Figure 1 depicts the internal architecture of the Live Theatrical Performance system.
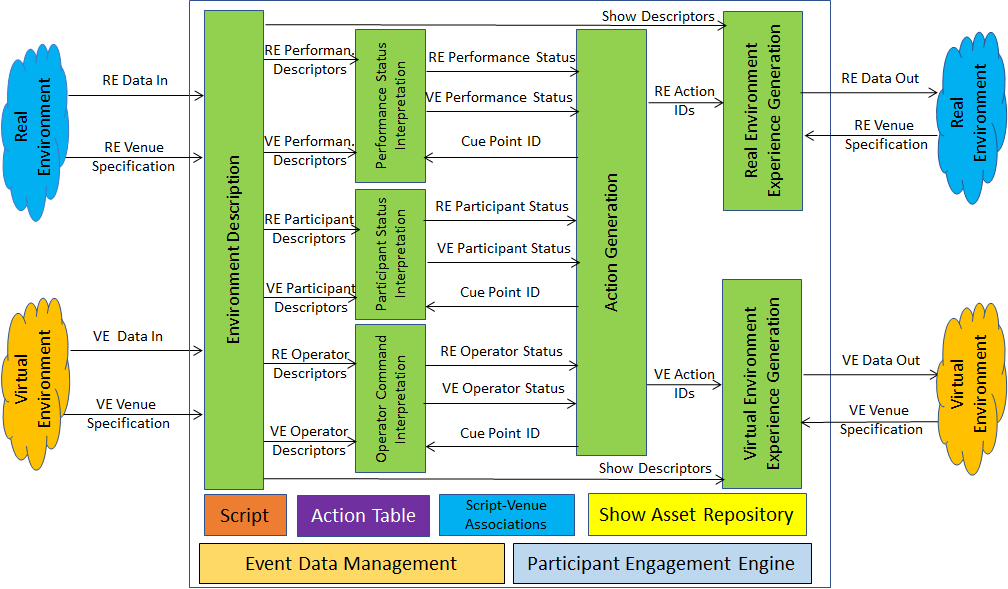
Figure 1 – The Live Theatrical Performance system
Data from both the Real and Virtual Environments (called Data In) of a Live Theatrical Performance specified by XRV-LTP include audio, video, volumetric or motion capture (MoCap), and avatar data from performers, participants, operators, signals from control surfaces and more as defined by the Real Venue (RE)/Virtual Venue (VE) Specifications that describe the technology choices and configurations (e.g., data format as specified by MPAI-TFA) made by a particular Venue.
This Input Data is processed and converted into RE (Real Environment, i.e., the theatre) and VE (Virtual Environment, i.e., the metaverse) Performance, Participant, and Operator Descriptors that are fed into the Performance and Participant Status Interpretation and the Operator Command Interpretation AIMs.
The show execution is guided by a Script, which includes a Cue List. Each Cue has multiple groups each with an associated set of Cue Conditions, Actions to be executed and the next Cue to branch to when those Conditions are met.
When a performance starts the Cues are executed in sequential order. The current Cue is referred to as the Cue Point. When the current Cue Conditions within a given group are satisfied, its associated Actions are executed, and the Cue Point branches to the next Cue. For each Cue ID there can exist multiple groups of Cue Conditions, their associated Actions, and the next Cue. The Action Generation AIM sends the new Cue Point ID to the three Interpretation AIMs.
When the specific Cue Point Conditions (RE or VE) have been met, the Action Generation AIM outputs the set of RE and VE Action IDs associated with that Cue. The set of Action IDs for a specific Cue Point references the Action List which includes, for each Action ID, an associated natural language semantic as it appears in the Script and a set of associated Action Commands.
The Action Table is built during the Show Programming Phase by an automatic or manual process wherein commands required to achieve a desired Action in the Venue per the Script are entered into the Table with an assigned Action ID and associated mnemonic. The Real or Virtual Venue Specifications include 3D Model Scenes that are Annotated with the full Venue-specific Command set for each object to be commanded.
The RE and VE Experience Generation AIMs produce RE and VE Data Out that include Action Commands from the Action Table and Data from the Show Descriptors required by the Real and Virtual Environments – according to the respective Venue Specifications – to provide multisensory experiences in both Venues.