| 1 Functions | 2 Reference Model | 3 I/O Data |
| 4 Functions of AI Modules | 5 I/O Data of AI Modules | 6 AIW, AIMs, and JSON Metadata |
| 7 Reference Software | 8 Conformance Testing | 9 Performance Assessment |
1 Functions
The Television Media Analysis (OSD-TMA) AI Workflow produces Audio-Visual Event Descriptors (OSD-AVE) composed of a set of Audio-Visual Scene Descriptors (AVS) that include
- Relevant Audio, Visual, or Audio-Visual Object
- IDs of speakers and ID of faces with their spatial positions
- Text from utterances
of a television program provided as input together with textual information that OSD-TMA may use to improve its performance.
OSD-TMA assumes that there is only one speaker at a time.
2 Reference Model
Figure 1 depicts the Reference Model of TV Media Analysis.
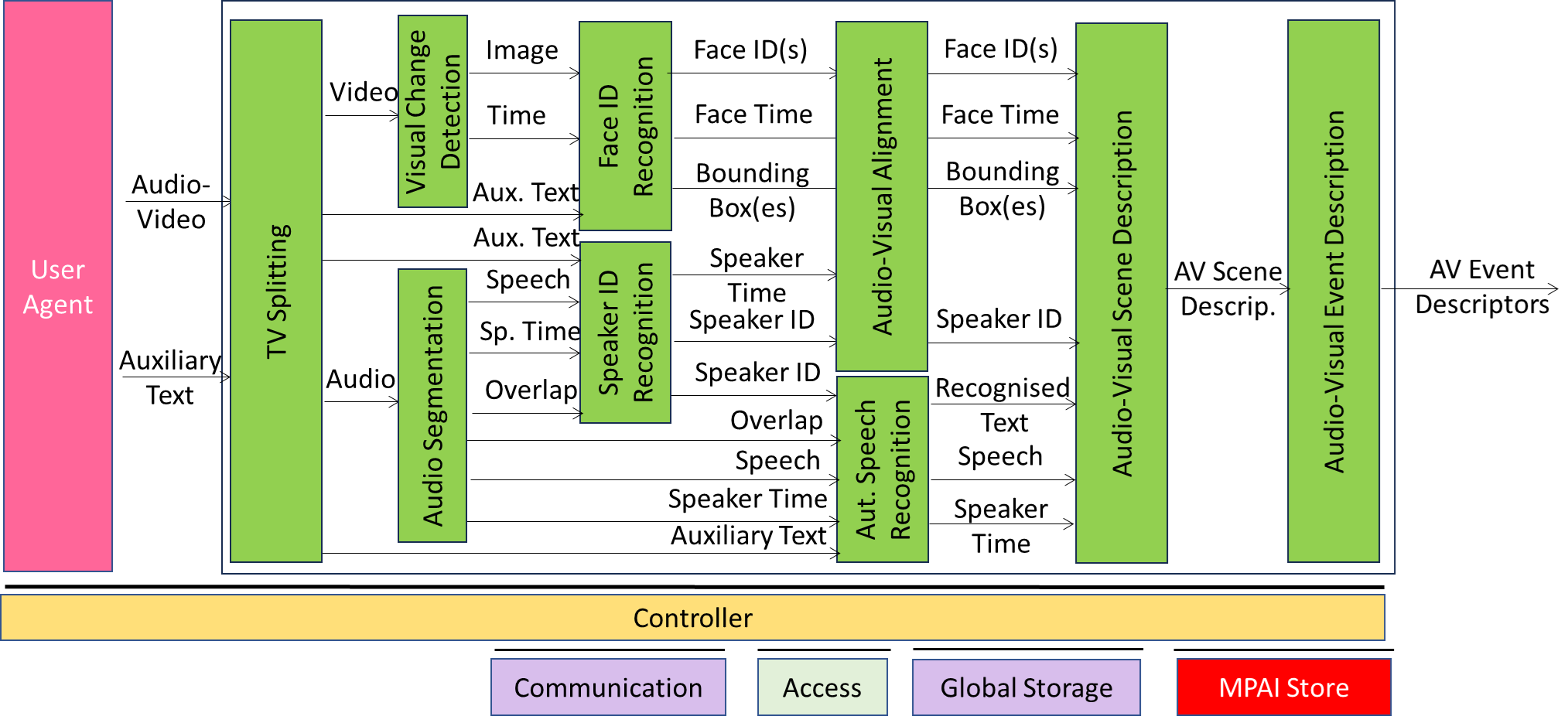
Figure 1 – Reference Model of OSD-TMA
3 Input/Output Data
Table 1 provides the input and output data of the TV Media Analysis Use Case:
Table 1 – I/O Data of Conversation with Personal Status
| Input | Descriptions |
| Audio-Video | Audio-Video to be analysed. |
| Text | Text helping OSD-TMA AIMs to improve their performance. |
| Output | Descriptions |
| Audio-Visual Event Descriptors | Resulting analysis of Input Audio-Video-Text. |
4 Functions of AI Modules
Table 2 provides the functions of the TV Media Analysis Use Case. Note that processing proceeds asynchronously, e.g., TV Splitter separates audio and video for the entire duration of the file and passes the entire audio and video files.
Table 2 – Functions of AI Modules of Conversation with Personal Status
| AIM | Function |
| TelevisionSplitting | Receives Audio-Visual File composed of: – An Audio-Video component. – A Text component. Produces – Video file – Audio file – Text file When all the files of the full duration of the video are ready, AV Splitter informs the following AIMs. |
| VisualChangeDetection | Receives Video file. Iteratively: – Looks for a video frame that conveys a scene changed from the preceding scene (depends on threshold). – Assigns a video clip identifier to the video clip. – Produces a set of images with StartTime and EndTime. |
| AudioSegmentation | Receives Audio file. Iteratively: – For each audio segment (from one change to the next): – Becomes aware that there is speech. – Assigns a speech segment ID and anonymous speaker ID (i.e., the identity is unknown) to the segment. – Decides whether: – The existing speaker has stopped. – A new speaker has started a speech segment. – If a speaker has started a speech: – Assigns a new speech segment ID. – Check whether the speaker is new or old in the session. – If old retain old anonymous speaker ID. – If new assign a new anonymous speaker ID. – Produces a series of audio sequences each of which contains: – A speech segment. – Start and end time. – Anonymous Speaker ID. – Overlap information |
| Face Identity Recognition | – Receives a Text file. – Extracts semantic information from the Text file. – Receives a set of images per video clip. – For each image identifies the bounding boxes. – Extracts faces from the bounding boxes. – Extracts the embeddings that represent a face. – Compares the embeddings with those stored in the face recognition data base. – Associates the embeddings with a face ID taking into account the semantic information from the Text. |
| Speaker Identity Recognition | 1. Receives a Text file. 2. Extracts semantic information from the Text file. 3. Receives a Speech Object and Speech Overlap information. 4. Extracts the embeddings that represent the speech segment. 5. Compares the embeddings with those stored in the speaker recognition data base. 6. Associates the embeddings with a Speaker ID taking into account the semantic information from the Text. |
| Audio-Visual Alignment | Receives: – Face ID – Bounding Box – Face Time – Speaker ID – Speaker Time Associates Speaker ID and Face ID |
| Automatic Speech Recognition | – Receives a Text file. – Extracts semantic information from the Text file. – Receives a Speech Object. – Produces the transcription of the speech payload taking into account the semantic information from the Text. – Attaches time stamps to specific portions of the transcription. |
| Audio-Visual Scene Description | Receives – Bounding box coordinates, Face ID, and time stamps – Speaker ID and time stamps. – Reconciles Face ID and Speaker ID. – Text and time stamps Produces Audio-Visual Scene Descriptors |
| Audio-Visual Event Description | Receives Audio-Visual Scene Descriptors Produces Audio-Visual Event Descriptors |
5 I/O Data of AI Modules
Table 3 provides the I/O Data of the AI Modules of the TV Media Analysis Use Case.
Table 3 – I/O Data of AI Modules of Television Media Analysis
| AIM | Receives | Produces |
| TelevisionSplitting | Audio – Video – AuxiliaryText |
– Audio – Video – AuxiliaryText |
| VisualChangeDetection | – Video | – Image |
| AudioSegmentation | – Speech | – SpeechObjects – SpeechOverlap |
| Face Identity Recognition | – Image – Time – AuxiliaryText |
VisualSceneDescriptors with: – FaceID – FaceTime – BoundingBox |
| Speaker Identity Recognition | – SpeechObject – SpeakerTime |
– SpeechSceneDescriptors: with: – Speaker ID – SpeakerTime |
| Audio-Visual Alignment | – SpeechOverlap – SpeechObject – SpeakerTime – AuxiliaryText |
– Recognised Text – SpeechObject – SpeakerTime |
| Automatic Speech Recognition | – SpeechSceneDescriptors – VisualSceneDescriptors |
– AVSceneDescriptor with: – AlignedFaceID – BoundingBox |
| Audio-Visual Scene Description | – BoundingBox – AlignedFaceID – SceneTime – SpeakerID – RecognisedText |
– AVSceneDescriptors |
| Audio-Visual Event Description | – AVSceneDescriptors: | – AVEventDescriptors |
6 AIW, AIMs, and JSON Metadata
Table 4 – AIW, AIMs, and JSON Metadata
| AIW | AIM | Name | JSON |
| OSD-TMA | Television Media Analysis | X | |
| MMC-AUS | Audio Segmentation | X | |
| OSD-AVA | Audio-Visual Alignment | X | |
| OSD-AVE | Audio-Visual Event Description | X | |
| OSD-AVS | Audio-Visual Scene Description | X | |
| MMC-ASR | Automatic Speech Recognition | X | |
| PAF-FIR | Face Identity Recognition | X | |
| MMC-SIR | Speaker Identity Recognition | X | |
| OSD-TVS | Television Splitting | X | |
| OSD-VCD | Visual Change Detection | X |
7 Reference Software
7.1 Disclaimers
- This OSD-TMA Reference Software Implementation is released with the BSD-3-Clause licence.
- The purpose of this Reference Software is to provide a working Implementation of OSD-TMA, not to provide a ready-to-use product.
- MPAI disclaims the suitability of the Software for any other purposes and does not guarantee that it is secure.
- Use of this Reference Software may require acceptance of licences from the respective repositories. Users shall verify that they have the right to use any third-party software required by this Reference Software.
7.2 Guide to the OSD-TMA code
The OSD-TMA Reference Software:
- Receives any input Audio-Visual file that can be demultiplexed by FFMPEG.
- Uses FFMPEG to extract:
- A WAV file (uncompressed audio).
- A video file.
- Produces descriptors of the input Audio-Visual file represented by Audio-Visual Event Descriptors.
The current OSD-TMA implementation does not support Auxiliary Text.
The OSD-TMA uses the following software components:
- RabbitMQ is an MPAI-AIF function but is adapted for use in OSD-TMA. This service starts, stops and removes all OSD-TMA AIMs automatically using Docker in Docker (DinD): the controller lets only one dockerized OSD-TMA AIM run at any time, which saves computing resources. Docker is used to automate the deployment of all OSD-TMA AIMs so that they can run in different environments.
- Portainer is a service that helps manage Docker containers, images, volumes, networks and stacks using a Graphical User Interface (GUI). Here it is mainly used to manage two containerized services: RabbitMQ and Controller
- Docker Compose has a yml file to build and run all OSD-TMA AIMs and the Module for the Controller
- Controller builds the Docker images of all OSD-TMA AIMs and of the Controller by reading a YAML file called compose.yml. Docker Compose helps run RabbitMQ and Controller as Docker containers.
- Python code manages the MPAI-AIF operation but is adapted for use in OSD-TMA.
The OSD-TMA software includes compose.yml and controller. They can be found at https://experts.mpai.community/software/mpai-aif/osd_tma/orchestrator. compose.yml starts RabbitMQ, nor Portainer. https://docs.portainer.io/start/install-ce describes how to install Portainer.
The OSD-TMA code includes compose.yml and the code for the Controller.
compose.yml starts RabbitMQ, not Portainer. Portainer installation is described.
The OSD-TMA code is released with a demo. Recorded demo: The saved JSON of OSD-AVE.
The OSD-TMA Reference Software has been developed by the MPAI AI Framework Development Committee (AIF-DC), in particular, Francesco Gallo (EURIX) and Mattia Bergagio (EURIX) for developing this software.
The implementation includes the AI Modules as in the following table. AIMs in red required a GPU for high performance. However, the software can also operate without GPU.
| AIM | Name | Library | Dataset |
| MMC-ASR | Speech recognition | whisper-timestamped | Labeled Faces in the Wild |
| MMC-SIR | Speaker identification | SpeechBrain | VoxCeleb1 |
| MMC-AUS | Audio segmentation | pyannote.audio | |
| OSD-AVE | Event descriptors | ||
| OSD-AVS | Scene descriptors | ||
| OSD-TVS | TV splitting | ffmpeg | |
| OSD-VCD | Visual change | PySceneDetect | |
| PAF-FIR | Face recognition | DeepFace |
RabbitMQ
RabbitMQ is an open-source message broker that implements AMQP (Advanced Message Queuing Protocol). It enables asynchronous communication among the modules, allows them to be decoupled and improves the scalability and resilience of the system.
RabbitMQ provides a number of key features:
- Asynchronous messaging: RabbitMQ supports asynchronous messaging, which decouples senders from receivers and allows applications to communicate in a non-blocking manner.
- Queue management: RabbitMQ implements message queuing, which helps distribute messages among consumers.
- Reliability: RabbitMQ provides mechanisms to ensure message reliability, such as delivery acknowledgement and message persistence.
- Flexible routing: RabbitMQ supports different types of exchanges for message routing, so messages can be routed according to various criteria.
- Clustering: RabbitMQ supports clustering, which allows multiple RabbitMQ servers to be grouped into a single logical broker, thereby improving reliability and availability. RabbitMQ is usable in a wide range of applications, from simple data transfer among processes to more complex messaging patterns such as publish/subscribe and work queues.
Example of queues:
Portainer
Portainer is an open-source user interface that streamlines the management of Docker containers. It allows you to manage Docker containers, images, stacks, networks and volumes from a web interface; no need for a command-line interface. You can use Portainer to perform tasks such as building images, adding containers or stacks, and monitoring resource usage.
Example of containers in one of our stacks:
You can build and start all modules by running
docker compose –env-file .env -f compose.yml up
compose.yml is in repo.
.env lists the environment variables below:
TAG=0.1
LOG_LEVEL: log level. Can be CRITICAL, ERROR, WARNING, INFO, DEBUG, or NOTSET
PATH_SHARED: path of storage on disk
AI_FW_DIR: path of storage in container
HUGGINGFACE_TOKEN: HuggingFace token. Used by MMC-AUS
GIT_NAME: Git username
GIT_TOKEN: Git token
MIDDLEWARE_USER: RabbitMQ username
MIDDLEWARE_PASSWORD: RabbitMQ password
MIDDLEWARE_PORT: RabbitMQ port
MIDDLEWARE_EXTERNAL_PORT: outer RabbitMQ port
MIDDLEWARE_VIRTUALHOST: RabbitMQ virtual host. Default: MIDDLEWARE_VIRTUALHOST=/
EXCHANGE_NAME: RabbitMQ exchange name
To start module x run
docker compose –env-file .env -f compose.yml up controller rabbitmq_dc x
Send a suitable payload to the queue of module x, as shown for the controller here:
Controller
The controller is the module that orchestrates the workflow. It sends a message to the right module for processing.
The controller receives the input message from queue queue_module_controller. Then, the controller sends a tweaked message to OSD-TVS. This message contains the input message. OSD-TVS sends its output message to the controller, which sends a tweaked output message to MMC-AUS.
Modules are called in this order:
- OSD-TVS
- MMC-AUS
- OSD-VCD
- MMC-SIR
- MMC-ASR
- PAF-FIR
- OSD-AVA
- OSD-AVS
- OSD-AVE.
Examples/README.md
examples/README.md details how to run examples are here.
7.3 Acknowledgements
This version of the OSD-TMA Reference Software has been developed by the MPAI AI Framework Development Committee (AIF-DC).