<- References Go to ToC Environment Sensing Subsystem (ESS)–>
6.1 Functions of Human-CAV Interaction
The Human-CAV Interaction (HCI) Subsystem performs the following high-level functions:
- Authenticates humans e.g., for the purpose of letting them into the CAV.
- Interprets and executes commands provided by humans, possibly after a dialogue, e.g., to go to a Waypoint, issue commands such as turn off air conditioning, open window, call a person, search for information, etc.
- Displays Full Environment Representation to passengers via a viewer and allows passengers to control the display.
- Interprets conversation utterances with the support of the extracted Personal Statuses of the humans, e.g., on the fastest way to reach a Waypoint because of an emergency, or during a casual conversation.
- Displays itself as a Body and Face with a mouth uttering Speech showing a Personal Status comparable to the Personal Status that a human counterpart (e.g., driver, tour guide, interpreter) would display in similar circumstances.
The HCI operation is highly influenced by the notion of Personal Status, the set of internal characteristics of conversation humans and machines. See Annex 1 Section 1.
6.2 Reference Architecture of Human-CAV Interaction
Figure 3 gives the Human-CAV Interaction (HCI) Reference Model supporting the case of a group of humans approaching the CAV from outside the CAV and sitting inside the CAV.
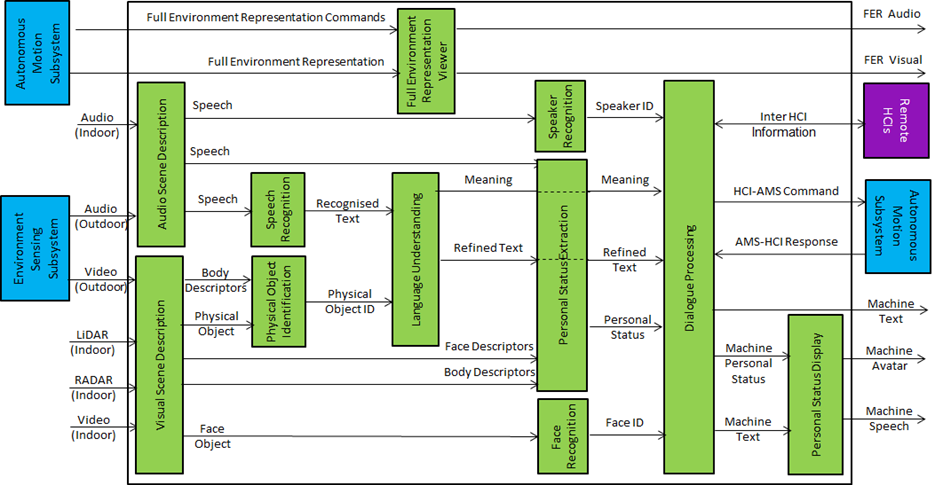
Figure 3 – Human-CAV Interaction Reference Model
The HCI operation is considered in two outdoor and indoor human-CAV interaction scenarios:
- When a group of humans approaches the CAV from outside the CAV:
- The Audio Scene Description AIM creates the Audio Scene Descriptions in the form of Audio (Speech) Objects corresponding to each speaking human in the Environment (close to the CAV).
- The Visual Scene Description creates the Visual Scene Description and provides 1) the Face Object and Physical Objects and 2) the Body and Face Descriptors corresponding to each human in the Environment (close to the CAV).
- The Speaker Recognition and Face Recognition AIMs authenticate the humans the HCI is interacting with. The processing of these two AIMs may be carried out remotely.
- The Speech Recognition AIM recognises the speech of each human.
- The Language Understanding AIM produces the Refined Text and extracts the Meaning.
- The Personal Status Extraction AIM extracts the Personal Status of the humans from 1) Speech, 2) Face and Body Descriptors, and 3) Meaning.
- The Dialogue Processing AIM:
- Validates the human Identities.
- Produces Machine Text in response to the Refined Text.
- Produces the HCI Personal Status.
- Displays the HCI Face and Body conveying the HCI Personal Status.
- Utters the HCI response.
- Issues commands to the Autonomous Motion Subsystem.
- Receives and processes responses from the Autonomous Motion Subsystem.
- When a group of humans sit inside the CAV:
- The Audio Scene Description AIM creates the Audio Scene Descriptions in the form of Audio (Speech) Objects corresponding to each speaking human in the cabin.
- The Visual Scene Description creates the Visual Scene Descriptors in the form of Face Descriptors and Gesture Descriptors corresponding to each human in the cabin.
- The Speaker Recognition and Face Recognition AIMs identify the humans the HCI is interacting with.
- The Speech Recognition AIM recognises the speech of each human.
- The Language Understanding AIM extracts the Meaning and produces the Refined Text.
- The Personal Status Extraction AIM extracts the Personal Status of the humans.
- The Dialogue Processing AIM performs the corresponding functions performed in the outdoor case.
Notes related to the two scenarios:
- HCI interacts with the humans sitting in the cabin in two ways:
- By responding to commands/queries from one or more humans at the same time, e.g.:
- Commands to go to or park at a Waypoint, etc.
- Commands with an effect on the cabin, e.g., turn off air conditioning, turn on the radio, call a person, open window or door, search for information etc.
- By conversing with and responding to questions from one or more humans at the same time about travel-related issues (in-depth domain-specific conversation), e.g.:
- Humans request information, e.g., time to destination, route conditions, weather at destination, etc.
- Humans ask questions about objects in the cabin or held by humans.
- CAV offers alternatives to humans, e.g., long but safe way, short but likely to have interruptions.
- By responding to commands/queries from one or more humans at the same time, e.g.:
- While in the cabin, passengers can become aware of the external Environment by issuing Full Environment Representation (FER) Commands to navigate the Full Environment Representation in a device.
6.3 I/O Data of Human-CAV Interaction
Table 3 gives the input/output data of the Human-CAV Interaction Subsystem.
Table 4 – I/O data of Human-CAV Interaction
| Input data | From | Comment |
| Full Environment Representation | Autonomous Motion Subsystem | Rendered by Full Environment Representation Viewers |
| Full Environment Representation Commands | Cabin Passengers | To control rendering of Full Environment Representation |
| Audio (ESS) | Environment Sensing Subsystem | User authentication
User command User conversation |
| Audio | Cabin Passengers | User’s social life
Commands/interaction with HCI |
| Video (ESS) | Environment Sensing Subsystem | Commands/interaction with HCI |
| Video | Cabin Passengers | User’s social life
Commands/interaction with HCI |
| RADAR | Cabin Passengers | User’s social life
Commands/interaction with HCI |
| LiDAR | Cabin Passengers | User’s social life
Commands/interaction with HCI |
| AMS-HCI Response | Autonomous Motion Subsystem | Response to HCI-AMS Command |
| Inter HCI Information | Remote HCI | HCI-to-HCI information |
| Output data | To | Comments |
| Full Environment Representation Audio | Passenger Cabin | For passengers to hear external Environment |
| Full Environment Representation Video | Passenger Cabin | For passengers to view external Environment |
| Inter HCI Information | Remote HCI | HCI-to-HCI information |
| HCI-AMS Command | Autonomous Motion Subsystem | HCI-to-AMS information |
| Machine Text | Cabin Passengers | HCI’s response to passengers |
| Machine Avatar | Cabin Passengers | HCI’s avatar when conversing |
| Machine Speech | Humans in Environment
Cabin Passengers |
HCI’s response to humans
HCI’s response to passengers |
6.4 Functions of the Human-CAV Interaction’s AI Modules
Table 4 gives the functions of all Environment Sensing Subsystem AIMs.
Table 5 – Functions of Human-CAV Interaction’s AI Modules
| AIM | Function |
| Audio Scene Description | Produces the Audio Scene Descriptors using the Audio captured by the appropriate (indoor or outdoor) Microphone Array. |
| Visual Scene Description | Produces the Visual Scene Descriptors using the visual information captured by the appropriate indoor visual sensors (Video, KADAR, and Lidar) or outdoor visual sensors. |
| Speech Recognition | Converts speech into Recognised Text. |
| Physical Object Identification | Provides the ID of the class of objects of which the Physical Object is an Instance |
| Full Environment Representation Viewer | Converts the Full Environment Representation produced by the Autonomous Motion Subsystem into Audio-Visual Scene Descriptors that can be perceptibly rendered by the Viewer. |
| Language Understanding | Refines the Recognised Text by using context information (e.g., Instance ID of object). |
| Speaker Recognition | Provides Speaker ID from Speech Object. |
| Personal Status Extraction | Provides the Personal Status of a passenger. |
| Face Recognition | Provides Face ID from Face Object. |
| Dialogue Processing | Provides:
1. Machine Text containing the HCI response to the human. 2. HCI Personal Status correlated with the HCI Text. |
| Personal Status Display | Produces Speech, and Machine Face and Body. |
6.5 I/O Data of Human-CAV Interaction’s AI Modules
Table 5 gives the input/output data of the Human-CAV Interaction AIMs.
Table 6 – I/O Data of Human-CAV Interaction’s AI Modules
| AIM | Input | Output |
| Audio Scene Description | Environment Audio (outdoor)
Environment Audio (indoor) |
Speech Objects |
| Visual Scene Description (outdoor) | Environment Video (outdoor)
|
Face Descriptors
Body Descriptors |
| Visual Scene Description (indoor) | Environment Video (indoor)
Environment LiDAR (indoor) |
Visual Scene Descriptors |
| Visual Scene Fusion (indoor) | Visual Scene Descriptors | Face Descriptors
Body Descriptors Physical Objects |
| Speech Recognition | Speech Object | Recognised Text |
| Physical Object Identification | Physical Object
Body Descriptors |
Physical Object ID |
| Full Environment Representation Viewer | FER Commands | FER Audio
FER Visual |
| Language Understanding | Recognised Text
Personal Status Physical Object ID |
Meaning
Personal Status Refined Text |
| Speaker Recognition | Speech Descriptors | Speaker ID |
| Personal Status Extraction | Recognised Text
Speech Object Face Object Human Object |
Personal Status |
| Face Recognition | Face Object | Face ID |
| Dialogue Processing | Speaker ID
Meaning Refined Text Personal Status Face ID AMS-HCI Response |
AMS-HCI Commands
Machine Text Machine Personal Status
|
| Personal Status Display | Machine Text
Machine Personal Status |
Machine Text
Machine Avatar Machine Speech |
<- References Go to ToC Environment Sensing Subsystem (ESS)–>
© Copyright MPAI 2022-23. All rights reserved