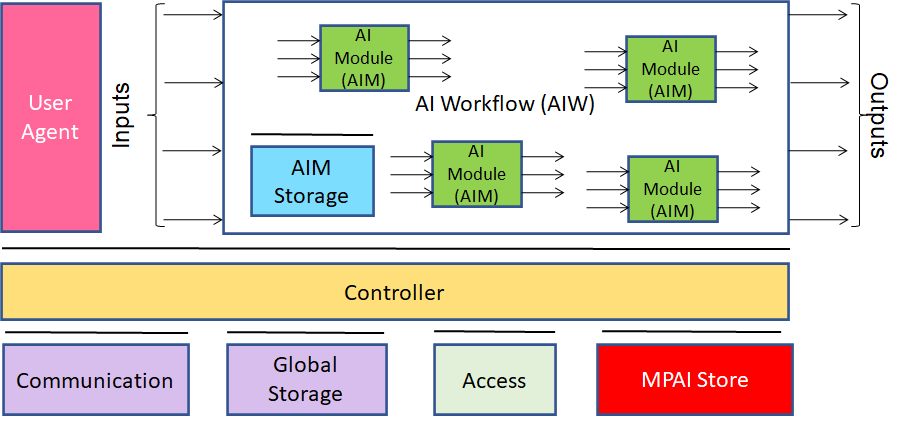
Figure 1 – Reference model of the MPAI AI Framework (MPAI-AIF) V1
The MPAI-AIF Technical Specification V1 and Reference Software is available here.
2.2 Version 2
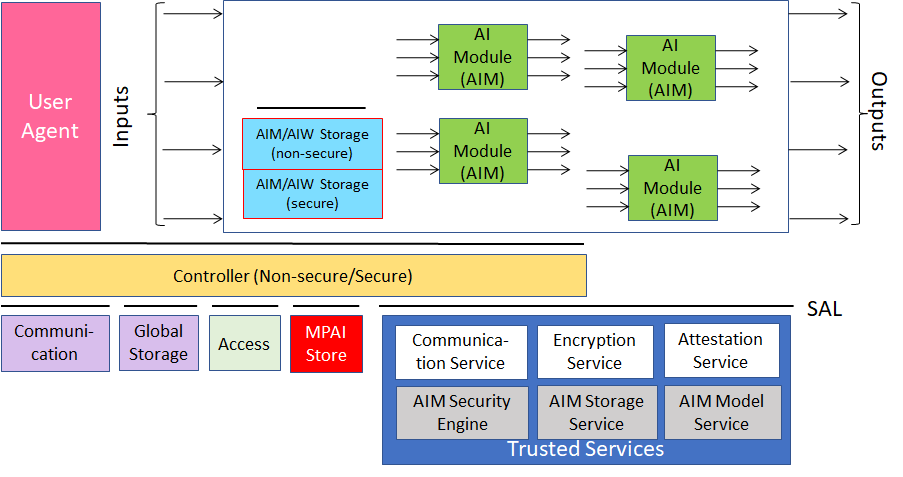
MPAI-AIF V1 assumed that the AI Framework was secure but did not provide support to developers wishing to execute an AI application in a secure environment. MPAI-AIF V2 responds to this requirement. As shown in Figure 1, the standard defines a Security Abstraction Layer (SAL). By accessing the SAL APIs, a developer can indeed create the required level of security with the desired functionalities.
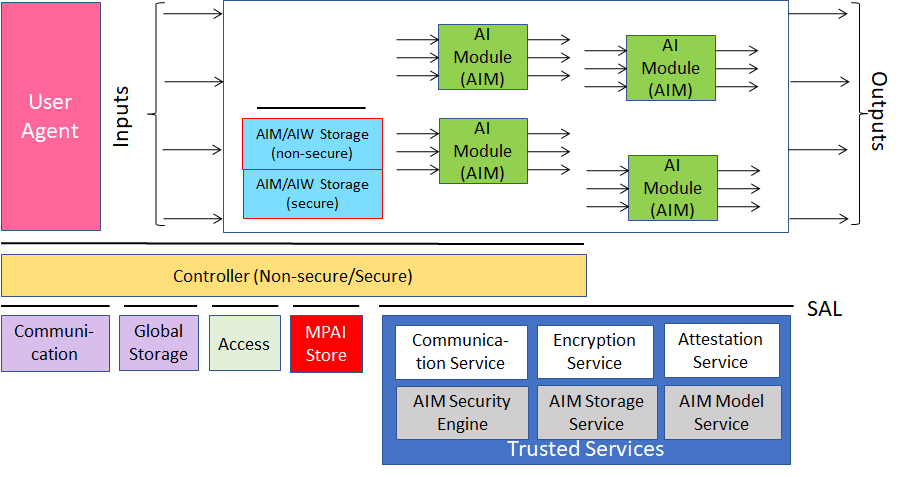
Figure 2 – Reference model of the MPAI AI Framework (MPAI-AIF) V2
MPAI ha published a Working Draft of Version 2 (html, pdf) requesting Community Comments. Comments should be sent to the MPAI Secretariat by 2023/09/24T23:59 UTC. MPAI-AIF V2 is expected to be published on 29 September 2023.
3 Avatar Representation and Animation (MPAI-ARA)
In most cases the underlying assumption of computer-created objects called “digital humans”, i.e., digital objects that can be rendered to show a human appearance has been that creation, animation, and rendering is done in a closed environment. Such digital humans used to have little or no need for standards. However, in a communication and even more in a metaverse context, there are many cases where a digital human is not constrained within a closed environment. For instance, a client may send data to a remote client that should be able to unambiguously interpret and use the data to reproduce a digital human as intended by the transmitting client.
These new usage scenarios require forms of standardisation. Technical Specification: Avatar Representation and Animation (MPAI-ARA) is a first response to the need of a user wishing to enable their transmitting client to send data that a remote client can interpret to render a digital human, having the intended body movement and facial expression faithfully represented by the remote client.
Figure 2 is the system diagram of the Avatar-Based Videoconference Use Case enabled by MPAI-ARA.
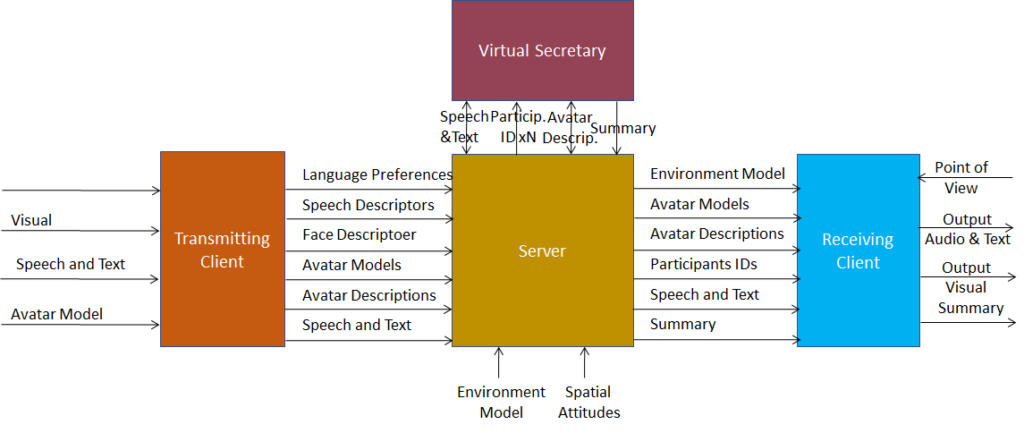
Figure 2 – System diagram of ARA-ABV
Figure 3 is the Reference Model of the Transmitting Client.
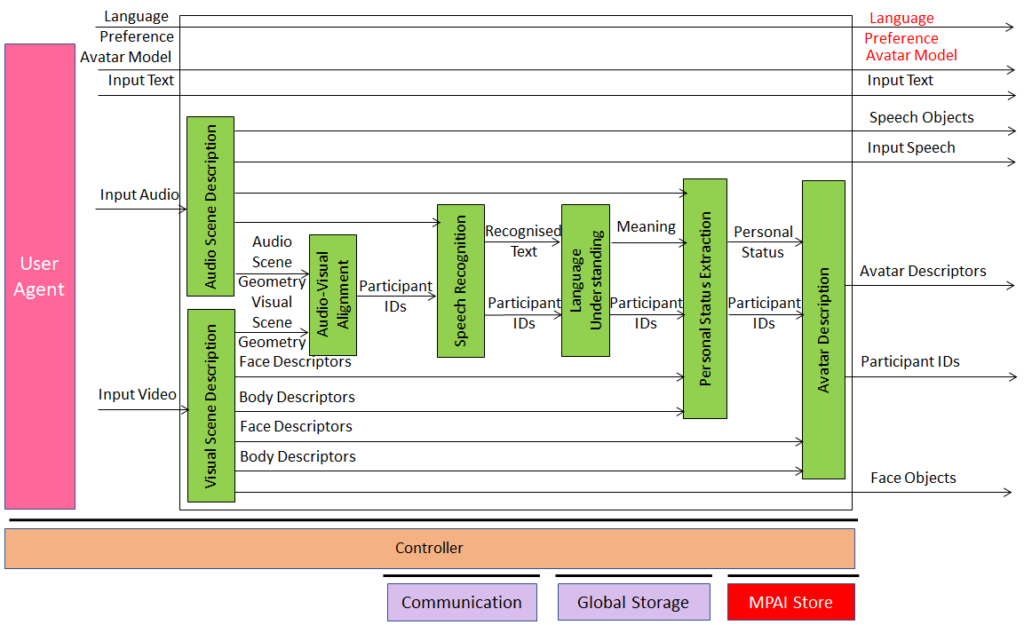
Figure 3 – Reference Model of the ARA-ABV Transmitting Client
The MPAI-ARA Working Draft (html, pdf) is published with a request for Community Comments stage and expected to be published on 29 September 2023.
4 Context-based Audio Enhancement (MPAI-CAE)
Context-based Audio Enhancement (MPAI-CAE) uses AI to improve the user experience for several audio-related applications including entertainment, communication, teleconferencing, gaming, post-production, restoration etc. in a variety of contexts such as in the home, in the car, on-the-go, in the studio etc. using context information to act on the input audio content.
4.1 Version 1
Figure 4 is the reference model of Unidirectional Speech Translation, a Use Case developed by Version 1.
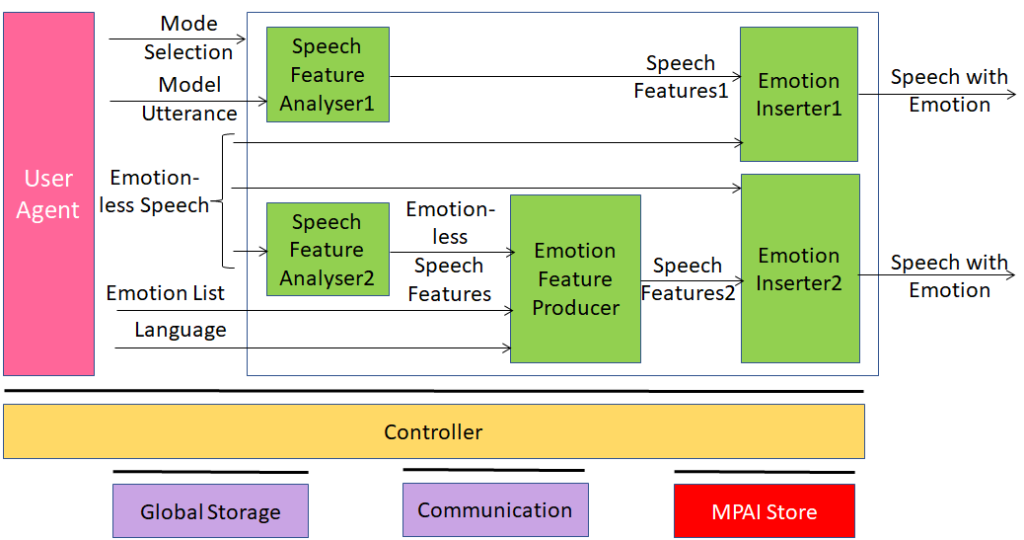
Figure 4 – An MPAI-CAE Use Case: Emotion-Enhanced Speech
The MPAI-AIF Technical Specification V1 and Reference Software is available here.
4.2 Version 2
MPAI has developed the specification of the Audio Scene Description Composite AIM as part of the MPAI-CAE V2 standard (Figure 5 depicts the architecture of the CAE-ASD Composite AIM.
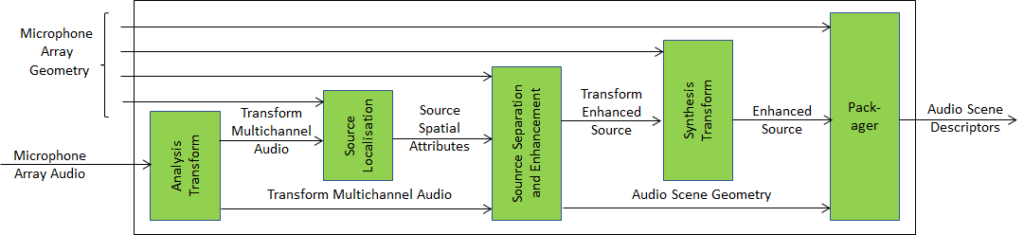
Figure 5 – Audio Scene Description Composite AIM
The MPAI-AIF Technical Specification V2 is available here.
5 Connected Autonomous Vehicle (MPAI-CAV)
Connected Autonomous Vehicle (CAV) is a project addressing the Connected Autonomous Vehicle (CAV) domain and the 5 main operating instances of a CAV:
- Human-CAV interaction (HCI) responds to humans’ commands and queries, senses human activities in the CAV passenger compartment and activates other subsystems as required by humans or as deemed necessary under the identified conditions.
- CAV-Environment interaction acquires information from the physical environment via a variety of sensors and creates a representation of the environment.
- Autonomous Motion Subsystem (AMS) uses different sources of information – ESS, other CAVs, Roadside Units, etc. – to improve the CAV’s understanding of the environment and instructs the CAV how to reach the intended destination.
- Motion Actuation Subsystem (MAS) is the subsystem that operates and actuates the motion instructions in the environment.
The interaction of the 4 subsystems is depicted in Figure 7.
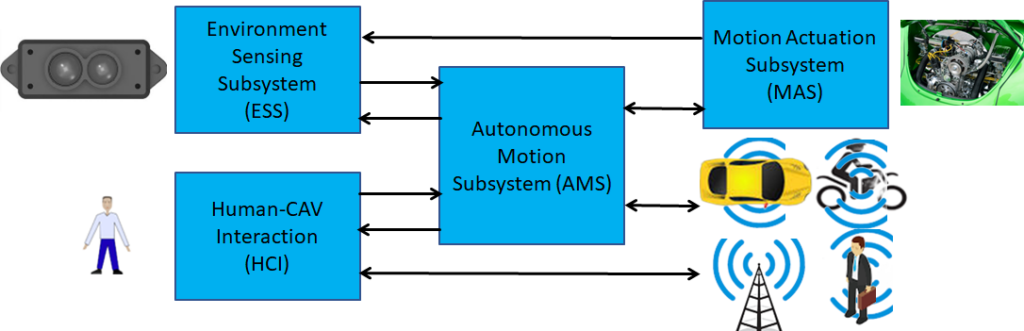
Figure 7 – The MPAI-CAV subsystems
The CAV-HCI subsystem (Figure 8) is specified as an MPAI-MMC V2 Use Case.
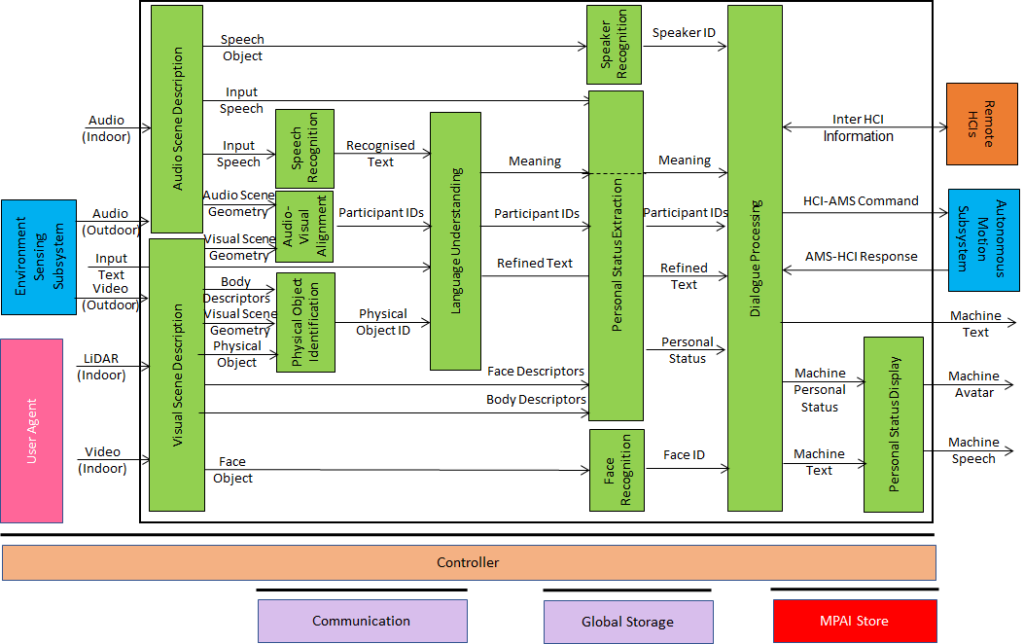
Figure 8 – Reference Model of the Human-CAV Interaction Subsystem
The MPAI-CAV – Architecture Working Draft (html, pdf) is published with a request for Community Comments and expected to be published on 29 September 2023.
6 Compression and understanding of industrial data (MPAI-CUI)
Compression and understanding of industrial data (MPAI-CUI) aims to enable AI-based filtering and extraction of key information to predict the performance of a company by applying Artificial Intelligence to governance, financial and risk data. This is depicted in Figure 6.
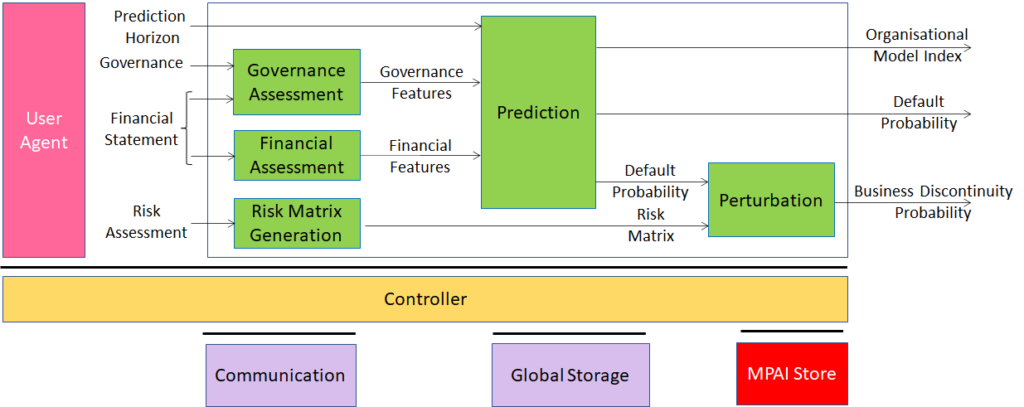
Figure 6 – The MPAI-CUI Company Performance Prediction Use Case
The set of specifications composing the MPAI-CUI standard is available here.
7 Governance of the MPAI Ecosystem (MPAI-GME)
Governance of the MPAI Ecosystem (MPAI-GME) is a foundational MPAI standard specifying the operation of the Ecosystem enabling:
- Implementers to develop components and solutions.
- Performance Assessors to assess the Performance of an Implementation.
- The MPAI Store to Test an Implementation for Conformance and post the Implementation to the MPAI Store website together with the results of Performance Assessment.
- End Users to download Implementations and report Experience Scores.
Figure 9 depicts the operation of the MPAI Ecosystem.
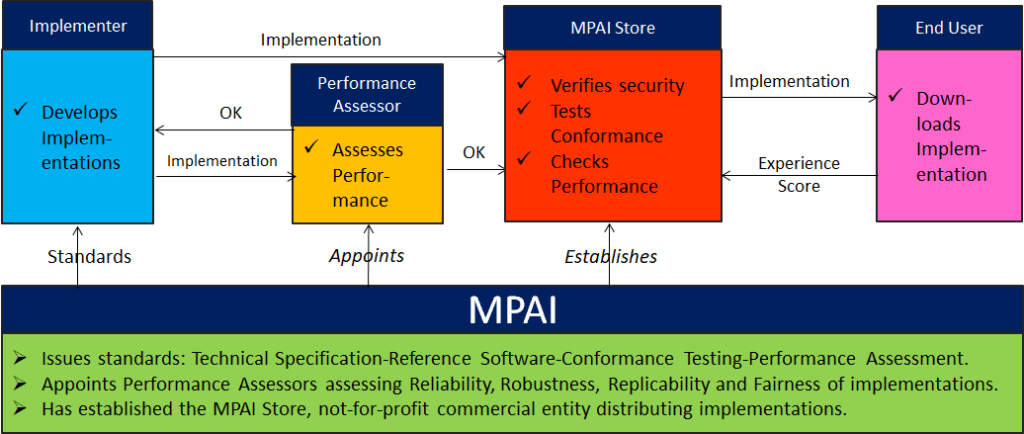
Figure 9 – Governance of the MPAI Ecosystem.
8 Multimodal Conversation (MPAI-MMC)
Multi-modal conversation (MPAI-MMC) aims to enable human-machine conversation that emulates human-human conversation in completeness and intensity by using AI. Its Use Cases are is an implementation of the MPAI “make available explainable AI applications” vision for human-machine conversation.
8.1 Version 1
Technical Specification: Multimodal Conversation (MPAI-MMC) V1 includes five Use Cases Conversation with emotion, Multimodal Question Answering (QA) and 3 Automatic Speech Translation.
Figure 10 depicts the Reference Model of the Conversation with Emotion Use Case.
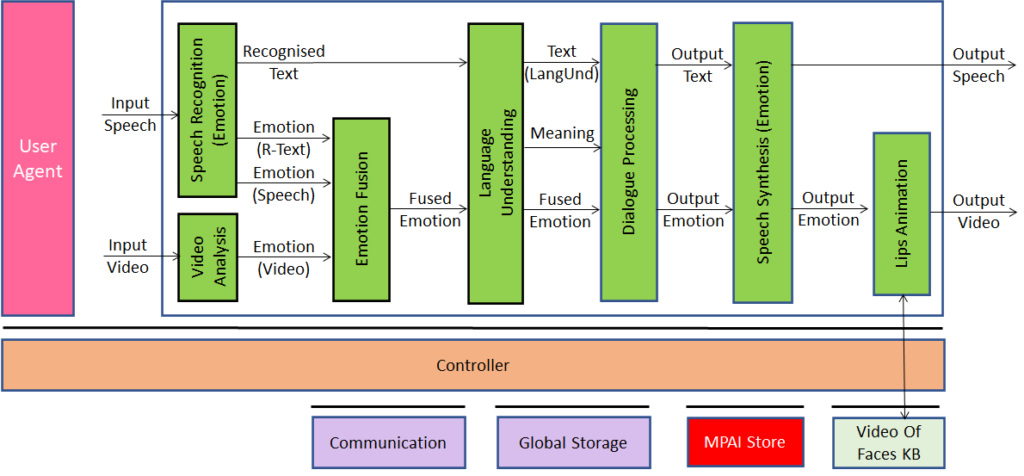
Figure 10 – An MPAI-MMC V1 Use Case: Conversation with Emotion
The MPAI-MMC Technical Specification V1.2 is available here.
8.2 Version 2
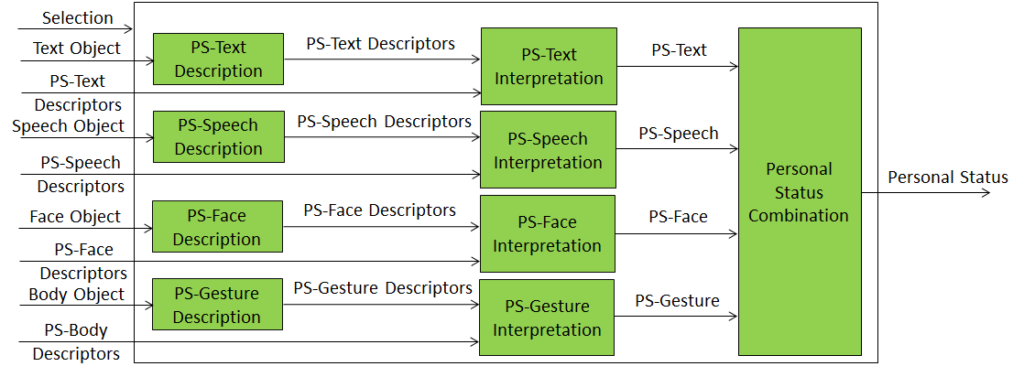
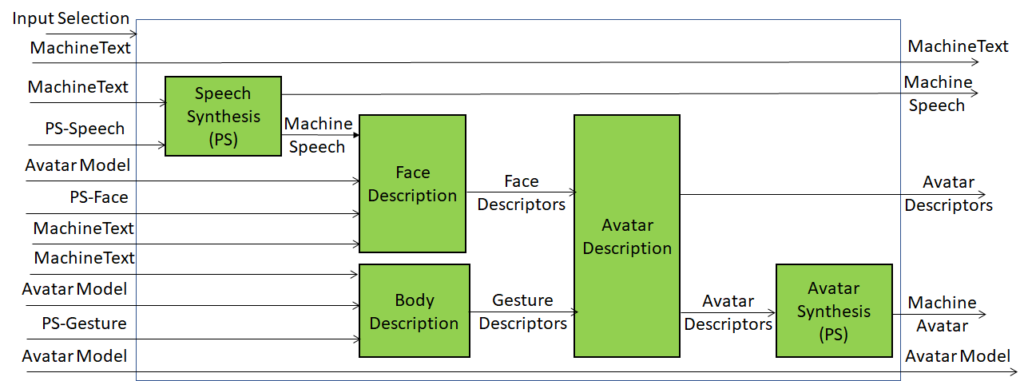
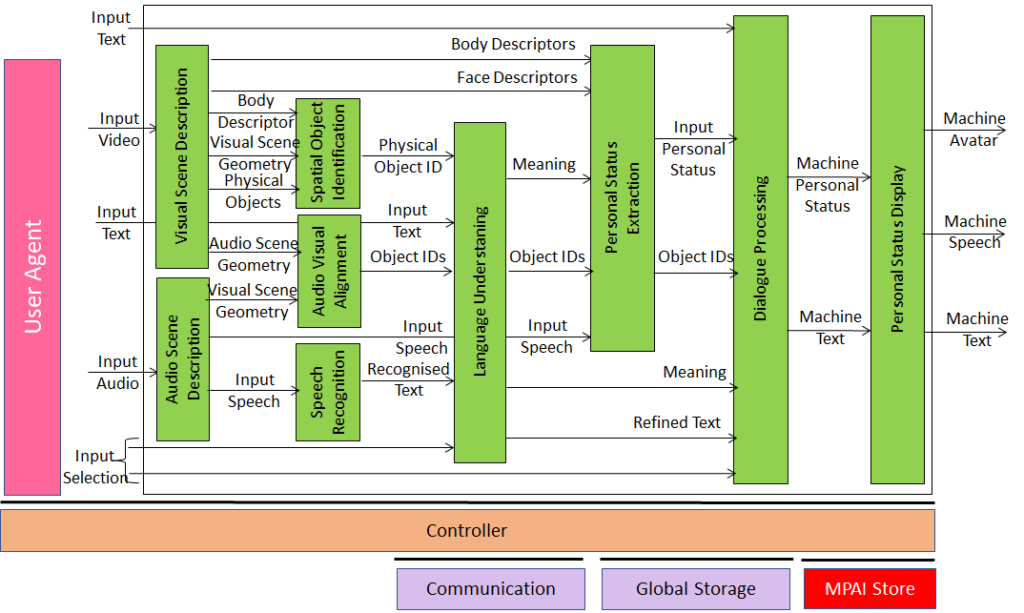
Extending the role of emotion as introduced in Version 1.2 of the standard, MPAI-MMC V2 introduces Personal Status, i.e., the internal status of humans that a machine needs to estimate and that it artificially creates for itself with the goal of improving its conversation with the human or even with another machine. Personal Status is applied to several new Multi-modal conversation V2 (MPAI-MMC V2) Use Cases: Conversation About a Scene, Virtual Secretary for Videoconference, and Human-Connected Autonomous Vehicle Interaction.
Figure 11 is the reference model of the Conversation About a Scene (CAS) Use Case.
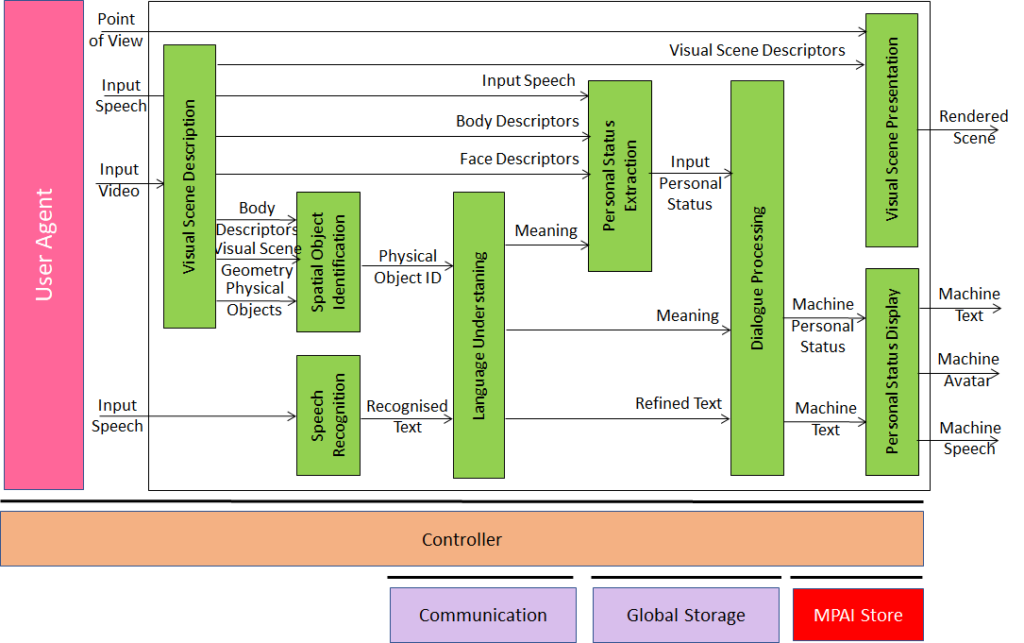
Figure 11 – An MPAI-MMC V2 Use Case: Conversation About a Scene
Figure 12 gives the Reference Model of a second use case: Virtual Secretary (used in the Avatar-Based Videoconference Use Case).
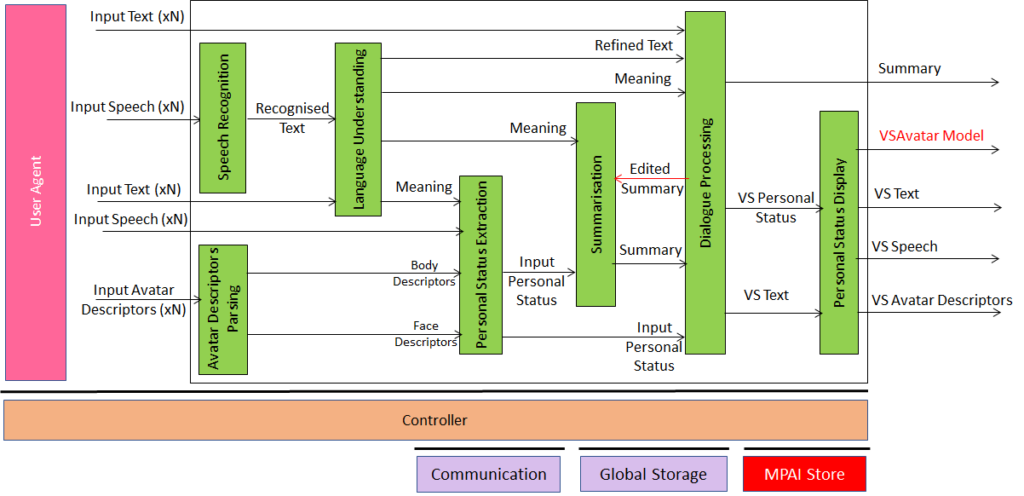
Figure 12 – Reference Model of Virtual Secretary for Videoconference
The MPAI-MMC Version 2 Working Draft (html, pdf) is published with a request for Community Comments and expected to be finally approved on 29 September 2023.
9 MPAI Metaverse Model – Architecture (MPAI-MMM)
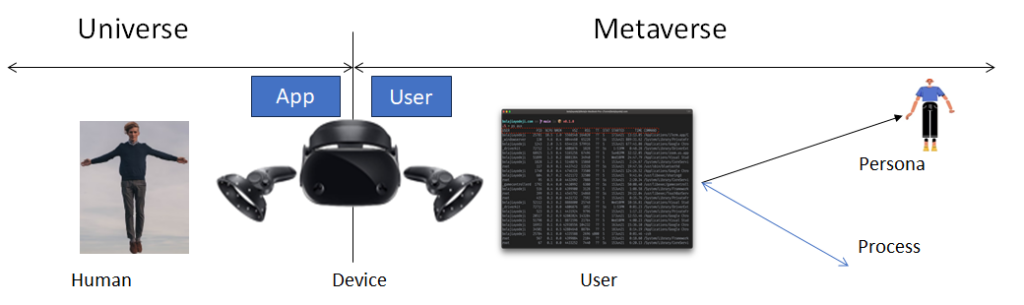
MPAI characterises the metaverse as a system that captures data from the real world, processes it, and combines it with internally generated data to create virtual environments that users can interact with.
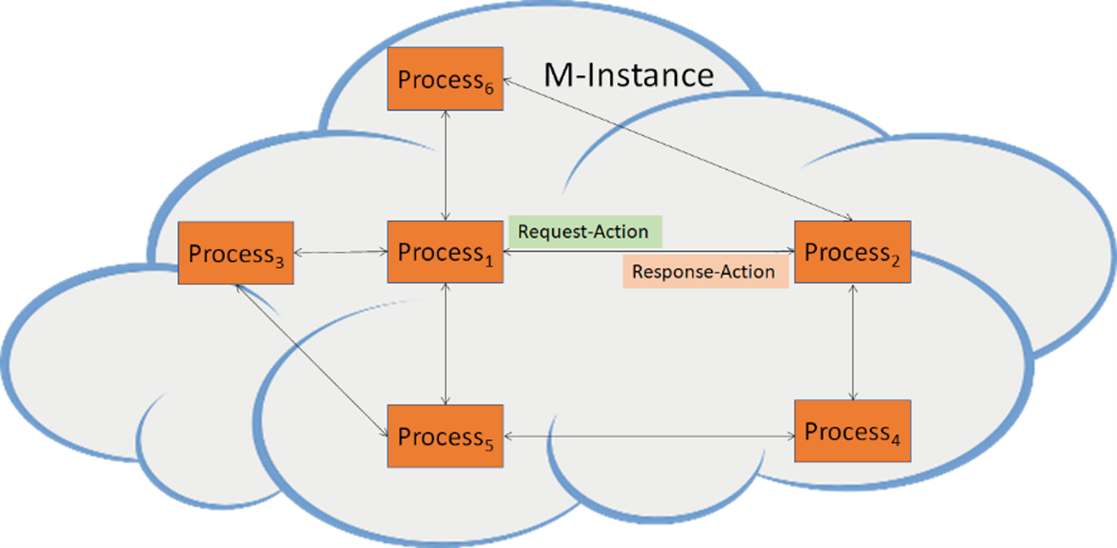
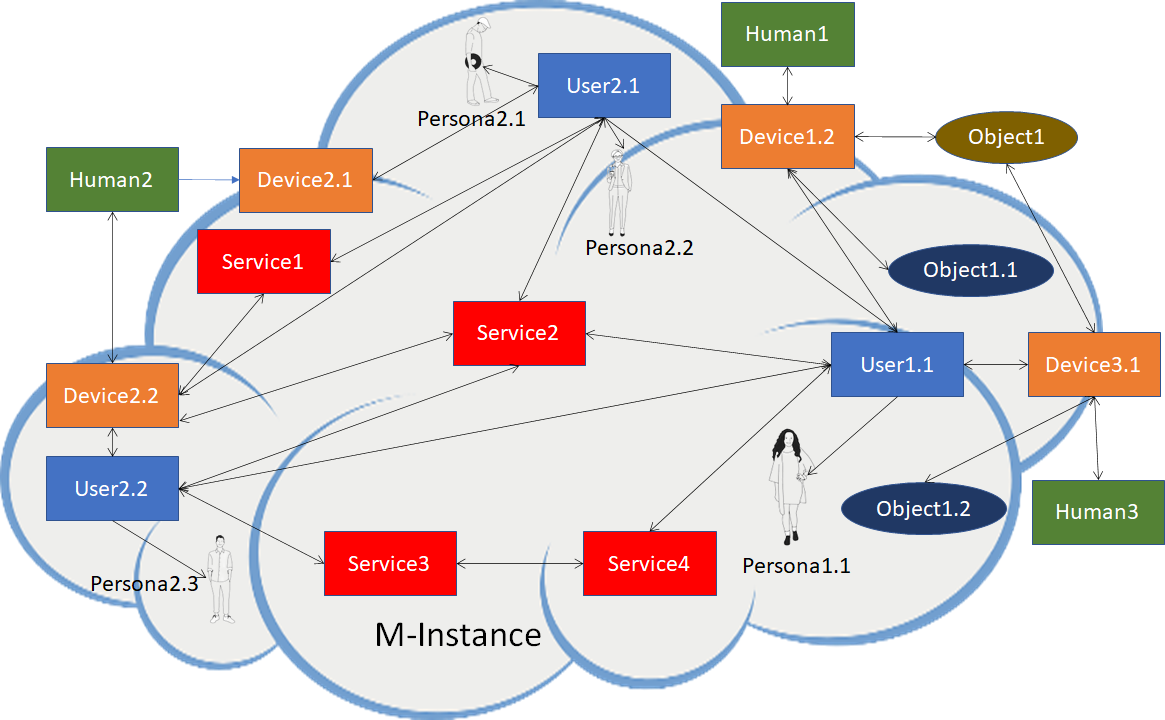
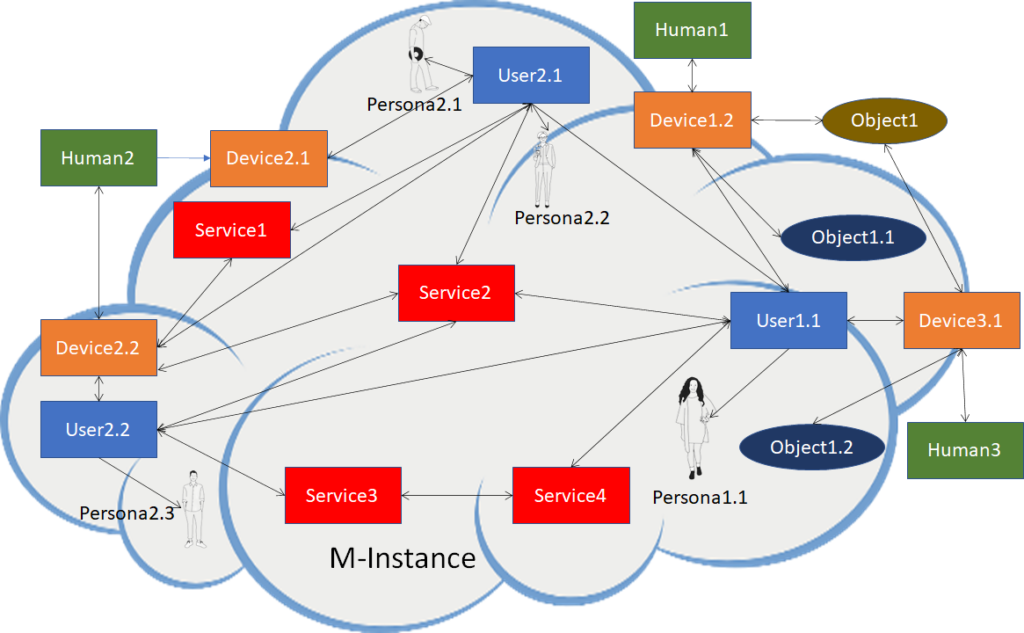
MPAI Metaverse Model (MMM) targets a series of Technical Reports and Specifications promoting Metaverse Interoperability. Two MPAI Technical Reports. on Metaverse Functionalities and Functionality Profiles, have laid down the groundwork. With the Technical Specification – MPAI Metaverse Model – Architecture, MPAI provides initial Interoperability tools by specifying the Functional Requirements of Processes, Items, Actions, and Data Types that allow two or more Metaverse Instances to Interoperate, possibly via a Conversion Service, if they implement the Technical Specification’s Operation Model and produce Data whose Format complies with the Specification’s Functional Requirements.
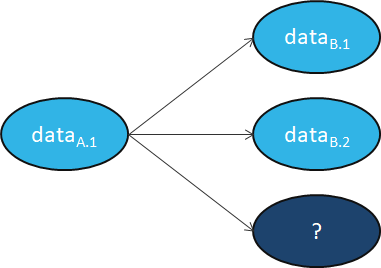
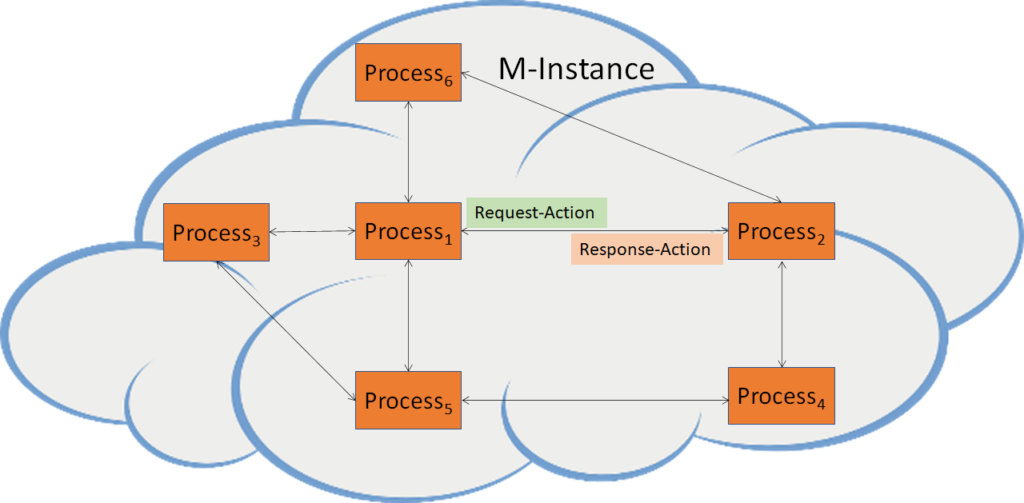
Figure 13 depicts one aspect of the Specification where a Process in a Metaverse Instance requests a Process in another Metaverse Instance to perform an Action by relying on the Instances’ Resolution Service.
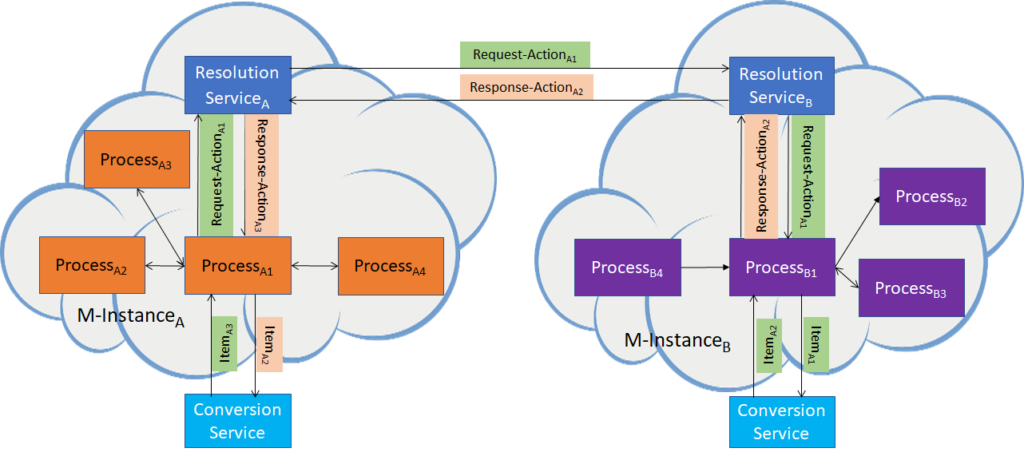
Figure 13 – Resolution and Conversion Services
The MPAI-MMM – Architecture Working Draft (html, pdf) is published with a request for Community Comments level and expected to be finally approved on 29 September 2023.
10 Neural Network Watermarking (MPAI-NNW)
Neural Network Watermarking is a standard whose purpose is to enable watermarking technology providers to qualify their products by providing the means to measure, for a given size of the watermarking payload, the ability of:
- The watermark inserter to inject a payload without deteriorating the NN performance.
- The watermark detector to recognise the presence of the inserted watermark when applied to:
- A watermarked network that has been modified (e.g., by transfer learning or pruning)
- An inference of the modified model.
- The watermark decoder to successfully retrieve the payload when applied to:
- A watermarked network that has been modified (e.g., by transfer learning or pruning)
- An inference of the modified model.
- The watermark inserter to inject a payload at a measured computational cost in a given processing environment.
- The watermark detector/decoder to detect/decode a payload from a watermarked model or from any of its inferences, at a measurable computational cost, e.g., execution time in a given processing environment.
Figure 14 depicts the configuration of one particular use of MPAI-NNW.
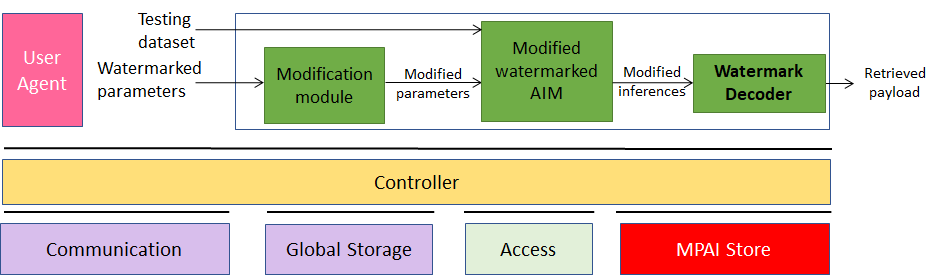
Figure 14 – Robustness evaluation of a Neural Network
The Neural Network Watermarking Technical Specification is available here.